🐭 使用 skweak 训练 NER 模型#
本教程将引导您完成使用 Argilla 改进弱监督和数据编程工作流程的过程,使用 skweak 库。
使用 Argilla、skweak 和 spaCy,我们为 CoNLL 2003 数据集定义启发式规则。
然后,我们将标记的文档记录到 Argilla,并通过其 Web 应用程序可视化结果。
在聚合噪声标签后,我们微调并评估 spaCy NER 模型。
简介#
我们的目标是向您展示如何将 Argilla 整合到数据编程工作流程中,以通过人工参与的方法以编程方式构建训练数据。我们将使用 skweak 库。
弱监督是机器学习的一个分支,它基于更有效地获得较低质量的标签。我们可以通过使用 skweak 来实现这一点,这是一个用于以编程方式构建和管理训练数据集而无需手动标记的库。
在本教程中,我们将向您展示如何在 skweak 中使用 Argilla 扩展弱监督工作流程。
我们将从 CoNLL 2003 数据集中获取记录,并使用 skweak 构建我们自己的注释。然后,我们将评估在 CoNLL 2003 开发集上使用我们的注释训练的 NER 模型。
运行 Argilla#
在本教程中,您需要运行 Argilla 服务器。部署和运行 Argilla 有两种主要选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,您可以通过单击几下在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 官方 Hugging Face Hub 指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地计算机上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种选项可以运行它
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 Notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 Notebook 并在本地计算机或您选择的 Jupyter Notebook 工具上运行它。
设置#
在本教程中,您需要使用 pip 安装 Argilla 客户端和一些第三方库
[ ]:
%pip install argilla datasets spacy -qqq
%pip install skweak
!python -m spacy download en_core_web_md
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含我们需要的导入
[ ]:
import re
import random
from functools import partial
from tqdm.auto import tqdm
import pandas as pd
from datasets import load_dataset
import spacy
from spacy.tokens import Doc, Span
from spacy.vocab import Vocab
from spacy.training.iob_utils import iob_to_biluo, biluo_tags_to_offsets
from spacy.training import Example
from spacy.scorer import Scorer
from skweak.heuristics import FunctionAnnotator
from skweak.base import CombinedAnnotator
from skweak.analysis import LFAnalysis
from skweak.aggregation import MajorityVoter
