🎡 使用 LLM 创建合成数据和注释#
LLM 的用途广泛,可用于许多不同的任务。除了酷炫的聊天互动之外,LLM 还可以成为创建合成数据和为尚无数据的标注任务提供初始建议的强大工具。 这样,任何人都可以轻松地开始启动项目。
在此示例中,我们将演示如何使用不同的 LLM 工具,例如 openai、 transformers、 langchain 和 outlines,来创建合成数据,并且我们可以利用这些相同的 LLM 来提供初始注释或建议。
如果您想要更基础的关于使用 ArgillaCallbackHandler 为 langchain 生成合成数据的介绍,您可以查看本实用指南。
警告
请记住,LLM 具有许可证,并非每个 LLM 都可以在所有操作环境中使用以创建合成数据。在使用 LLM 创建合成数据之前,请检查您正在使用的 LLM 的许可证。
让我们开始吧!
注意
本教程是一个 Jupyter Notebook。 有两种运行方式:
使用此页面顶部的“在 Colab 中打开”按钮。 此选项允许您直接在 Google Colab 上运行 notebook。 不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。 此选项允许您下载 notebook 并在本地计算机或您选择的 Jupyter notebook 工具上运行它。
设置#
对于本教程,您将需要运行 Argilla 服务器。 如果您还没有服务器,请查看我们的快速入门或安装页面。 完成后,请完成以下步骤:
使用
pip安装 Argilla 客户端和所需的第三方库
[ ]:
!pip install argilla openai langchain outlines tiktoken transformers ipywidgets jupyter
让我们进行必要的导入
[13]:
import argilla as rg
import os
import random
from langchain import OpenAI, PromptTemplate, LLMChain
from langchain.output_parsers import CommaSeparatedListOutputParser
from outlines import models, text
from outlines.text import generate
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用
URL和API_KEY初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
我们还需要通过创建 API 密钥并定义
OPENAI_API_KEY环境变量来设置您的 OpenAI API 凭据。
启用遥测#
我们从您与我们的教程互动的方式中获得宝贵的见解。 为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。 虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。 有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
定义 FeedbackDataset#
在本示例中,我们将为银行客户服务场景创建一个合成数据集。 我们假设客户将编写 text 请求。 然后应该对这些请求进行 sentiment 和 topics 分类。 topics 将是多标签分类,可用于将请求路由到正确的部门。 sentiment 将使用单标签分类来确定请求是否需要优先处理。
[33]:
sentiment = ["positive", "neutral", "negative"]
topic = ["new_card", "mortgage", "application", "payments"]
dataset = rg.FeedbackDataset(
fields = [rg.TextField(name="text")],
questions = [
rg.LabelQuestion(
name="sentiment",
title="What is the sentiment of the message?",
labels=sentiment
),
rg.MultiLabelQuestion(
name="topics",
title="Select the topic(s) of the message?",
labels=topic,
visible_labels=4
)
],
guidelines=(
"This dataset contains messages from a bank's customer support chatbot. "
"The goal is to label the sentiment and topics of the messages."
)
)
创建合成数据#
我们将使用 LLM 为 NLP 任务的每个步骤生成合成数据。 首先,我们将为银行创建来自客户的 text 请求。 接下来,我们将为 LabelQuestion 创建输入,以评估请求的情感,最后,我们将为 MultiLabelQuestion 创建输入,以对请求进行分类。
我们将使用 OpenAI 模型结合 LangChain 和开源的基于 transformer 的模型结合 Outlines 包来完成此操作。
| LangChain 框架是 LLM 模型的包装器,可以更轻松地实现数据感知和基于代理的 LLM 模型。
| Outlines 是一个 Python 库,用于在与生成模型交互期间编写可靠的条件生成程序。
注意
提示工程的过程是一个反复试验的过程。 某处的更改可能会导致语言链中另一处产生不良影响。 以下示例只是一个起点,可以通过尝试不同的提示和模板来改进。
初始化生成模型#
LangChain 与 OpenAI#
对于 LangChain 的使用,您需要将 OPENAI_API_KEY 环境变量传递给 OpenAI 类。 您可以使用 os 包来执行此操作。 然后,model 变量即可在以下示例中使用。
[8]:
os.environ["OPENAI_API_KEY"] = "sk-..."
