📰 使用弱监督训练文本分类器#
在本教程中,我们将使用规则和弱监督构建一个新闻分类器
📰 对于此示例,我们使用 AG News 数据集,但您可以按照此过程以编程方式标记任何数据集。
🤿 使用没有标签的训练拆分来构建具有规则、Argilla 和 Snorkel 的标签模型的训练集。
🔧 测试集用于评估我们的弱标签、标签模型和下游新闻分类器。
🤯 我们在没有使用原始数据集中的任何示例的情况下,并使用相当轻量级的模型(scikit-learn 的
MultinomialNB)实现了 0.82 的宏平均 f1 分数。
下图显示了将弱监督与 Argilla 结合使用的总体流程
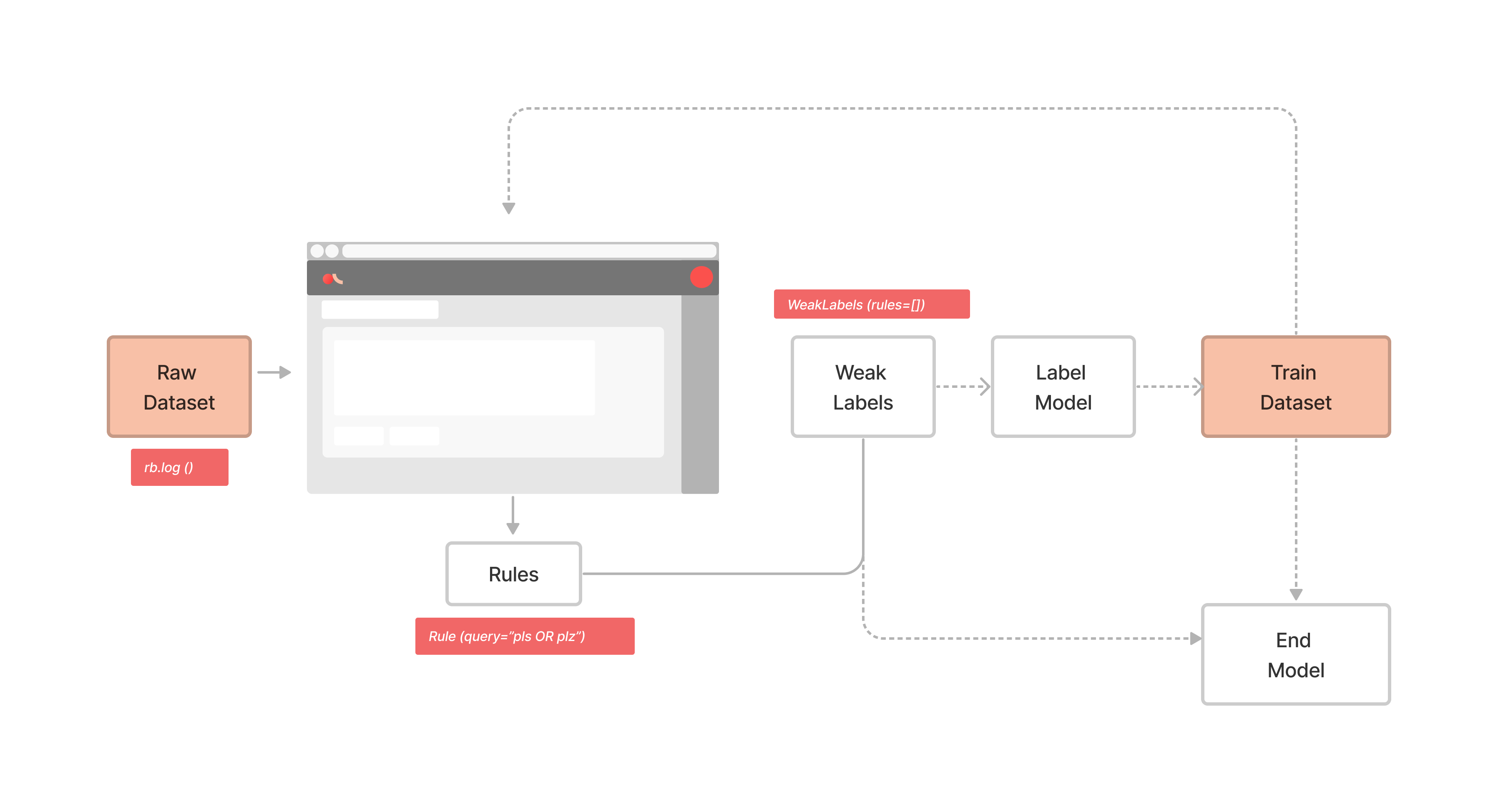
简介#
弱监督是机器学习的一个分支,其中使用噪声、有限或不精确的来源为监督学习环境中标记大量训练数据提供监督信号。这种方法减轻了获取手动标记数据集的负担,这可能是昂贵或不切实际的。相反,采用廉价的弱标签,并理解它们是不完美的,但仍然可以用于创建强大的预测模型。 [Wikipedia]
为了更广泛地介绍弱监督以及更多参考资料,我们推荐 Alex Ratner 等人的优秀概述。
本教程旨在作为弱监督的实用介绍,并将引导您完成其整个过程。首先,我们将使用 Argilla 生成弱标签,将这些标签与 Snorkel 结合起来,最后使用 Scikit Learn 训练分类器。
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 有两种主要选择
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部笔记本(例如 Google Colab)运行教程,并且您在 Hugging Face 上拥有帐户,则只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看官方 Hugging Face Hub 指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在本地机器上运行 Argilla,这是推荐的选项。请注意,此选项仅允许您在本地运行教程,而不能与外部笔记本服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种选择可以运行它
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行笔记本。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载笔记本并在本地机器或您选择的 Jupyter 笔记本工具上运行它。
设置#
对于本教程,您需要使用 pip 安装 Argilla 客户端和一些第三方库
[ ]:
%pip install argilla snorkel datasets sklearn -qqq
让我们导入 Argilla 模块以用于读取和写入数据
[1]:
import argilla as rg
如果您正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含我们需要的导入
[ ]:
from datasets import load_dataset
import pandas as pd
from argilla.labeling.text_classification import *
from sklearn.feature_extraction.text import TfidfTransformer, CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn import metrics
启用遥测#
我们从您与我们的教程互动的方式中获得了宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
注意
如果您想跳过本教程的前三个部分,而只准备训练集并训练下游模型,您可以直接从 Hugging Face Hub 加载记录
import argilla as rg
from datasets import load_dataset
# this replaces the `records = label_model.predict()` line of section 4
records = rg.read_datasets(
load_dataset("argilla/news", split="train"),
task="TextClassification",
)
1. 将测试和未标记的数据集加载到 Argilla 中#
首先,让我们下载 ag_news 数据集并快速浏览一下。
[ ]:
# load our data
dataset = load_dataset("ag_news")
# get the index to label mapping
labels = dataset["test"].features["label"].names