from skweak.utils import docbin_writer
启用遥测#
我们从您与教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
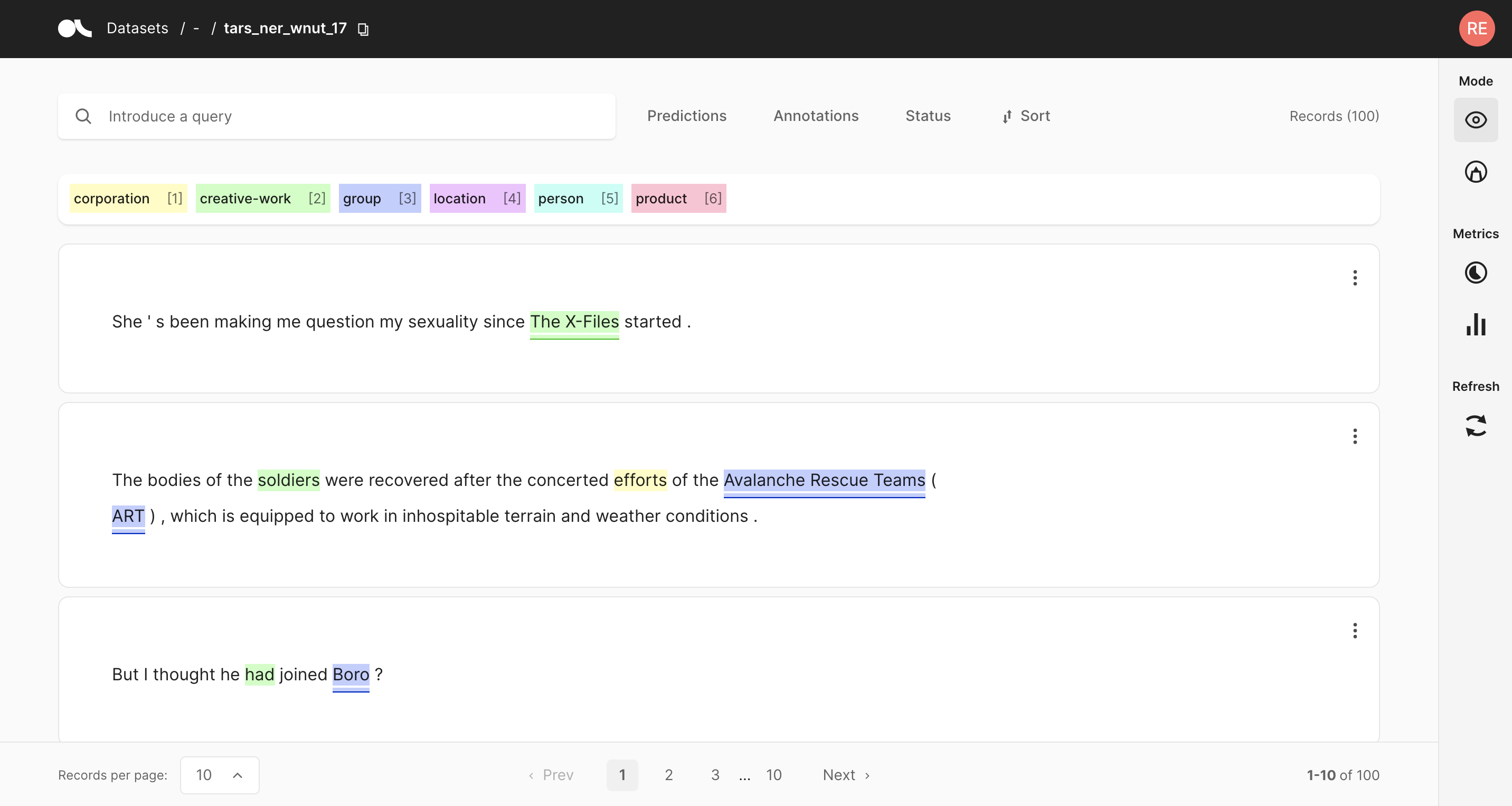
1. 将数据集记录到 Argilla 中#
Argilla 允许您记录和跟踪不同 NLP 任务的数据(例如 Token Classification 或 Text Classification)。
在本教程中,我们将使用 CoNLL 2003 数据集的英文部分,这是一个标准的命名实体识别基准。
数据集#
我们将使用 skweak 的数据编程方法来注释我们的训练集,并借助 Argilla 来分析和审查数据。然后,我们将在此训练集上训练模型。
尽管 CoNLL 2003 训练集的黄金标签已为人所知,但我们将有意忽略它们,因为我们在本教程中的目标是构建我们自己的注释,并查看它们在开发集上的表现如何。
为了简化我们的教程,在训练和评估中都只考虑 ORG 标签。数据集上存在的其他标签将被忽略(LOC、PER 和 MISC)。
我们将借助 datasets 库加载 CoNLL 2003 数据集。
[ ]:
conll2003 = load_dataset("conll2003")
日志记录#
在记录开发数据之前,我们定义一个实用函数,将我们的 NER 标签从 datasets 格式转换为 Argilla 注释。
[ ]:
def tags_to_entities(row):
doc = Doc(Vocab(), words=row["tokens"])
ner_tags = conll2003["train"].features["ner_tags"].feature.int2str(row["ner_tags"])
offsets = biluo_tags_to_offsets(doc, iob_to_biluo(ner_tags))
return [(entity, start, stop) for start, stop, entity in offsets]
我们定义一个生成器,它将数据集的每一行作为 TokenClassificationRecord 对象生成。
[ ]:
def dataset_to_records(dataset):
for row in tqdm(dataset):
text = " ".join(row["tokens"])
# Seems like we have "empty" rows
if not text.strip():
continue
yield rg.TokenClassificationRecord(
text=text, tokens=row["tokens"], annotation=tags_to_entities(row)
)
现在,我们通过 Argilla API 上传我们的记录以进行首次检查。尽管我们正在上传所有注释,但我们可以在 Web 应用程序上筛选 ORG 实体。
[ ]:
rg.log(dataset_to_records(conll2003["validation"]), "conll2003_dev")
2. 使用 Argilla 编写 skweak 启发式规则#
skweak 中的启发式规则通过标记函数应用。这些函数中的每一个都必须生成带注释的 span 的开始和结束索引,然后是其分配的标签。
注释特定案例:运动队#
我们定义我们的第一个启发式规则来匹配与运动队相关的记录。
在 Argilla 上检查数据集后,我们可以注意到,一些记录以运动队名称开头,后跟其比赛得分。
我们还注意到,其他记录组包含两支运动队的名称以及他们相互比赛后的得分。
我们编写两条规则来捕获这些运动队名称作为 ORG 实体。
[ ]:
def sports_results_detector(doc):
"""
Captures a sports team name followed by its game scores.