openai_model = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
Outlines 与 Transformers#
即使 Outlines 为 OpenAI 提供了一些支持,我们也将在此示例中使用基本的 transformers。 您可以使用 HuggingFace 模型中心 中的任何生成模型,方法是将模型的名称传递给 transformers 函数。 然后,model 变量即可在以下示例中使用。
[4]:
transformer_model = models.transformers("gpt2")
TextField#
为了创建评论,我们依赖于基于提示的自由文本生成。 这对于我们创建合成数据集以及尽可能简化流程的目的来说应该足够好。
LangChain#
OpenAI 模型已经过指令微调,因此可以通过 LangChain 用于生成合成数据。 这是使用 PrompTemplate 完成的,该模板从传递给 predict() 方法的 topic 和 sentiment 变量中推断信息。
[35]:
template = (
"Write a customer review for a bank. "
"Do that for topic of {topic}. "
"Do that with one a {sentiment} sentiment."
)
prompt = PromptTemplate(template=template, input_variables=["topic", "sentiment"])
llm_chain_review = LLMChain(prompt=prompt, llm=openai_model)
def generate_langchain_review():
return llm_chain_review.predict(
topic=random.choice(topic),
sentiment=random.choice(sentiment)
).strip()
generate_langchain_review()
[35]:
'I recently had the pleasure of working with the mortgage team at this bank, and I can confidently say that their level of service and expertise was second to none. They answered all of my questions quickly and took the time to explain the process to me in detail. I felt like they genuinely had my best interests at heart and they made the process of obtaining a mortgage as smooth and stress-free as possible. I would highly recommend this bank for anyone looking to take out a mortgage.'
我们现在将创建一个可以生成 n 个随机示例来评估性能的函数。 正如我们对最新一代 OpenAI 模型所期望的那样,结果看起来不错,并且似乎足够多样化,可以用作合成数据。
[38]:
def generate_n_langchain_reviews(n=2):
reviews = []
for n in range(n):
reviews.append(generate_langchain_review())
return reviews
langchain_reviews = generate_n_langchain_reviews()
langchain_reviews
[38]:
["I've been a customer of this bank for over 5 years, and I've been completely satisfied with their payment services. The online payment system is easy to use and the customer service team is always quick to respond to any questions I have. I never have to worry about my payments being delayed or lost, which is always reassuring. Highly recommend this bank for anyone looking for reliable payment services!",
"I recently secured a mortgage with this bank and was so impressed with the level of service I received. From the start, the staff was friendly, knowledgeable, and willing to go above and beyond to get me the best deal. The process was straightforward and the paperwork was easy to understand. I'm thrilled with my new mortgage and would highly recommend this bank to anyone looking for a mortgage."]
