⏺️ 添加和更新记录#
反馈数据集#
注意
本节涵盖的数据集类是 FeedbackDataset。这个完全可配置的数据集将取代 Argilla 2.0 中的 DatasetForTextClassification、 DatasetForTokenClassification 和 DatasetForText2Text。不确定使用哪个数据集?请查看我们关于选择数据集的部分。

定义 FeedbackRecord#
在配置 FeedbackDataset 之后,如上一指南所示。下一步是按照 Argilla 的 FeedbackRecord 格式创建记录。您可以在此处查看示例。FeedbackRecord 的属性如下:
fields:一个字典,包含记录中每个字段的名称(键)和内容(值)。这些需要与数据集配置中设置的字段匹配(请参阅定义记录字段)。external_id(可选):用户定义的记录 ID。如果没有外部 ID,则为None。metadata(可选):包含记录元数据的字典。阅读更多关于包含元数据的信息。vectors(可选):与记录关联的向量字典。阅读更多关于包含向量的信息。suggestions(可选):记录的所有建议响应的列表,例如,模型预测或其他对标注者有用的提示。阅读更多关于包含建议的信息。responses(可选):记录的所有响应的列表。如果您的数据集已经有一些已标注的记录,您才需要添加它们。阅读更多关于包含响应的信息。
# Create a single Feedback Record
record = rg.FeedbackRecord(
fields={
"question": "Why can camels survive long without water?",
"answer": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods."
},
metadata={"source": "encyclopedia"},
vectors={"my_vector": [...], "my_other_vector": [...]},
suggestions = [
{
"question_name": "corrected-answer",
"value": "This is a *suggestion*.",
}
]
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
external_id=None
)
格式化 metadata#
记录元数据可以包含字典形式的关于记录的任何信息,这些信息不是表单字段的一部分。如果您希望元数据与为数据集配置的元数据属性相对应,以便这些元数据可以用于筛选和排序记录,请确保字典的键与元数据属性 name 相对应。当键不对应时,这将视为额外的元数据,将与记录一起存储(只要数据集的 allow_extra_metadata 设置为 True),但不能用于筛选和排序。除了向单个记录添加一个元数据属性外,您还可以以列表的形式为 TermsMetadataProperty 添加聚合元数据值。
record = rg.FeedbackRecord(
fields={...},
metadata={"source": "encyclopedia", "text_length":150}
)
record = rg.FeedbackRecord(
fields={...},
metadata={"source": ["encyclopedia", "wikipedia"], "text_length":150}
)
格式化 vectors#
您可以将向量(如文本嵌入)与您的记录关联。这将启用 UI 和 Python SDK 中的 语义搜索。这些向量保存为字典,其中键对应于为您的数据集配置的向量设置的 name,值是浮点数列表。确保列表的长度与向量设置中设置的维度相对应。
提示
向量应具有以下格式 List[float]。如果您正在使用 numpy 数组,只需使用 .tolist() 方法转换它们即可。
record = rg.FeedbackRecord(
fields={...},
vectors={"my_vector": [...], "my_other_vector": [...]}
)
格式化 suggestions#
建议指的是您可以添加到记录中的建议响应(例如,模型预测),以加快标注过程。这些可以在创建记录时或稍后添加。每个问题只能提供一个建议,并且建议值必须符合预定义的问题,例如,如果我们有一个 1 到 5 的 RatingQuestion,则建议应该在该范围内具有有效值。
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "relevant",
"value": "YES",
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "content_class",
"value": ["hate", "violent"]
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "preference",
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "quality",
"value": 5,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "corrected-text",
"value": "This is a *suggestion*.",
}
]
)
格式化 responses#
如果您的数据集包含一些标注,您可以在创建记录时将这些标注添加到记录中。确保响应遵循与 Argilla 输出相同的格式,并满足所回答的特定问题类型的模式要求。此外,如果您计划为同一问题添加多个响应,请确保包含 user_id。您只能指定一个 user_id 为空的响应:第一个出现的 user_id=None 将被设置为活动的 user_id,而其余的 user_id=None 响应将被丢弃。
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"relevant":{
"value": "YES"
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"content_class":{
"value": ["hate", "violent"]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"preference":{
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"quality":{
"value": 5
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
)
添加记录#
我们可以将记录添加到我们的 FeedbackDataset。花一些时间探索并找到符合您的项目目的的数据。如果您计划使用公共数据,Hugging Face Hub 的数据集页面是一个不错的起点。
提示
如果您正在使用公共数据集,请务必检查许可证,以确保您可以合法地将其用于您的特定用例。
from datasets import load_dataset
# Load and inspect a dataset from the Hugging Face Hub
hf_dataset = load_dataset('databricks/databricks-dolly-15k', split='train')
df = hf_dataset.to_pandas()
df
提示
在将数据添加到数据集之前,请花一些时间检查数据,以防这触发 questions 或 fields 中的更改。
一旦您有一个配置好的 FeedbackRecord 列表,您可以使用 add_records 方法将这些记录添加到本地或远程 FeedbackDataset。
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
records = [
rg.FeedbackRecord(
fields={"question": record["instruction"], "answer": record["response"]}
)
for record in hf_dataset if record["category"]=="open_qa"
]
dataset.add_records(records)
注意
一旦您将记录添加到远程数据集,这些记录应该在 Argilla UI 中可用。如果您看不到它们,请尝试点击侧边栏上的 刷新 按钮。
更新记录#
可以通过简单地修改记录并使用 update_records 方法保存更改来添加、更新和删除现有记录的属性,例如元数据或建议。要了解更多关于这些记录应具有的格式的信息,请查看上面的“定义 FeedbackRecord”部分或相应的指南或端到端教程。
这是一个关于您将如何执行此操作的示例
# Load the dataset
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
modified_records = []
# Loop through the records and make modifications
for record in dataset.records:
# e.g. adding/modifying a metadata field and vectors
record.metadata["my_metadata"] = "new_metadata"
record.vectors["my_vector"] = [0.1, 0.2, 0.3]
# e.g. removing all suggestions and responses
record.suggestions = []
record.responses = []
modified_records.append(record)
dataset.update_records(modified_records)
注意
一旦您在远程数据集中更新记录,更改应该在 Argilla UI 中可用。如果您看不到它们,请尝试点击侧边栏上的 刷新 按钮。
注意
只有字段和 external_id 在添加到数据集后不能从记录中添加、修改或删除,因为这会损害数据集的一致性。
删除记录#
从 v1.14.0 开始,可以从 Argilla 中的 FeedbackDataset 中删除记录。请记住,从 1.14.0 开始,当通过 from_argilla 方法从 Argilla 中拉取 FeedbackDataset 时,返回的实例是一个远程 FeedbackDataset,这意味着所有的添加、更新和删除都直接推送到 Argilla,而无需调用 push_to_argilla 即可将这些操作推送到 Argilla。
第一种选择是在数据集中的单个 FeedbackRecord 上调用 delete 方法,这将从 Argilla 中删除该记录。
# Load the dataset
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
# Delete a specific record
dataset.records[0].delete()
否则,您也可以从现有的 FeedbackDataset 中选择一个或多个记录(这些记录是 Argilla 中的 FeedbackRecord),并调用 delete_records 方法以从 Argilla 中删除它们。
# Load the dataset
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
# List the records to be deleted
records_to_delete = list(dataset.records[:5])
# Delete the list of records from the dataset
dataset.delete_records(records_to_delete)
其他数据集#
注意
本节涵盖的记录类对应于三个数据集:DatasetForTextClassification、 DatasetForTokenClassification 和 DatasetForText2Text。这些将在 Argilla 2.0 中被弃用,并由完全可配置的 FeedbackDataset 类取代。不确定使用哪个数据集?请查看我们关于选择数据集的部分。
添加记录#
Argilla 数据模型的主要组件称为记录。Argilla 中的数据集是这些记录的集合。记录可以是不同类型的,具体取决于当前支持的任务
TextClassificationRecordTokenClassificationRecordText2TextRecord
所有类型记录通用的最关键属性是
text:记录的输入文本(必需);annotation:以特定于任务的方式注释您的记录(可选);prediction:将特定于任务的模型预测添加到记录(可选);metadata:向记录添加一些任意元数据(可选);
记录的其他一些很酷的属性是
在 Argilla 中,记录是使用 Python 脚本、Jupyter notebook 或其他 IDE 中的客户端库以编程方式创建的。
让我们看看如何创建和上传基本记录到 Argilla Web 应用程序(确保 Argilla 已经安装在您的机器上,如设置指南中所述)。
我们支持 Argilla 生态系统中专注于 NLP 的不同任务:文本 分类、 Token 分类 和 Text2Text。
import argilla as rg
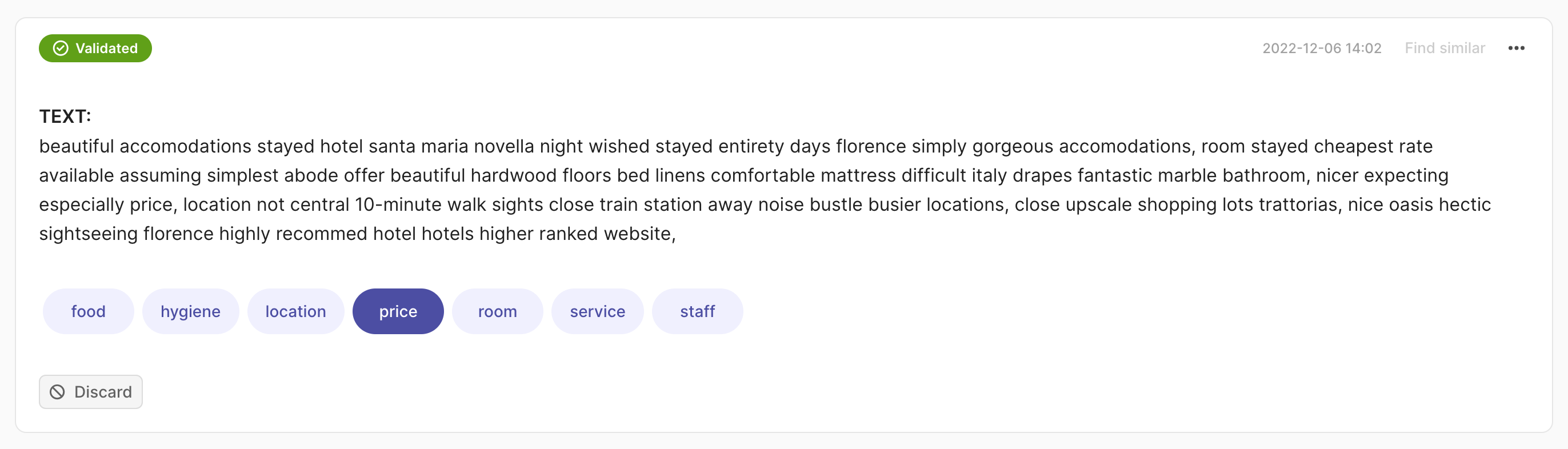
rec = rg.TextClassificationRecord(
text="beautiful accommodations stayed hotel santa... hotels higher ranked website.",
prediction=[("price", 0.75), ("hygiene", 0.25)],
annotation="price"
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
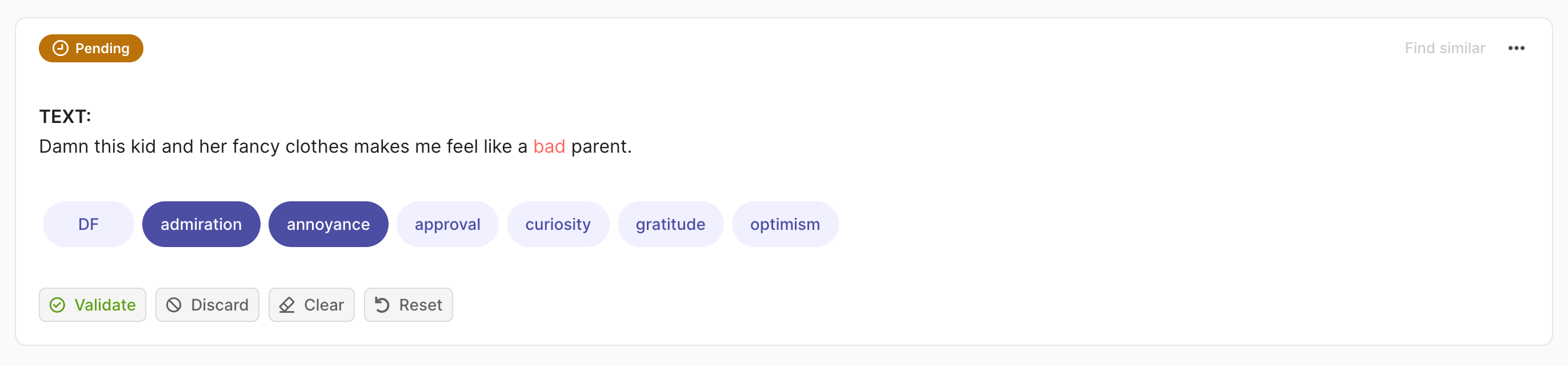
rec = rg.TextClassificationRecord(
text="damn this kid and her fancy clothes make me feel like a bad parent.",
prediction=[("admiration", 0.75), ("annoyance", 0.25)],
annotation=["price", "annoyance"],
multi_label=True
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
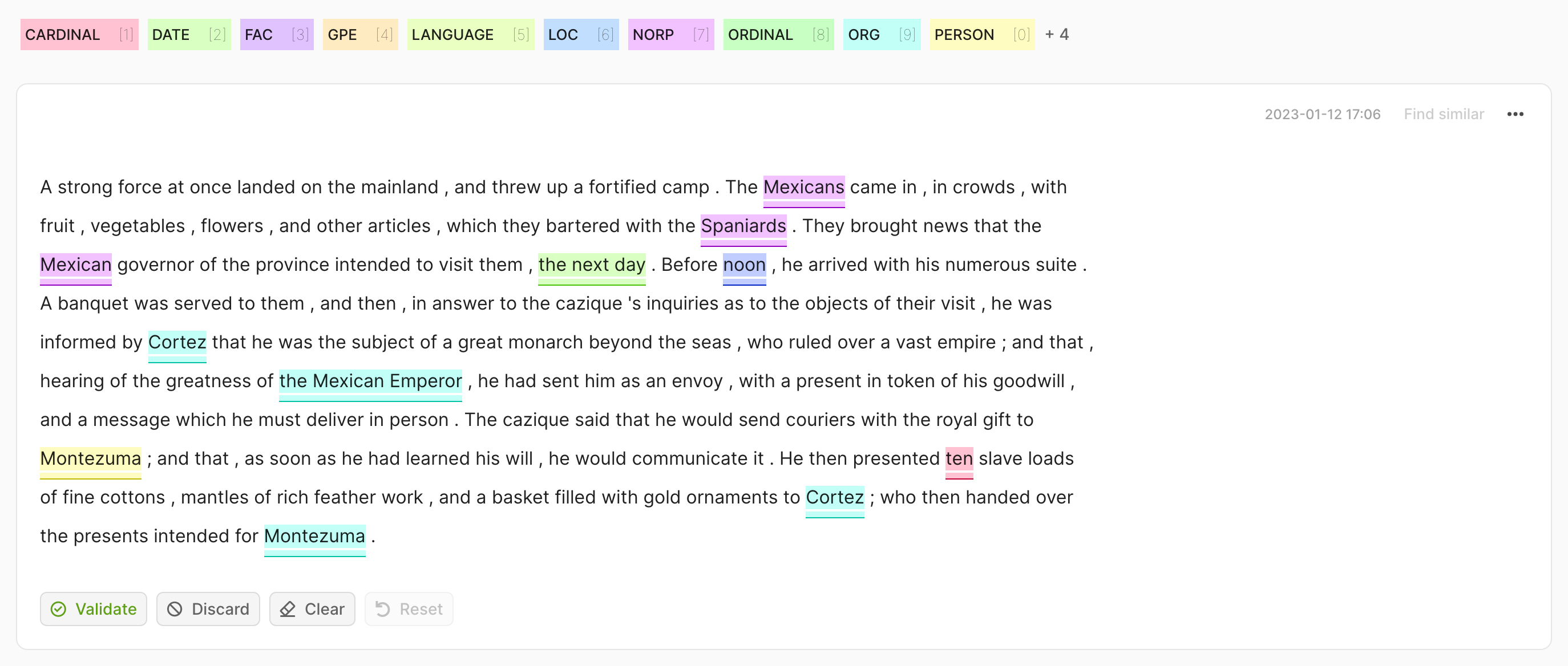
rec = rg.TokenClassificationRecord(
text="Michael is a professor at Harvard",
tokens=["Michael", "is", "a", "professor", "at", "Harvard"],
prediction=[("NAME", 0, 7, 0.75), ("LOC", 26, 33, 0.8)],
annotation=[("NAME", 0, 7), ("LOC", 26, 33)],
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
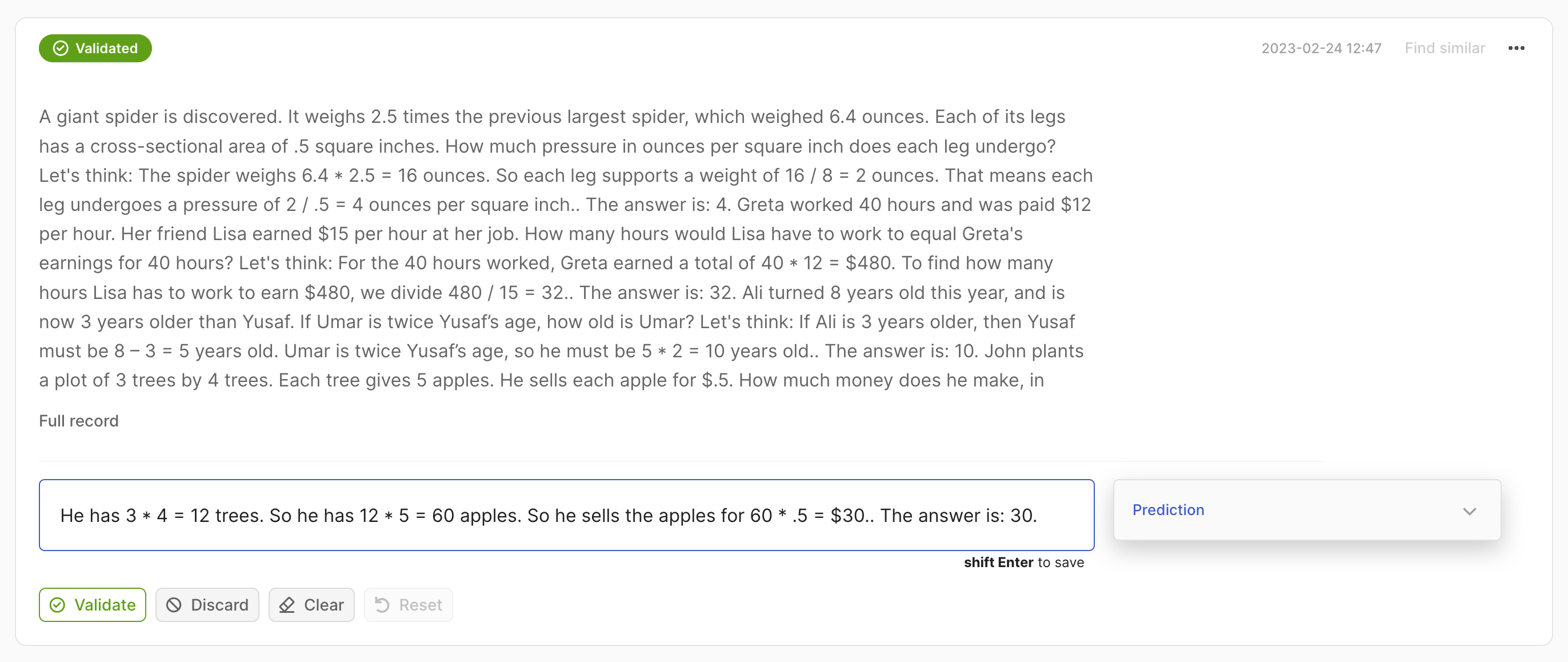
rec = rg.Text2TextRecord(
text="A giant spider is discovered... how much does he make in a year?",
prediction=["He has 3*4 trees. So he has 12*5=60 apples."],
)
rg.log(records=rec, name="my_dataset")
更新记录#
可以使用我们的 Python API 更新 Argilla 数据集中的记录。这种方法的工作方式与普通数据库中的 upsert 相同,基于记录 id。您可以更新任何任意参数,如果您使用原始记录的 id,它们将被覆盖。
import argilla as rg
# Read all records in the dataset or define a specific search via the `query` parameter
record = rg.load("my_dataset")
# Modify first record metadata (if no previous metadata dict, you might need to create it)
record[0].metadata["my_metadata"] = "I'm a new value"
# Log record to update it, this will keep everything but add my_metadata field and value
rg.log(name="my_dataset", records=record[0])
删除记录#
您可以通过将记录的 id 传递到 rg.delete_records() 函数或使用与记录匹配的查询来删除记录。了解更多此处。
## Delete by id
import argilla as rg
rg.delete_records(name="example-dataset", ids=[1,3,5])
## Discard records by query
import argilla as rg
rg.delete_records(name="example-dataset", query="metadata.code=33", discard_only=True)