[5]:
# quick look at our data
with pd.option_context("display.max_colwidth", None):
display(dataset["test"].to_pandas().head())
| 文本 | 标签 | |
|---|---|---|
| 0 | Fears for T N pension after talks Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul. | 2 |
| 1 | The Race is On: Second Private Team Sets Launch Date for Human Spaceflight (SPACE.com) SPACE.com - TORONTO, Canada -- A second\team of rocketeers competing for the #36;10 million Ansari X Prize, a contest for\privately funded suborbital space flight, has officially announced the first\launch date for its manned rocket. | 3 |
| 2 | Ky. Company Wins Grant to Study Peptides (AP) AP - A company founded by a chemistry researcher at the University of Louisville won a grant to develop a method of producing better peptides, which are short chains of amino acids, the building blocks of proteins. | 3 |
| 3 | Prediction Unit Helps Forecast Wildfires (AP) AP - It's barely dawn when Mike Fitzpatrick starts his shift with a blur of colorful maps, figures and endless charts, but already he knows what the day will bring. Lightning will strike in places he expects. Winds will pick up, moist places will dry and flames will roar. | 3 |
| 4 | Calif. Aims to Limit Farm-Related Smog (AP) AP - Southern California's smog-fighting agency went after emissions of the bovine variety Friday, adopting the nation's first rules to reduce air pollution from dairy cow manure. | 3 |
现在,我们将数据集的测试拆分记录到 Argilla 中,我们将使用它来测试我们的标签和下游模型。
[ ]:
# build our test records
records = [
rg.TextClassificationRecord(
text=record["text"],
metadata={"split": "test"},
annotation=labels[record["label"]],
)
for record in dataset["test"]
]
# log the records to Argilla
rg.log(records, name="news")
在第二步中,我们记录没有标签的训练拆分。请记住,我们的目标是使用规则和弱监督以编程方式构建训练集。
[ ]:
# build our training records without labels
records = [
rg.TextClassificationRecord(
text=record["text"],
metadata={"split": "unlabelled"},
)
for record in dataset["train"]
]
# log the records to Argilla
rg.log(records, name="news")
上述结果是 Argilla 中的以下数据集,包含 127,600 条记录(120,000 条未标记的记录和 7,600 条用于测试的记录)。
您可以使用 Web 应用程序来查找用于编程标记的良好规则!
