🔦 语义搜索#
本指南概述了语义搜索功能。自 1.19.0 版本起,Argilla 支持向反馈数据集添加向量(其他数据集自 1.2.0 版本起已包含此功能),这些向量可用于查找与给定记录最相似的记录。此功能使用向量或语义搜索,并结合了更传统的搜索(基于关键词和过滤器)。
向量搜索利用机器学习通过将项目(文本、视频、图像等)嵌入到向量空间中来捕获丰富的语义特征,然后可以使用这些向量空间来查找“语义上”相似的项目。
在本指南中,你将找到如何:
设置你的 Elasticsearch 或 Opensearch 端点以支持向量搜索。
将文本编码为 Argilla 记录的向量。
使用语义搜索。
下一节概述了语义搜索在 Argilla 中的工作原理。
工作原理#
Argilla 中的语义搜索工作原理如下:
一个或多个向量可以包含在 Argilla 记录的
vectors字段中。vectors字段接受一个字典,其中keys表示名称,values包含实际向量。之所以如此,是因为某些用例可能需要使用多个向量。请注意,对于FeedbackDataset,你还需要在数据集中配置VectorSettings。向量在索引时存储,一旦记录通过
add_records或update_records添加到FeedbackDataset中,或者在旧数据集中通过rg.log添加。如果你的数据集中存储了向量,则可以在 Argilla UI 和 Python SDK 中使用语义搜索功能。
在未来的版本中,可能会开发嵌入服务,以简化步骤 1 和 2,并自动将向量与记录关联起来。
注意
用户完全可以自行决定使用哪种编码或嵌入机制来生成这些向量。在本文件的“编码文本字段”部分,你将找到有关此过程的多个示例和详细信息,其中使用了开源库(例如,Hugging Face)以及付费服务(例如,Cohere 或 OpenAI)。
目前,Argilla 仅使用向量搜索来搜索给定向量的相似记录(最近邻)。这可以从 Argilla UI 以及 Python 客户端中利用。在未来,向量搜索也可能被用于使用 Argilla UI 的自由文本查询。
设置向量搜索支持#
为了使用此功能,你应该使用 Elasticsearch 至少 8.5.x 版本或 Opensearch 2.4.0 版本。我们在 Argilla Github 仓库的根目录中提供了预配置的 docker-compose 文件。
警告
如果你的 Argilla 正在使用 Elasticsearch 7.1.0 运行,则需要迁移到至少 8.5.x 版本。请查看“从 Elasticsearch 7.1.0 迁移到 8.5”部分。
Elasticsearch 后端#
如果你没有正在运行的 Elasticsearch 或 Opensearch 的其他实例,或者不想保留以前的 Argilla 数据集,则可以通过下载 docker-compose.elasticsearch.yaml 并运行以下命令来启动 Elasticsearch 的全新实例:
docker-compose -f docker-compose.elasticsearch.yaml up
从 7.1.0 迁移到 8.5#
警告
如果你的 Argilla 正在使用 Elasticsearch 7.1.0 运行,则需要迁移到至少 8.5.x 版本。在按照下面描述的步骤操作之前,请仔细阅读官方 Elasticsearch 迁移指南。
为了从 Elasticsearch 7.1.0 迁移并保留你的数据集,你可以按照以下步骤操作:
停止你当前的 Elasticsearch 服务(我们假设为
docker-compose设置进行迁移)。在你的
docker-compose中将 Elasticsearch 镜像设置为 7.17.x。再次启动 Elasticsearch 服务。
一旦启动并运行,再次停止它,并将 Elasticsearch 镜像设置为 8.5.x。
最后,再次启动 Elasticsearch 服务。数据应该已正确迁移。
服务启动后,你可以使用 python -m argilla server start 启动 Argilla 服务器。
Opensearch 后端#
如果你没有正在运行的 Elasticsearch 或 Opensearch 的其他实例,或者不想保留以前的 Argilla 数据集,则可以通过下载 docker-compose.opensearch.yaml 文件 并运行以下命令来启动 Opensearch 的全新实例:
docker-compose -f docker-compose.opensearch.yaml up
服务启动后,你可以使用 ARGILLA_SEARCH_ENGINE=opensearch python -m argilla server start 启动 Argilla 服务器。
警告
对于 OpenSearch 中的向量搜索,应用的过滤使用 post_filter 步骤,因为存在一个错误,该错误导致使用 Argilla 的过滤 + knn 查询失败。请参阅 https://github.com/opensearch-project/k-NN/issues/1286
当将过滤与此引擎的向量搜索结合使用时,这可能会导致意外的结果。
向你的数据添加向量#
在利用语义搜索之前,首先也是最重要的事情是将文本转换为数值表示:向量。实际上,你可以将向量视为数字的数组或列表。你可以使用前面提到的 vectors 字段将此数字列表与 Argilla 记录关联起来。但问题是:你如何创建这些向量?
