Elasticsearch#
本节介绍将 Argilla 与 Elasticsearch 实例或集群一起使用的高级配置。
配置角色和用户#
如果您有 Elasticsearch 实例并想与其他应用程序共享资源,您可以轻松地为其配置 Argilla。
您需要考虑的是
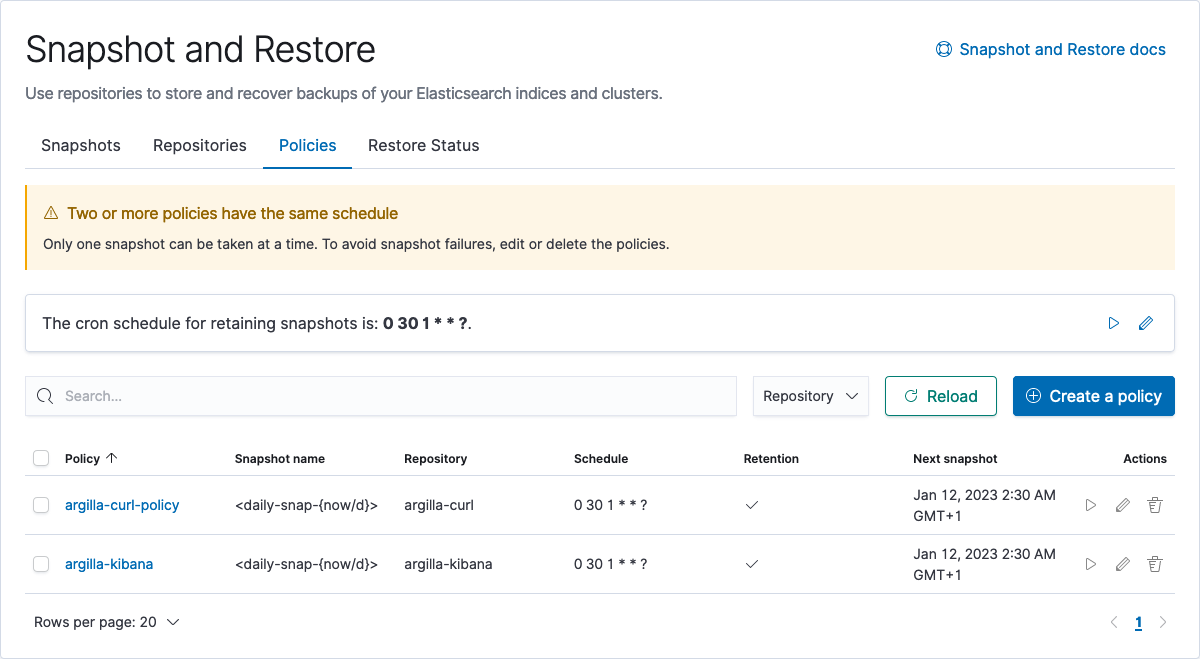
Argilla 将使用以下模式创建其 ES 索引:
rg.*和*ar.dataset*。建议创建一个新角色(例如,argilla)并为其提供这些索引模式的所有权限。
Argilla 使用
ARGILLA_ELASTICSEARCH环境变量来设置 ES 连接。
注意
Argilla 支持 ElasticSearch 版本 8.8、8.5、8.0 和 7.17。
您可以使用以下方案提供凭据
http(s)://user:passwd@elastichost
下面您可以看到一个屏幕截图,用于设置新的 argilla 角色及其权限
重新索引数据#
有时更新需要重新索引我们的数据集指标和 Elasticsearch,因此我们设计了一些 简短文档 向您展示如何从我们的 Python 客户端执行此操作。
使用快照进行备份#
在 Elastic 中,可以创建正在运行的集群的快照。我们强烈建议这样做,以确保实验的可重复性,并避免丢失您宝贵的注释数据。Elastic 提供了关于如何在 他们的文档 中执行此操作的概述。下面我们将引导您完成一个最小的可重现示例。
挂载备份卷#
部署 Elastic 时,我们需要通过在 docker-compose.yaml 中将其设置为环境变量或在 elasticsearch.yml 中设置并将其作为配置传递来定义 path.repo。此外,我们需要将相同的 path.repo 传递给已挂载的卷。默认情况下,我们将此 elasticdata:/usr/share/elasticsearch/backups 设置为默认值,因为 elasticsearch 用户需要具有对 repo 执行操作的完全权限。因此,将卷设置为其他内容可能需要一些额外的权限配置。请注意,当绑定到公共 IP 时,需要显式设置 minimum_master_nodes。
docker-compose.yaml#
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.0
container_name: elasticsearch
environment:
- node.name=elasticsearch
- cluster.name=es-local
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- cluster.routing.allocation.disk.threshold_enabled=false
- path.repo=/usr/share/elasticsearch/backups # reference volume mount for backups
ulimits:
memlock:
soft: -1
hard: -1
networks:
- argilla
volumes:
- elasticdata:/usr/share/elasticsearch/data
- elasticdata:/usr/share/elasticsearch/backups # add volume for backups
elasticsearch.yml#
node.name: elasticsearch
cluster.name: "es-local"
discovery.type: single-node
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
cluster.routing.allocation.disk.threshold_enabled: false
path.repo: "/usr/share/elasticsearch/backups"
创建快照仓库#
在指定的 path.repo 中,我们现在可以创建一个快照仓库,它将用于存储和恢复 Elasticsearch 索引和集群的备份。建议为每个主要版本执行此操作,并在将相同集群连接到该特定仓库时分配 readonly 访问权限。我们可以在 Kibana UI 中或通过 cURL 创建这些快照。
Kibana UI#
转到您的 Kibana host:p/app/management/data/snapshot_restore/repositories,在 localhost 上转到 这里。按 注册仓库 并将仓库名称设置为您喜欢的任何名称,在我们的示例中,我们将使用 argilla-kibana。此外,我们将选择使用共享文件系统的默认选项。
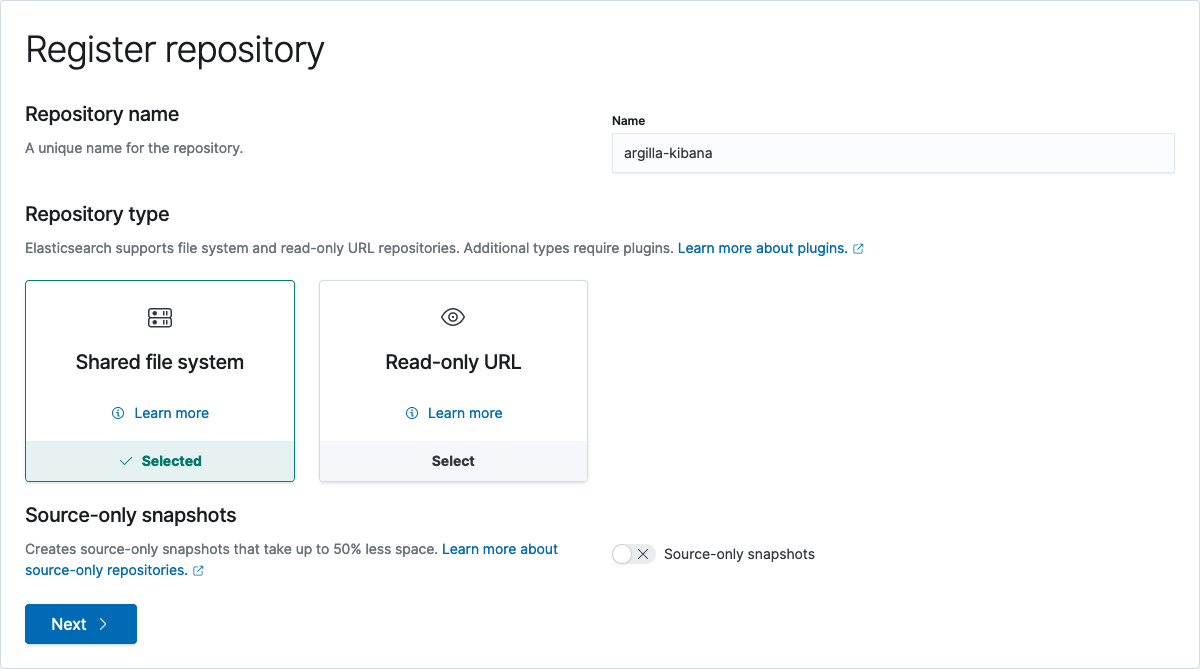
接下来,我们需要填写 path.repo 并将其设置为 /usr/share/elasticsearch/backups。此外,我们可以传递一些配置来减少由备份引起的集群负载,方法是定义分块和字节处理大小,但对于这个玩具示例,我们将保持为空。
cURL#
如果您的 Elastic IP 是公共的,则可以直接使用 cURL 创建仓库。如果不是,我们首先需要 SSH 到集群中,然后再调用 cURL 命令。在这里,我们将 location 设置为 path.repo,并将仓库名称设置为 argilla-curl。