2. 定义规则#
可以使用 (1) UI 和 (2) Python 客户端定义和管理规则。我们将使用 Python 客户端添加一些规则,这些规则将在 UI 中可用,我们可以在其中开始我们的交互式弱标记。
[32]:
# define queries and patterns for each category (using ES DSL)
queries = [
(["money", "financ*", "dollar*"], "Business"),
(["war", "gov*", "minister*", "conflict"], "World"),
(["footbal*", "sport*", "game", "play*"], "Sports"),
(["sci*", "techno*", "computer*", "software", "web"], "Sci/Tech"),
]
# define rules
rules = [Rule(query=term, label=label) for terms, label in queries for term in terms]
[13]:
# add rules to the dataset
add_rules(dataset="news", rules=rules)
3. 使用 Snorkel 的标签模型去噪弱标签#
此步骤的目标是去噪我们刚刚使用规则创建的弱标签。有几种方法可以使用不同的统计方法来解决这个问题。
在本教程中,我们将使用 Snorkel,但实际上您可以使用任何其他标签模型或弱监督方法,例如 FlyingSquid(有关更多详细信息,请参阅弱监督指南)。为了方便起见,Argilla 定义了 Snorkel 标签模型的简单包装器,因此更容易与 Argilla 弱标签和数据集一起使用
让我们首先读取在我们的数据集中定义的规则并创建我们的弱标签
[15]:
weak_labels = WeakLabels(dataset="news")
weak_labels.summary()
[15]:
| 标签 | 覆盖率 | 注释覆盖率 | 重叠 | 冲突 | 正确 | 不正确 | 精度 | |
|---|---|---|---|---|---|---|---|---|
| money | {Business} | 0.008268 | 0.008816 | 0.002484 | 0.001983 | 30 | 37 | 0.447761 |
| financ* | {Business} | 0.019655 | 0.017763 | 0.005933 | 0.005227 | 80 | 55 | 0.592593 |
| dollar* | {Business} | 0.016591 | 0.016316 | 0.003582 | 0.002947 | 87 | 37 | 0.701613 |
| war | {World} | 0.015627 | 0.017105 | 0.004459 | 0.001732 | 101 | 29 | 0.776923 |
| gov* | {World} | 0.045086 | 0.045263 | 0.011191 | 0.006277 | 170 | 174 | 0.494186 |
| minister* | {World} | 0.030031 | 0.028289 | 0.007908 | 0.002821 | 193 | 22 | 0.897674 |
| conflict | {World} | 0.003025 | 0.002763 | 0.001097 | 0.000102 | 17 | 4 | 0.809524 |
| footbal* | {Sports} | 0.013158 | 0.015000 | 0.004953 | 0.000447 | 107 | 7 | 0.938596 |
| sport* | {Sports} | 0.021191 | 0.021316 | 0.007038 | 0.001223 | 139 | 23 | 0.858025 |
| game | {Sports} | 0.038738 | 0.037632 | 0.014060 | 0.002390 | 216 | 70 | 0.755245 |
| play* | {Sports} | 0.052453 | 0.050000 | 0.016991 | 0.005196 | 268 | 112 | 0.705263 |
| sci* | {Sci/Tech} | 0.016552 | 0.018421 | 0.002782 | 0.001340 | 114 | 26 | 0.814286 |
| techno* | {Sci/Tech} | 0.027210 | 0.028289 | 0.008534 | 0.003205 | 155 | 60 | 0.720930 |
| computer* | {Sci/Tech} | 0.027586 | 0.028158 | 0.011277 | 0.004514 | 159 | 55 | 0.742991 |
| software | {Sci/Tech} | 0.030188 | 0.029474 | 0.009828 | 0.003378 | 183 | 41 | 0.816964 |
| web | {Sci/Tech} | 0.017132 | 0.014737 | 0.004561 | 0.001779 | 87 | 25 | 0.776786 |
| total | {World, Sci/Tech, Business, Sports} | 0.320964 | 0.315000 | 0.055149 | 0.020039 | 2106 | 777 | 0.730489 |
[16]:
# create the label model
label_model = Snorkel(weak_labels)
# fit the model
label_model.fit()
100%|██████████| 100/100 [00:00<00:00, 1228.48epoch/s]
[17]:
print(label_model.score(output_str=True))
precision recall f1-score support
Business 0.66 0.35 0.46 455
World 0.70 0.81 0.75 522
Sci/Tech 0.78 0.77 0.77 784
Sports 0.78 0.96 0.86 633