Labels the sports team as an ORG.
Examples:
Loznica 4 2 0 2 7 4 6
Berwick 3 0 0 3 1 14 0
"""
# Label the first word as ORG if it is followed only by numbers and punctuation.
if len(doc) < 2:
return
has_digits = False
for idx, token in enumerate(doc):
if not idx and token.text.isalpha() and token.text.istitle():
continue
elif idx and token.text.isdigit():
continue
else:
break
else:
yield 0, 1, "ORG"
def sports_match_detector(doc):
"""
Captures a sports match.
Labels both sports teams as ORG.
Examples:
Bournemouth 1 Peterborough 2
Dumbarton 1 Brechin 1
"""
if len(doc) != 4:
return
if (
doc[0].text.istitle()
and doc[1].text.isdigit()
and doc[2].text.istitle()
and doc[3].text.isdigit()
):
yield 0, 1, "ORG"
yield 2, 3, "ORG"
让我们将启发式规则封装为标记函数。
标记函数定义为 FunctionAnnotator 对象,多个函数可以分组在一个 CombinedAnnotator 中。
[ ]:
sports_results_annotator = FunctionAnnotator("sports_results", sports_results_detector)
sports_match_annotator = FunctionAnnotator("sports_match", sports_match_detector)
虽然可以独立调用这些注释器中的每一个,但如果我们要在同一时间调用多个注释器,则将它们分组在单个组合注释器下会更方便。
我们通过 add_annotator 方法将它们中的每一个添加到我们的组合注释器中。
[ ]:
rule_based_annotator = CombinedAnnotator()
for annotator in [sports_results_annotator, sports_match_annotator]:
rule_based_annotator.add_annotator(annotator)
使用通用规则注释#
我们还可以编写一些更通用的规则。
例如,组织通常表现为一系列大写单词,这些单词以某个关键字开头或结尾。我们编写一个名为 title_detector 的生成器来捕获它们。
[ ]:
def title_detector(doc, keyword=None, label="ORG", reverse=False):
"""
Captures a sequence of capitalized words that either start or end with a certain keyword.
Labels the sequence, including the keyword, with the ORG label.
Examples:
The following examples start with the keyword "U.S.":
- U.S. Treasury Department
- U.S. Treasuries
- U.S. Agriculture Department
The following examples end with the keyword "Corp":
- First of Michigan Corp
- Caltex Petroleum Corp
- Kia Motor Corp
"""
start = None
end = None
if reverse:
len_doc = len(doc)
doc = reversed(doc)
for idx, token in enumerate(doc):
if token.text == keyword:
start = idx
elif start:
if token.text.istitle():
continue
else:
if start + 2 != idx:
end = idx
if reverse:
start, end = len_doc - end, len_doc - start
yield start, end, label
start = None
end = None
我们采用一小部分关键字列表,这些关键字出现在大写 ORG 实体的开头,并为每个关键字初始化一个注释器。所有注释器都添加到我们的组合注释器 rule_based_annotator 中。
[ ]:
title_start = ["Federal", "National", "New", "United", "First", "U.N."]