Outlines#
并非所有生成模型都像现代 LLM 那样经过指令微调且有用。 因此,请考虑到这应该反映在您的 prompt 和生成的文本的预期质量中。
[35]:
@text.prompt
def generator(topic, sentiment):
"""
The customer service for {{ topic }} of the bank is {{ sentiment }} because
"""
def generate_outlines_review():
prompt = generator(random.choice(topic), random.choice(sentiment))
answer = text.generate.continuation(transformer_model, max_tokens=100)(prompt)
answer = "Because"+ answer
return answer
generate_outlines_review()
[35]:
"Because of technical questions and consumer protection. Telephone orders are not placed in the bank's database because where homeowners need to know that their bank is registered here, this protection providing a system to check their record is not protected by even their own state laws, which is why I don't believe criminal laws should be used to enforce the bank ATM login, nor should neutral other town or guild banking providers be regulated. These accountants have followed the local law explanations, and they do not deserve criminal sanction for allowing a"
我们现在将创建一个可以生成 n 个随机示例的函数。 查看示例,该模型似乎生成了大致相关的文本,但总的来说,质量较差。 因此,建议使用另一种类型的模型,该模型可能经过指令微调以确保更高的生成质量。 此外,Outlines 提供了对生成过程的更多动态控制,这也可以用于提高生成文本的质量。
[53]:
def generate_n_outlines_reviews(n=2):
reviews = []
for n in range(n):
reviews.append(generate_outlines_review())
return reviews
outlines_reviews = generate_n_outlines_reviews()
outlines_reviews
[53]:
['Because of damaged card and adds some other attachments from other data on the ToS or database file."',
'Because of jurisdictional issues," said the FTC\'s executive director, Paul R. Matthewi. "Technology seems to be without limits in the fraud marketplace as we moved toward a new way of remote law enforcement and convenience."\n\nIt is unclear, however, how people will get paid—or how many will be affected. In TekSavvy, which relies on similar technology many consumer goods companies rely on to keep their customers healthy, some of America\'s top credit card holders appear to still need money,']
LabelQuestion#
在此步骤中,我们将重用从 langchain_reviews 和 outlines_reviews 生成的评论,并使用各自的框架标记它们的情感。 这将通过假设从上面定义的 sentiment 列表中的两个列表中返回 str 来完成。
LangChain#
我们正在使用类似 jinja 的 template,这要求我们将基本 prompt 定义为 LangChain 的 input_variable。 对于初始示例,我们使用演示。
[24]:
template = (
f'Choose from the sentiments: {sentiment}. '
'Return a single sentiment.'
'{prompt}'
)
prompt = PromptTemplate(template=template, input_variables=["prompt"])
llm_chain_sentiment = LLMChain(prompt=prompt, llm=openai_model)
def get_sentiment_from_langchain(text: str) -> str:
return llm_chain_sentiment.predict(prompt=text).strip().lower()
get_sentiment_from_langchain("I love langchain and openai for sentiment labelling.")
[24]:
'positive'
我们获得了生成的 langchain_reviews 的情感标签。 我们可以看到情感标签并非总是正确,但它们大部分是正确的。 这是因为 LLM 并非完美,但它们足够好,可以用于合成数据生成,并为人工注释员提供建议。
[46]:
langchain_sentiment = [get_sentiment_from_langchain(reviews) for reviews in langchain_reviews]
langchain_sentiment
[46]:
['positive', 'positive']
Outlines#
Outlines 为使用生成式模型进行引导式标注提供了开箱即用的实现,但是在某些情况下,可以使用 来自 HuggingFace 库的(零样本)分类模型,为标注过程中的提供建议提供良好的起点。 查看我们的SetFit 示例。
[51]:
def get_sentiment_from_outlines(text: Union[str, list]) -> str:
return generate.choice(transformer_model, sentiment)(text)
get_sentiment_from_outlines("I love outlines and transformers for sentiment labelling.")
[51]:
'positive'
我们也可以将 choice 方法与字符串列表一起使用。
[55]:
outlines_sentiment = get_sentiment_from_outlines(outlines_reviews)
outlines_sentiment
[55]:
['neutral', 'positive']
MultiLabelQuestion#
在此步骤中,我们将重用从 lanchain_reviews 和 outlines_reviews 生成的评论,并将它们的主题标记为多标签分类问题的一部分。
Langchain#
请注意,我们现在使用输出解析器作为返回输出的后处理步骤。 我们这样做是为了确保我们可以获得 List[str]。 我们将使用内置的 CommaSeparatedListOutputParser,它按逗号分割字符串并返回字符串列表作为输出。 并且我们以类似于 SingleLabelQuestion 的方式使用类似 jinja 的模板。
[30]:
output_parser = CommaSeparatedListOutputParser()
template = (
f'Classify the text as the following topics: {topic}. '
'Return zero or more topics as a comma-separated list. If zero return an empty string. '
'{prompt}'
)
prompt = PromptTemplate(template=template, input_variables=["prompt"], output_parser=output_parser)
llm_chain_topics = LLMChain(prompt=prompt, llm=openai_model, output_parser=output_parser)
def get_topics_from_langchain(text: str) -> str:
return [topic.lower() for topic in llm_chain_topics.predict(prompt=text) if topic != '']
get_topics_from_langchain(f"I love extracting {topic} with and openai and langchain for topic labelling.")