accuracy 0.75 2394
macro avg 0.73 0.72 0.71 2394
weighted avg 0.74 0.75 0.73 2394
4. 准备我们的训练集#
现在,我们已经有了一个“去噪”的训练集,我们可以准备它来训练下游模型。标签模型预测返回带有来自标签模型的 predictions 的 TextClassificationRecord 对象。
我们可以使用 Argilla Web 应用程序来改进和审查这些记录,按原样使用它们,或者例如按分数过滤它们。
在这种情况下,我们假设预测足够精确,并且在没有任何修改的情况下使用它们。我们的训练集有约 38,000 条记录,这对应于标签模型未弃权的所有记录。
[18]:
# get records with the predictions from the label model
records = label_model.predict()
# you can replace this line with
# records = rg.read_datasets(
# load_dataset("argilla/news", split="train"),
# task="TextClassification",
# )
# we could also use the `weak_labels.label2int` dict
label2int = {"Sports": 0, "Sci/Tech": 1, "World": 2, "Business": 3}
# extract training data
X_train = [rec.text for rec in records]
y_train = [label2int[rec.prediction[0][0]] for rec in records]
[19]:
# quick look at our training data with the weak labels from our label model
with pd.option_context("display.max_colwidth", None):
display(pd.DataFrame({"text": X_train, "label": y_train}))
| 文本 | 标签 | |
|---|---|---|
| 0 | Tennis: Defending champion Myskina sees off world number one <b>...</b> MOSCOW : Defending champion and French Open winner Anastasia Myskina advanced into the final of the 2.3 million dollar Kremlin Cup beating new world number one Lindsay Davenport of the United States here. | 3 |
| 1 | Britain Pays Final Respects to Beheaded Hostage British Prime Minister Tony Blair was among the hundreds of people that attended an emotional service for a man kidnapped and killed in Iraq. | 2 |
| 2 | Skulls trojan targets Symbian smartphones A new trojan on the internet attacks the Nokia 7610 smartphone and possibly other phones running Symbian Series 60 software. quot;We have located several freeware and shareware sites offering a program, called | 1 |
| 3 | Sudan Security Foils New Sabotage Plot -- Agency Sudanese authorities said Friday they foiled another plot by an opposition Islamist party to kidnap and kill senior government officials and blow up sites in the capital | 2 |
| 4 | Sony and Partners Agree To Acquire MGM Sony Corp. and several financial partners have agreed in principle to acquire movie studio Metro-Goldwyn-Mayer for about \$2.94 billion in cash, sources familiar with the talks said Monday. | 3 |
| ... | ... | ... |
| 38556 | Titan hangs on to its secrets Cassini #39;s close fly-by of Titan, Saturn #39;s largest moon, has left scientists with no clear idea of what to expect when the Huygens probe lands on the alien world, despite the amazingly detailed images they now have of the surface. | 1 |
| 38557 | Ministers deny interest in raising inheritance tax Downing Street distanced itself last night from reports that inheritance tax will rise to 50 per cent for the wealthiest families. | 2 |