for keyword in title_start:
func = partial(title_detector, keyword=keyword, reverse=False)
annotator = FunctionAnnotator(keyword + " (start)", func)
rule_based_annotator.add_annotator(annotator)
我们重复相同的过程,但这次针对出现在大写 ORG 实体末尾的关键字。
[ ]:
title_ending = [
"Office",
"Department",
"Association",
"Corporation",
"Army",
"Party",
"Exchange",
"Council",
"University",
"Newsroom",
"Bureau",
"Organisation",
"Council",
"Group",
"Inc",
"Corp",
"Ltd",
]
for keyword in title_ending:
func = partial(title_detector, keyword=keyword, reverse=True)
annotator = FunctionAnnotator(keyword + " (end)", func)
rule_based_annotator.add_annotator(annotator)
如果您有大量必须在每次出现时都标记为实体的关键字列表(例如,所有财富 500 强公司的名称列表),您可能有兴趣使用 GazetteerAnnotator。skweak 文档上的逐步 NER 教程 展示了如何使用词典来注释您的数据。
使用正则表达式注释#
到目前为止,我们所有的规则都操作 spaCy Doc 对象来捕获匹配 span 的开始和结束索引。
但是,也可以通过直接在文本上应用正则表达式模式来捕获实体。
Argilla 对正则表达式运算符提供了一些支持。如果我们搜索 *shire 并筛选标记为 ORG 的记录,我们会注意到许多运动队名称以 -shire 结尾。
我们可以编写一条规则来捕获这些实体。此规则可以添加到我们的组合注释器中,方式与我们迄今为止定义的所有启发式规则相同。
[ ]:
def shire_detector(doc):
"""
Captures sports team names ending with -shire.
Examples:
- Derbyshire
- Hampshire
- Worcestershire
"""
for match in re.finditer("[A-Z][a-z]*shire", doc.text):
char_start, char_end = match.span()
span = doc.char_span(char_start, char_end)
if span:
yield span.start, span.end, "ORG"
[ ]:
shire_annotator = FunctionAnnotator("shire_team", shire_detector)
rule_based_annotator.add_annotator(shire_annotator)
只要我们返回 span 的开始、结束和标签,我们就允许以我们喜欢的任何方式在 Doc 对象中捕获实体。
除了正则表达式之外,检测此类实体的另一种方法是使用 Matcher 对象,如 spaCy 文档中所定义的那样。
记录到 Argilla#
在定义我们的标记函数之后,是时候有效地注释我们的文档了。
首先,我们使用黄金标签注释开发集,并添加我们的标记函数的弱标签。
[ ]:
def annotate_dataset(
dataset, tokens_field="tokens", label_field="ner_tags", gold_field="gold"
):
for row in tqdm(dataset):
doc = Doc(Vocab(), words=row[tokens_field])
ner_tags = dataset.features[label_field].feature.int2str(row[label_field])
offsets = biluo_tags_to_offsets(doc, iob_to_biluo(ner_tags))
spans = [doc.char_span(x[0], x[1], label=x[2]) for x in offsets]
doc.spans[gold_field] = spans
yield doc
dev_docs = list(annotate_dataset(conll2003["validation"]))
dev_docs = list(rule_based_annotator.pipe(dev_docs))
然后,我们将记录到 Argilla,对于这些记录,任何标记函数都触发了弱标签,或者我们有黄金注释。通过这种方式,我们将能够快速可视化任何错误或我们标记函数可能尚未涵盖的缺失边缘情况。
我们还添加了一个元数据 doc_index,它将允许我们将同一文档的不同标记函数分组。
[ ]:
def spans_logger(docs, dataset="conll_2003_spans"):
def unroll_spans(span_list):
return [(span.label_, span.start_char, span.end_char) for span in span_list]
for idx, doc in enumerate(tqdm(docs)):
tokens = [token.text for token in doc]
if tokens == []:
continue
predictions, annotations = {}, None
for labelling_function, span_list in doc.spans.items():
if labelling_function == "gold":
annotations = unroll_spans(span_list)
else:
predictions[labelling_function] = unroll_spans(span_list)
# Add records for each labeling function, if they made a prediction
for agent, prediction in predictions.items():
if prediction:
yield rg.TokenClassificationRecord(
text=" ".join(tokens),
tokens=tokens,
prediction=prediction,
prediction_agent=agent,
annotation=annotations,
metadata={"doc_index": idx},
)
# Add records with annotations, for which no labeling function triggered
if not any(predictions.values()) and annotations:
yield rg.TokenClassificationRecord(
text=" ".join(tokens),
tokens=tokens,
annotation=annotations,