[30]:
['new_card', 'mortgage', 'application', 'payments']
我们获得了生成的 langchain_reviews 的主题标签。
[67]:
langchain_topics = [get_topics_from_langchain(review) for review in langchain_reviews]
langchain_topics
[67]:
[['new_card'], ['mortgage', 'application']]
Outlines#
Outlines 没有直接从选项中生成数据的方法,但我们能够利用其 Pydantic 集成来生成 json 模式。 请注意,这是一种临时的黑客方法,旨在促进这种引导式生成,并且在 outlines 包背后的论文中没有正式提及。
此外,使用 json 需要 pydantic>=2。
# DEMO CODE
class Topic(BaseModel):
new_card: bool = False
mortgage: bool = False
application: bool = False
payments: bool = False
def get_topics_from_outlines(text: str) -> str:
topics = []
json_data = generate.json(transformer_model, Topic)(langchain_reviews[0])
for key, value in json_data.items():
if value:
topics.append(key)
return topics
get_topics_from_outlines(f"I love extracting {topic} with and outlines and transformers for topic labelling.")
创建合成记录#
现在我们有了合成数据和预测,我们可以使用它们来创建 Argilla 记录。 我们将从 TextField 的 text 创建完全人工的记录,并且我们将分别将 sentiment 和 topics 分配为 LabelQuestion 和 MultiLabelQuestion 的模型建议。 这些建议将帮助注释者更快、更准确地标注数据,但是除了将它们用作建议之外,您还可以将它们直接应用为注释的响应。
出于演示目的,我们将仅使用从 langchain 获得的合成数据创建记录。
[31]:
def create_synthetic_record():
review = generate_langchain_review()
record = rg.FeedbackRecord(
fields={
"text": review,
}
)