| 38558 | No Frills, but Everything Else Is on Craigslist (washingtonpost.com) washingtonpost.com - Ernie Miller, a 38-year-old software developer in Silver Spring, offers a telling clue as to how www.craigslist.org became the Internet's go-to place to solve life's vexing problems. | 1 |
| 38559 | Familiar refrain as Singh leads Just when Vijay Singh thinks he can't play better, he does. Just when it seems he can't do much more during his Tiger Woods-like season, he does that, too. | 0 |
| 38560 | Cisco to acquire P-Cube for \$200m Cisco Systems has agreed to buy software developer P-Cube in a cash-and-options deal Cisco valued at \$200m (110m). P-Cube makes software to help service providers analyse and control network traffic. | 1 |
38561 rows × 2 columns
5. 使用 scikit-learn 训练下游模型#
现在,让我们使用 scikit-learn 训练我们的最终模型
[20]:
# define our final classifier
classifier = Pipeline([("vect", CountVectorizer()), ("clf", MultinomialNB())])
# fit the classifier
classifier.fit(
X=X_train,
y=y_train,
)
[20]:
Pipeline(steps=[('vect', CountVectorizer()), ('clf', MultinomialNB())])在 Jupyter 环境中,请重新运行此单元格以显示 HTML 表示形式或信任笔记本。在 GitHub 上,HTML 表示形式无法呈现,请尝试使用 nbviewer.org 加载此页面。
Pipeline(steps=[('vect', CountVectorizer()), ('clf', MultinomialNB())])CountVectorizer()
MultinomialNB()
为了测试我们训练的模型,我们使用带有验证注释的记录,即原始 ag_news 测试集。
[21]:
# retrieve records with annotations
test_ds = weak_labels.records(has_annotation=True)
# you can replace this line with
# test_ds = rg.read_datasets(
# load_dataset("argilla/news_test", split="train"),
# task="TextClassification",
# )
# extract text and labels
X_test = [rec.text for rec in test_ds]
y_test = [label2int[rec.annotation] for rec in test_ds]
[22]:
# compute the test accuracy
accuracy = classifier.score(
X=X_test,
y=y_test,
)
print(f"Test accuracy: {accuracy}")
Test accuracy: 0.8176315789473684
还不错! 🥳
我们已经达到了大约 0.82 的准确率,甚至没有使用原始 ag_news 训练集中的任何示例,并且只有 16 条规则的小集合。此外,我们还超过了标签模型 0.75 的准确率。
最后,让我们看一下更详细的指标
[23]:
# get predictions for the test set
predicted = classifier.predict(X_test)
print(metrics.classification_report(y_test, predicted, target_names=label2int.keys()))
precision recall f1-score support
Sports 0.86 0.98 0.91 1900
Sci/Tech 0.76 0.84 0.80 1900
World 0.79 0.89 0.84 1900
Business 0.89 0.56 0.69 1900
accuracy 0.82 7600
macro avg 0.83 0.82 0.81 7600
weighted avg 0.83 0.82 0.81 7600
此时,我们可以返回 UI,为那些性能较低的标签定义更多规则。查看上表,我们可能希望添加更多规则来提高 Business 标签的召回率。
总结#
在本教程中,我们了解了如何利用弱监督快速构建大型训练数据集,并将其用于训练第一个轻量级模型。
Argilla 是一个非常方便的工具,可以通过轻松找到一组良好的起始规则并动态迭代它们来启动弱监督过程。由于 Argilla 还为最常见的标签模型提供了内置支持,因此您可以在几个简单的步骤中从规则获得弱标签。有关如何利用弱标签的更多建议,您可以查看我们的弱监督指南,我们在其中描述了一种有趣的方法,可以联合训练标签和 transformers 下游模型。
附录 I:将数据集记录到 Hugging Face Hub#
在这里,我们将向您展示我们如何将 Argilla 数据集(记录)推送到 Hugging Face Hub。通过这种方式,您可以有效地对任何 Argilla 数据集进行版本控制。
[ ]:
train_rg = rg.DatasetForTextClassification(label_model.predict())
train_rg.to_datasets().push_to_hub("argilla/news")
[ ]:
test_rg = rg.load("news", query="status:Validated")
test_rg.to_datasets().push_to_hub("argilla/news_test")