多年来,已经使用了许多方法将文本转换为数值表示。目标是“编码”含义、上下文、主题等。这可以用于查找“语义上”相似的文本。其中一些方法是 LSA(潜在语义分析)、tf-idf、LDA(潜在狄利克雷分布)或 doc2Vec。更新的方法属于“神经”方法类别,这些方法利用大型神经网络的力量将文本嵌入到密集向量中(大量的实数数组)。这些方法已经证明了捕获语义特征的强大能力。这些方法正在推动一波新技术浪潮,这些技术属于神经搜索、语义搜索或向量搜索等类别。这些方法中的大多数都涉及使用大型语言模型来编码文本片段的完整上下文,例如句子、段落,以及最近更大的文档。
注意
在 Argilla 的上下文中,我们有意使用术语 vector 而不是 embedding,以强调用户可以使用神经方法以外的方法,这些方法可能计算成本更低,或者对他们的用例更有用。
在接下来的章节中,我们将展示如何使用不同的模型和服务编码文本,以及如何将它们添加到 Argilla 记录中。
警告
如果你在使用 rg.log 记录具有大向量的记录时遇到问题,我们建议你使用较小的 chunk_size,如下面的示例所示。
Sentence Transformers#
SentenceTransformers 是一个 Python 框架,用于最先进的句子、文本和图像嵌入。在 Hugging Face Hub 上有数十种 预训练模型可用。
鉴于其基础且开源的通用性,我们已决定添加与 SentenceTransformers 的原生集成。此集成允许你使用基于 sentence-transformers 库的 SentenceTransformersExtractor 轻松地将嵌入添加到你的记录或数据集中。此集成可以在此处找到。
OpenAI Embeddings#
OpenAI 提供了一个名为 Embeddings 的 API 端点,用于获取给定输入的向量表示,该表示可以轻松地被机器学习模型和算法使用。
警告
由于 Elasticsearch 和 Opensearch 基于 Lucene 的引擎的向量维度限制,目前你只能使用 text-similarity-ada-001 模型,该模型生成 1024 维的向量。
下面的代码将从 Hub 加载数据集,编码 text 字段,并创建 vectors 字段,该字段将仅包含一个键 (openai),使用 Embeddings 端点。
要运行以下代码,你需要使用 pip 安装 openai 和 datasets:pip install openai datasets。
你还需要如下所示设置你的 OpenAI API 密钥。
import openai
from datasets import load_dataset
openai.api_key = "<your api key goes here>"
# Load dataset
dataset = load_dataset("banking77", split="test")
def get_embedding(texts, model="text-similarity-ada-001"):
response = openai.Embedding.create(input = texts, model=model)
vectors = [item["embedding"] for item in response["data"]]
return vectors
# Encode text. Get only 500 vectors for testing, remove the select to do the full dataset
dataset = dataset.select(range(500)).map(lambda batch: {"vectors": get_embedding(batch["text"])}, batch_size=16, batched=True)
# Turn vectors into a dictionary
dataset = dataset.map(
lambda r: {"vectors": {"text-similarity-ada-001": r["vectors"]}}
)
Cohere Co.Embed#
Cohere Co.Embed 是 Cohere 的一个 API 端点,它接收一段文本并将其转换为向量嵌入。
警告
由于 Elasticsearch 和 Opensearch 基于 Lucene 的引擎的向量维度限制,目前你只能使用 small 模型,该模型生成 1024 维的向量。
下面的代码将从 Hub 加载数据集,编码 text 字段,并创建 vectors 字段,该字段将仅包含一个键 (cohere),使用 Embeddings 端点。
要运行以下代码,你需要使用 pip 安装 cohere 和 datasets:pip install cohere datasets。
你还需要如下所示设置你的 Cohere API 密钥。
import cohere
api_key = "<your api key goes here>"
co = cohere.Client(api_key)
# Load dataset
dataset = load_dataset("banking77", split="test")
def get_embedding(texts):
return co.embed(texts, model="small").embeddings
# Encode text. Get only 1000 vectors for testing, remove the select to do the full dataset
dataset = dataset.select(range(1000)).map(lambda batch: {"vectors": get_embedding(batch["text"])}, batch_size=16, batched=True)
# Turn vectors into a dictionary
dataset = dataset.map(
lambda r: {"vectors": {"cohere-embed": r["vectors"]}}
)
配置你的数据集#
我们的数据集现在包含一个 vectors 字段,其中包含由我们首选模型生成的嵌入向量。此数据集可以通过以下方式转换为 Argilla 数据集:
让我们首先配置一个包含向量设置的反馈数据集:
import argilla as rg
local_ds = rg.FeedbackDataset(
fields=[
rg.TextField(name="text")
],
questions=[
rg.MultiLabelQuestion(
name="topic",
title="Select the topics mentioned in the text:",
labels=dataset.info.features['label'].names, #these are the labels in the original dataset
)
],
vectors_settings=[
rg.VectorSettings(name=key, dimensions=len(value))
for key,value in dataset[0]["vectors"].items()
]
)
remote_ds = local_ds.push_to_argilla("banking77", workspace="admin")
现在我们可以创建记录并将它们添加到数据集中:
records = [
rg.FeedbackRecord(
fields={"text": rec["text"]},
vectors=rec["vectors"]
)
for rec in dataset
]
remote_ds.add_records(records)
你可以使用 DatasetForTextClassification.from_datasets 方法。然后,可以将此数据集记录到 Argilla 中,如下所示:
import argilla as rg
rg_ds = rg.DatasetForTextClassification.from_datasets(dataset, annotation="label")
rg.log(
name="banking77",
records=rg_ds,
chunk_size=50,
)
使用语义搜索#
本节介绍如何从 Argilla UI 和 Argilla Python 客户端使用语义搜索功能。
Argilla UI#
在反馈数据集中,你还可以根据记录与另一条记录的相似性来检索记录。为此,请确保已将 vector_settings 添加到你的 数据集配置,并确保你的 记录包含向量。
在 UI 中,转到你想要用于语义搜索的记录,然后单击记录卡右上角的 查找相似。如果存在多个向量,系统将要求你选择要使用的向量。你还可以选择你想要最相似还是最不相似的记录,以及你想要查看的结果数量。
你可以随时展开或折叠用作参考的搜索记录。如果要撤消搜索,只需单击参考记录旁边的叉号。
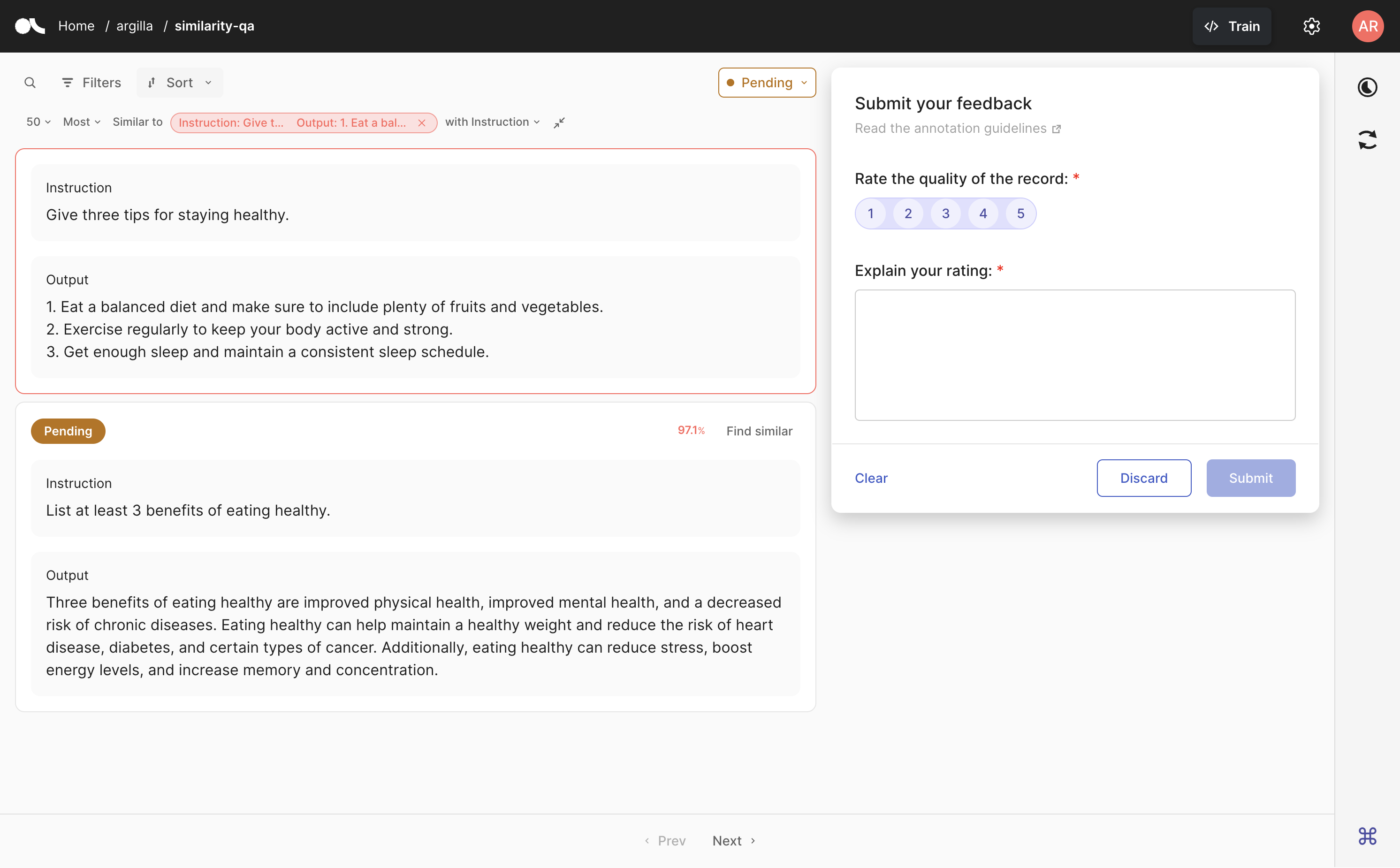
在 Argilla UI 中,可以选择具有附加向量的记录,通过单击“查找相似”按钮来启动语义搜索。标注后,可以按下“移除相似记录过滤器”按钮来关闭特定搜索并继续你的标注会话。
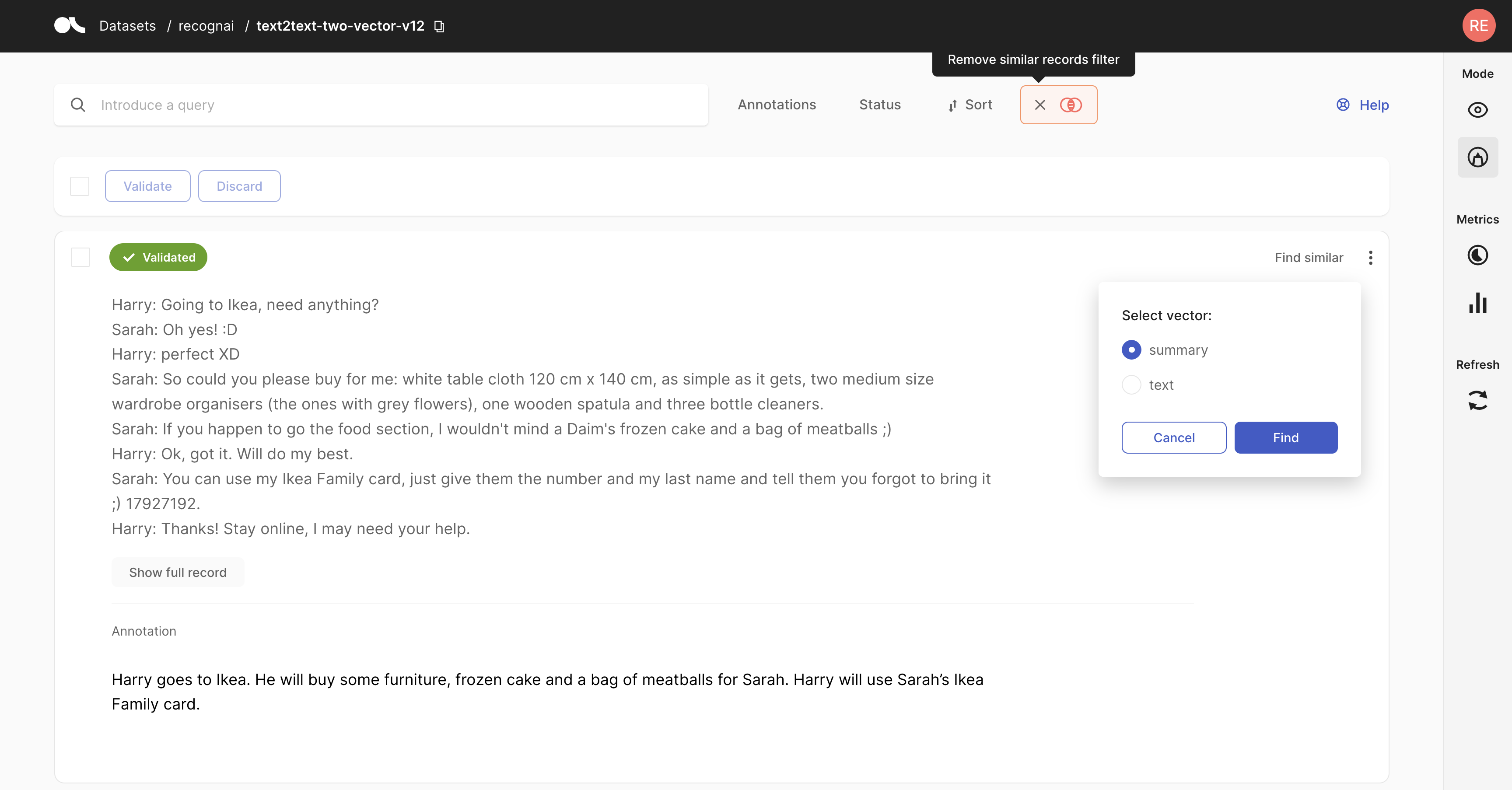
Argilla Python 客户端#
要查找与给定向量相似的记录,首先我们需要生成该参考向量。让我们看看如何使用我们之前使用的不同框架来实现这一点:
警告
为了获得良好的结果,请确保你使用相同的编码器模型来生成用于查询的向量。例如,如果你的数据集已使用来自 sentence transformers 的 bge-small-en 模型进行编码,请确保使用相同的模型来编码要用于查询的文本。另一种选择是使用数据集中已存在的记录,该记录已包含向量。
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("BAAI/bge-small-en", device="cpu")
vector = encoder.encode("I lost my credit card. What should I do?").tolist()