metadata={"doc_index": idx},
)
rg.log(records=spans_logger(dev_docs), name="conll_2003_dev_spans")
3. 评估规则的精度#
在通过 Argilla 全面了解我们的注释后,我们可以使用 skweak 的 LFAnalysis 以数字方式评估我们规则的精度。
我们希望从我们的组合注释器中消除精度得分非常低的规则,因为这可能会对使用我们的注释数据训练的模型的性能产生负面影响。
[38]:
# We evaluate the precision of our heuristic rules
lf_analysis = LFAnalysis(dev_docs, ["ORG"])
scores = lf_analysis.lf_empirical_scores(
dev_docs, gold_span_name="gold", gold_labels=["ORG", "MISC", "PER", "LOC", "O"]
)
def scores_to_df(scores):
for annotator, label_dict in scores.items():
for label, metrics_dict in label_dict.items():
row = {
"annotator": annotator,
"label": label,
"precision": metrics_dict["precision"],
"recall": metrics_dict["recall"],
"f1": metrics_dict["f1"],
}
yield row
evaluation_df = (
pd.DataFrame(list(scores_to_df(scores)))
.round(3)
.sort_values(["label", "precision"], ascending=False)
.reset_index(drop=True)
)
evaluation_df[["annotator", "label", "precision"]]
[38]:
| 注释器 | 标签 | 精度 | |
|---|---|---|---|
| 0 | Corp (结尾) | ORG | 1.000 |
| 1 | Organisation (结尾) | ORG | 1.000 |
| 2 | Group (结尾) | ORG | 1.000 |
| 3 | Council (结尾) | ORG | 1.000 |
| 4 | Department (结尾) | ORG | 1.000 |
| 5 | Exchange (结尾) | ORG | 1.000 |
| 6 | Bureau (结尾) | ORG | 1.000 |
| 7 | Corporation (结尾) | ORG | 1.000 |
| 8 | Ltd (结尾) | ORG | 1.000 |
| 9 | sports_results | ORG | 1.000 |
| 10 | gold | ORG | 1.000 |
| 11 | sports_match | ORG | 1.000 |
| 12 | Party (结尾) | ORG | 1.000 |
| 13 | Newsroom (结尾) | ORG | 1.000 |
| 14 | Army (结尾) | ORG | 1.000 |
| 15 | Inc (结尾) | ORG | 1.000 |
| 16 | shire_team | ORG | 0.982 |
| 17 | New (开头) | ORG | 0.909 |
| 18 | U.N. (开头) | ORG | 0.882 |
| 19 | Association (结尾) | ORG | 0.800 |
| 20 | First (开头) | ORG | 0.800 |
| 21 | United (开头) | ORG | 0.800 |
| 22 | Federal (开头) | ORG | 0.714 |
| 23 | National (开头) | ORG | 0.640 |
4. 注释训练数据并聚合弱标签#
聚合#
在仔细考虑了哪些规则适合我们的数据集之后,我们将注释训练数据,然后将我们的注释聚合到单个层中。
skweak 包括一个名为多数投票器的聚合模型。它将每个标记函数视为一个投票者,并输出最频繁的标签。我们将使用此多数投票器为我们的文档生成一组注释,然后我们将结果记录到 Argilla。
当为多个标签进行注释时,多数投票器特别有用,因为在这种情况下,启发式规则产生的注释不仅可能重叠,而且可能相互冲突。但是,由于我们仅针对 ORG 标签进行注释,因此我们不需要多数投票器来解决任何冲突:它只会将每个注释器的标签合并到 maj_voter 字段中。
[ ]:
# Create the training docs and annotate them with heuristic rules
train_docs = [Doc(Vocab(), words=row["tokens"]) for row in conll2003["train"]]
train_docs = list(rule_based_annotator.pipe(train_docs))
[ ]:
# Perform majority voting over the training data
voter = MajorityVoter("maj_voter", labels=["ORG"], sequence_labelling=True)
train_docs = list(voter.pipe(train_docs))
[ ]:
# Log to Argilla
rg.log(records=spans_logger(train_docs), name="conll_2003_train")
尽管在这里我们以相当简单的方式使用多数投票器来投票单个 ORG 标签,但可以为每个标记函数的投票赋予权重,甚至定义标签之间复杂的层次结构。这些详细信息在多数投票器文档和 代码(在 skweak 存储库中)中进行了解释。
生成训练数据#
我们的最终注释应设置为 spaCy Doc 对象的 ents 字段。
我们为训练集设置由多数投票器定义的标签,为开发集设置黄金标签。
[ ]:
for doc in train_docs:
doc.set_ents(doc.spans.get("maj_voter", []))
for doc in dev_docs:
org_ents = filter(lambda token: token.label_ == "ORG", doc.spans.get("gold", []))
doc.set_ents(org_ents)
为了避免在不平衡的数据集上进行训练,我们确保在训练数据中具有相同数量的带注释记录和空白记录。
[ ]:
random.seed(42)
annotated_docs = [doc for doc in train_docs if doc.ents]
empty_docs = random.sample(
[doc for doc in train_docs if not doc.ents], len(annotated_docs)
)
train_docs_sample = annotated_docs + empty_docs
最后,我们使用 skweak 的 docbin_writer 将我们的训练集和开发集写入与 spaCy 命令行工具兼容的二进制文件格式。
[ ]:
# Save the training and development data.
docbin_writer(train_docs_sample, "/tmp/train.spacy")
docbin_writer(dev_docs, "/tmp/dev.spacy")
5. 评估基线#
在我们训练和评估我们自己的解决方案之前,让我们测试一个简单的模型,看看在没有弱监督的情况下可以实现什么。通过这种方式,我们可以看到我们的解决方案是否能够改进此基线。
我们评估 CoNLL 2003 上的 en_core_web_md spaCy 模型。该模型已在不同的数据集 OntoNotes 5.0 上进行训练。我们不对模型执行任何类型的适配,并评估其在开发集上的零样本性能。
[49]:
nlp = spacy.load("en_core_web_md")
dev_eval_docs = [nlp(" ".join(row["tokens"])) for row in conll2003["validation"]]
for doc in dev_eval_docs:
doc.set_ents(list(filter(lambda x: x.label_ == "ORG", doc.ents)))
scorer_object = Scorer()
scores = scorer_object.score(
[Example(dev_eval_docs[i], dev_docs[i]) for i in range(0, len(dev_docs))]
)
pd.DataFrame(
[{k: v for k, v in scores.items() if k in ["ents_p", "ents_r", "ents_f"]}]
).round(3)
[49]:
| ents_p | ents_r | ents_f | |
|---|---|---|---|
| 0 | 0.453 | 0.317 | 0.373 |
6. 训练和评估我们的模型#
在这里,我们在由我们的启发式规则注释的训练数据上训练和评估 spaCy 模型。
我们使用来自我们基线模型 en_core_web_md 的向量初始化我们的 NER 模型,并对其进行 400 步训练。
[20]:
# After training our model on data annotated with heuristic rules, we reach an F score of 44%, which is 7% above the baseline.
!spacy init config - --lang en --pipeline ner --optimize accuracy | \
spacy train - \
--training.max_steps 400 \
--system.seed 42 \
--paths.train /tmp/train.spacy \
--paths.dev /tmp/dev.spacy \
--initialize.vectors en_core_web_md \
--output /tmp/model
ℹ Saving to output directory: /tmp/model
ℹ Using CPU
=========================== Initializing pipeline ===========================
[2022-01-27 12:38:58,091] [INFO] Set up nlp object from config
[2022-01-27 12:38:58,102] [INFO] Pipeline: ['tok2vec', 'ner']
[2022-01-27 12:38:58,107] [INFO] Created vocabulary
[2022-01-27 12:38:59,423] [INFO] Added vectors: en_core_web_lg
[2022-01-27 12:39:00,729] [INFO] Finished initializing nlp object
[2022-01-27 12:39:23,582] [INFO] Initialized pipeline components: ['tok2vec', 'ner']
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'ner']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS NER ENTS_F ENTS_P ENTS_R SCORE
--- ------ ------------ -------- ------ ------ ------ ------
0 0 0.00 39.17 2.97 2.26 4.33 0.03
0 200 69.40 1239.88 36.93 91.72 23.12 0.37
1 400 15.18 280.61 43.67 78.79 30.20 0.44
✔ Saved pipeline to output directory
/tmp/model/model-last
总结#
编写精确的启发式规则是使用 skweak 进行弱监督工作流程的关键组成部分。Argilla 使我们更容易识别数据中的模式,创建新规则,然后调试我们的标记函数。通过这种方式,我们可以加速我们的数据注释管道,并快速训练出得分高于常见零样本基线的新模型。