sentiment = get_sentiment_from_langchain(review)
topics = get_topics_from_langchain(review)
record.update(suggestions=[
{"question_name": "sentiment", "value": sentiment},
{"question_name": "topics", "value": topics}
])
return record
record = create_synthetic_record()
record
[31]:
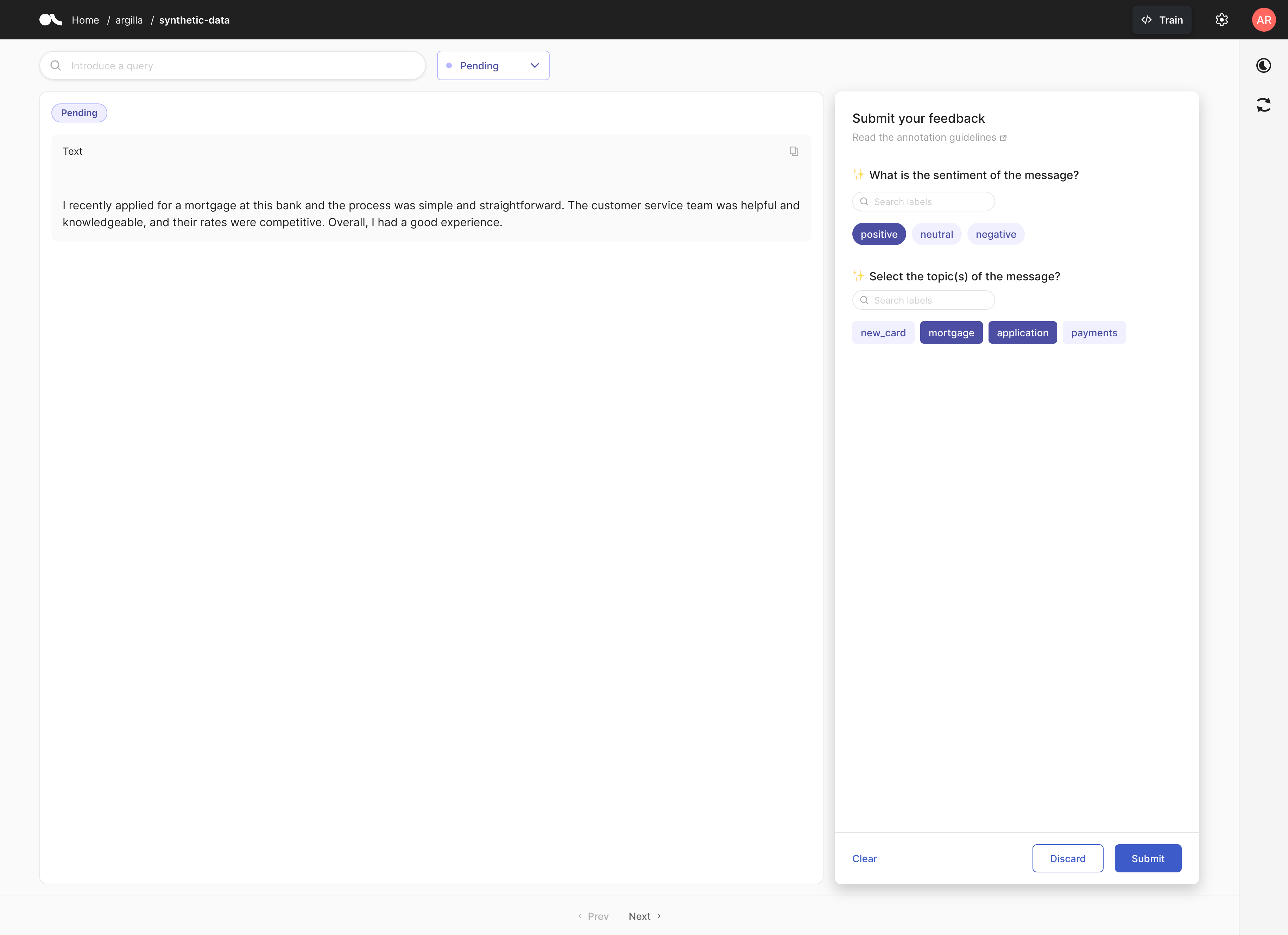
FeedbackRecord(fields={'text': '\n\nI recently applied for a mortgage at this bank and the process was simple and straightforward. The customer service team was helpful and knowledgeable, and their rates were competitive. Overall, I had a good experience.'}, metadata={}, responses=[], suggestions=(SuggestionSchema(question_id=None, question_name='sentiment', type=None, score=None, value='positive', agent=None), SuggestionSchema(question_id=None, question_name='topics', type=None, score=None, value=['mortgage', 'application'], agent=None)), external_id=None)
然后,我们将合成的 record 添加到数据集,并将模型数据和数据集上传到 Argilla 服务器
[ ]:
dataset.add_records([record])
remote_dataset = dataset.push_to_argilla(name="synthetic-data", workspace="argilla")
结论#
在本教程中,我们介绍了如何使用 OpenAI 和 Lanchain 或 Transformers 和 Outlines 创建合成数据。 我们重点介绍了在提示工程方面合成数据生成的一些注意事项。 最后,我们展示了如何将此合成数据用作 Argilla 记录的输入和建议。
要了解有关 LLM、LangChain 和 OpenAI 的更多信息,请查看以下链接: