💫 探索和分析 spaCy NER 预测#
在本教程中,我们将学习如何记录 spaCy 命名实体识别 (NER) 预测。
这对于以下方面很有用:
🧐评估预训练模型。
🔎在开发和生产过程中发现常见错误。
📈随着时间推移,使用 Argilla 注释模式改进您的管道。
🎮使用 Argilla 与 Kibana 的集成来监控您的模型预测
让我们开始吧!
简介#
在本教程中,我们将学习如何轻松探索和分析 spaCy NER 管道。
我们将从 Hugging Face Hub 加载 Gutenberg Time 数据集,并使用基于 Transformer 的 spaCy 模型来检测此数据集中的实体,并将检测到的实体记录到 Argilla 数据集中。此数据集可用于探索预测质量,并通过更正、添加和验证实体来创建新的训练集。
然后,我们将使用较小的 spaCy 模型来检测实体,并将检测到的实体记录到同一个 Argilla 数据集中,以比较其与先前模型的预测。此外,作为奖励,我们将在更具挑战性的数据集 IMDB 上使用 Argilla 和 spaCy。
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。 有两种主要的部署和运行 Argilla 的选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上拥有帐户,则只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地计算机上运行 Argilla,建议使用此选项。 请注意,此选项仅允许您在本地运行教程,而不能与外部 notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。 有两种运行它的选项
使用此页面顶部的“在 Colab 中打开”按钮。 此选项允许您直接在 Google Colab 上运行 notebook。 不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。 此选项允许您下载 notebook 并在本地计算机或您选择的 Jupyter Notebook 工具上运行它。
[ ]:
%pip install argilla -qqq
%pip install torch -qqq
%pip install datasets "spacy[transformers]~=3.0" protobuf -qqq
!python -m spacy download en_core_web_trf
!python -m spacy download en_core_web_sm
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含所需的导入
[ ]:
from datasets import load_dataset
import pandas as pd
import spacy
from tqdm.auto import tqdm
启用遥测#
我们从您与我们教程的互动中获得宝贵的见解。 为了改进自身,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。 虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。 有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
注意
如果您想跳过运行 spaCy 管道,您也可以直接从 Hugging Face Hub 加载生成的 Argilla 记录,并继续将它们记录到 Argilla Web 应用程序的教程。 例如
records = rg.read_datasets(
load_dataset("argilla/gutenberg_spacy_ner", split="train"),
task="TokenClassification",
)
本教程的 Argilla 记录在名称 “argilla/gutenberg_spacy_ner” 和 “argilla/imdb_spacy_ner” 下可用。
我们的数据集#
对于本教程,我们将使用 Hugging Face Hub 中的 Gutenberg Time 数据集。 它包含 52,183 部小说的数据集中的所有显式时间参考,这些小说的全文可通过 Project Gutenberg 获得。 从小说摘录中,我们肯定会找到一些 NER 实体。
[2]:
dataset = load_dataset("gutenberg_time", split="train", streaming=True)
# Let's have a look at the first 5 examples of the train set.
pd.DataFrame(dataset.take(5))
[2]:
| guten_id | hour_reference | time_phrase | is_ambiguous | time_pos_start | time_pos_end | tok_context | |
|---|---|---|---|---|---|---|---|
| 0 | 4447 | 5 | 五点钟 | True | 145 | 147 | 我穿过她走过的地面,注意到... |
| 1 | 4447 | 12 | 冬日中午的降临 | True | 68 | 74 | 如此深刻地沉浸在沉思中 w... |
| 2 | 28999 | 12 | 中午 | True | 46 | 47 | 亨顿在这里,现在是我们... |
| 3 | 28999 | 12 | 中午 | True | 133 | 134 | 她在其中经历了许多悲伤和考验... |
| 4 | 28999 | 0 | 午夜 | True | 43 | 44 | 珍妮在窗户边加入了她的朋友...。 |
将 spaCy NER 实体记录到 Argilla 中#
让我们实例化一个 spaCy transformer nlp 管道,并将其应用于我们数据集中的前 50 个示例,收集tokens 和 NER 实体。
[ ]:
nlp = spacy.load("en_core_web_trf")
# Creating an empty record list to save all the records
records = []
# Iterate over the first 50 examples of the Gutenberg dataset
for record in tqdm(list(dataset.take(50))):
# We only need the text of each instance
text = record["tok_context"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [(ent.label_, ent.start_char, ent.end_char) for ent in doc.ents]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Argilla TokenClassificationRecord list
records.append(
rg.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="en_core_web_trf",
)
)
rg.log(records=records, name="gutenberg_spacy_ner")
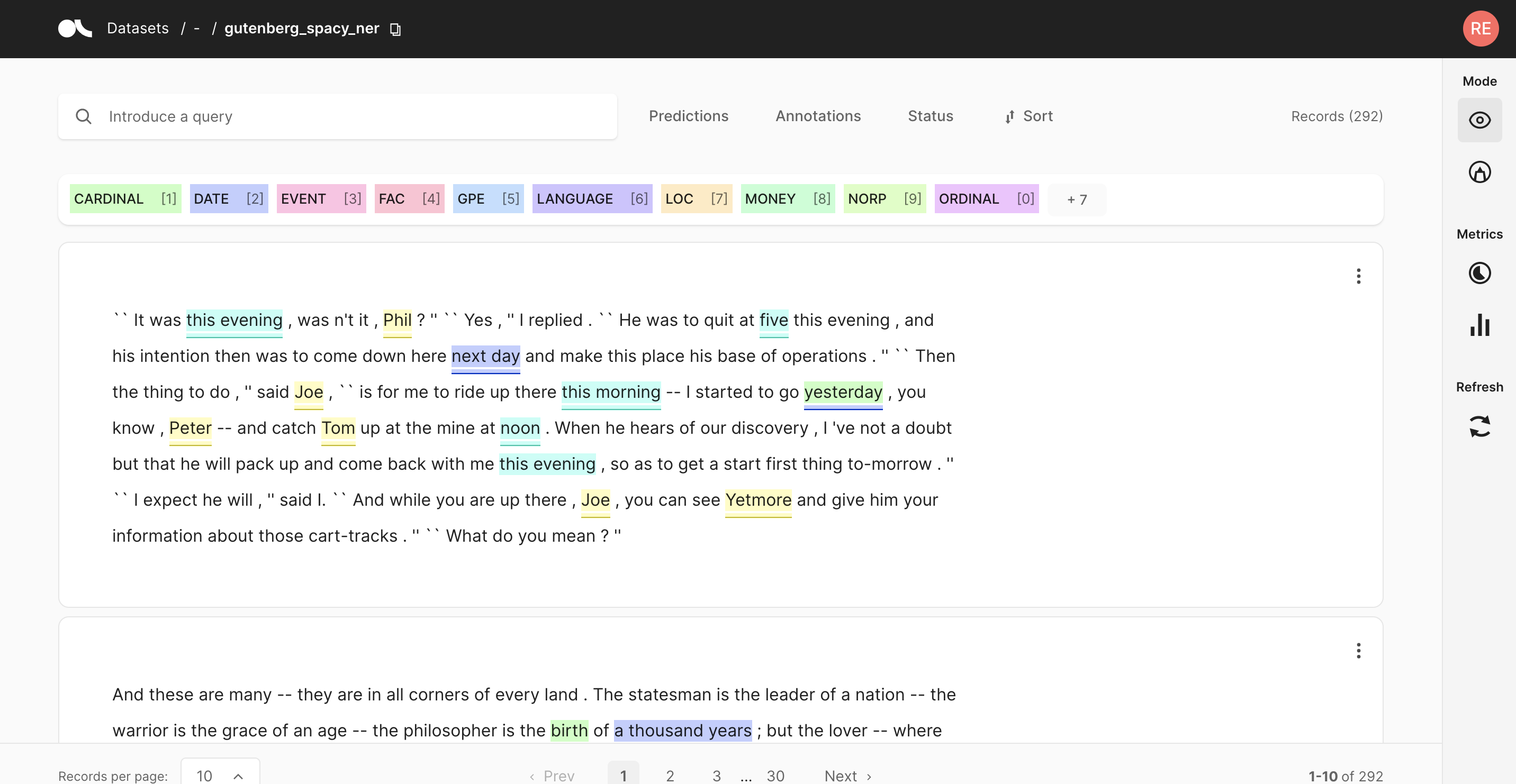
如果您转到 Argilla 中的 gutenberg_spacy_ner 数据集,您可以探索此模型的预测。
您可以
过滤包含特定实体类型的记录,
查看每个实体的最常见“提及”或表面形式。 提及是特定实体类型的字符串值,例如,“1 个月”可以是持续时间实体的提及。 这对于错误分析很有用,可以快速查看潜在问题和有问题的实体类型,
使用自由文本搜索查找包含特定单词的记录,
并验证、包含或拒绝特定的实体注释以构建新的训练集。
现在让我们与更小但更高效的预训练模型进行比较。
[ ]:
nlp = spacy.load("en_core_web_sm")
# Creating an empty record list to save all the records
records = []
# Iterate over 10000 examples of the Gutenberg dataset
for record in tqdm(list(dataset.take(10000))):
# We only need the text of each instance
text = record["tok_context"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [(ent.label_, ent.start_char, ent.end_char) for ent in doc.ents]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Argilla TokenClassificationRecord list
records.append(
rg.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="en_core_web_sm",
)
)
rg.log(records=records, name="gutenberg_spacy_ner")
探索和比较 en_core_web_sm 和 en_core_web_trf 模型#
如果您转到您的 gutenberg_spacy_ner 数据集,您可以探索和比较两个模型的结果。
要仅查看特定模型的预测,您可以使用 predicted by 过滤器,该过滤器来自您的 TextClassificationRecord 的 prediction_agent 参数。
探索 IMDB 数据集#
到目前为止,spaCy 预训练模型似乎都运行良好。 让我们尝试一个更具挑战性的数据集,它与这些模型训练的原始训练数据更加不同。
[ ]:
imdb = load_dataset("imdb", split="test")
records = []
for record in tqdm(imdb.select(range(5000))):
# We only need the text of each instance
text = record["text"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [(ent.label_, ent.start_char, ent.end_char) for ent in doc.ents]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Argilla TokenClassificationRecord list
records.append(
rg.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="en_core_web_sm"
)
)
rg.log(records=records, name="imdb_spacy_ner")
探索此数据集突出了针对特定领域进行微调的需求。
例如,如果我们检查 Person 的最常见提及,我们会发现两个高频错误分类的实体:gore(电影类型)和 Oscar(奖项)。
您可以使用过滤器和搜索框轻松检查每个示例。
总结#
在本教程中,您学习了如何使用 Argilla 记录和探索不同的 spaCy NER 模型。 现在您可以
使用 Kibana 构建自定义仪表板,以监控和可视化 spaCy 模型。
使用预训练的 spaCy 模型构建训练集。
附录:将数据集记录到 Hugging Face Hub#
在这里,我们将向您展示如何将 Argilla 数据集(记录)推送到 Hugging Face Hub 的示例。 这样,您可以有效地版本控制您的任何 Argilla 数据集。
[ ]:
records = rg.load("gutenberg_spacy_ner")
records.to_datasets().push_to_hub("<name of the dataset on the HF Hub>")