curl -X PUT "localhost:9200/_snapshot/argilla-curl?pretty" -H 'Content-Type: application/json' -d'
{
"type": "fs",
"settings": {
"location": "/usr/share/elasticsearch/backups"
}
}
'
接下来,我们可以验证备份的创建。
curl -X GET "localhost:9200/_snapshot/argilla-curl?pretty"

创建快照策略#
现在我们已经定义了快照的存储位置,我们可以继续定义快照策略,该策略定义了快照的自动创建和删除。再次强调,这可以使用 Kibana UI 或通过 cURL 完成。请注意,通过将 indices 设置为 "ar.dataset*",策略也可以设置为 argilla 索引。
Kibana UI#
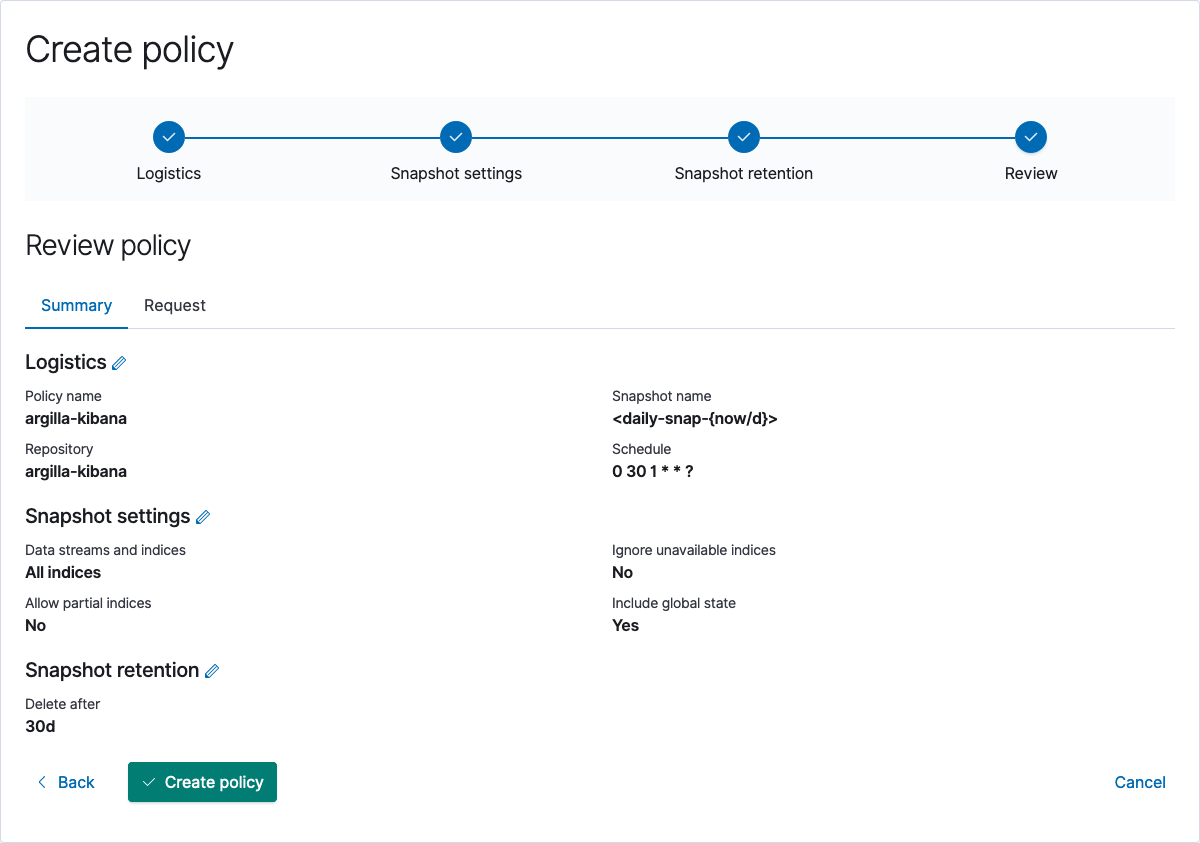
转到您的 Kibana host:ip/app/management/data/snapshot_restore/add_policy,在 localhost 上转到 这里。按 创建策略 并将仓库名称设置为您喜欢的任何名称,在我们的示例中,我们将使用 argilla-kibana-policy 并在 argilla-kibana 仓库上执行它。此外,还有一些关于保留、快照命名和调度的配置选项,我们不会深入讨论,但在下面您可以找到一个最小的示例。
cURL#
如果您的 Elastic IP 是公共的,则可以直接使用 cURL 创建仓库。如果不是,我们首先需要 SSH 到集群中,然后再调用 cURL 命令。在我们的示例中,我们将定义一个 argilla-curl-policy 并在 argilla-curl 仓库上执行它。
curl -X PUT "localhost:9200/_slm/policy/argilla-curl-policy?pretty" -H 'Content-Type: application/json' -d'
{
"schedule": "0 30 1 * * ?",
"name": "<daily-snap-{now/d}>",
"repository": "argilla-curl",
"config": {
"indices": ["data-*", "important"],
"ignore_unavailable": false,
"include_global_state": false
},
"retention": {
"expire_after": "30d"
}
}
'