vector = openai.Embedding.create(
input = ["I lost my credit card. What should I do?"],
model="text-similarity-ada-001"
)["data"][0]["embedding"]
vector = co.embed(["I lost my credit card. What should I do?"], model="small").embeddings[0]
现在我们有了参考向量,我们可以在 Python SDK 中进行语义搜索:
在 Python SDK 中,你还可以使用 find_similar_records 方法获取与给定嵌入在语义上接近的反馈记录列表。以下是此函数的参数:
vector_name:要在搜索中使用的向量的name。value:用于相似性搜索的向量,形式为List[float]。必须包含value或record。record:要用作搜索一部分的FeedbackRecord。必须包含value或record。max_results(可选):此搜索的最大结果数。默认为50。
这将返回一个元组列表,其中包含记录及其相似度得分(介于 0 和 1 之间)。
ds = rg.FeedbackDataset.from_argilla("my_dataset", workspace="my_workspace")
# using text embeddings
similar_records = ds.find_similar_records(
vector_name="my_vector",
value=embedder_model.embeddings("My text is here")
# value=embedder_model.embeddings("My text is here").tolist() # for numpy arrays
)
# using another record
similar_records = ds.find_similar_records(
vector_name="my_vector",
record=ds.records[0],
max_results=5
)
# work with the resulting tuples
for record, score in similar_records:
...
你还可以像这样组合过滤器和语义搜索:
similar_records = (dataset
.filter_by(metadata=[rg.TermsMetadataFilter(values=["Positive"])])
.find_similar_records(vector_name="vector", value=model.encode("Another text").tolist())
)
rg.load 方法包含一个 vector 参数,该参数可用于检索与给定向量相似的记录,以及一个 limit 参数,用于指示要检索的记录数。此参数接受一个元组,其中包含目标向量的键(这应该与 vectors 字典的键之一匹配)和查询向量本身。
此外,vector 参数可以与 query 参数结合使用,以将向量搜索与传统搜索相结合。
ds = rg.load(
name="banking77-openai",
vector=("my-vector-name", vector),
limit=20,
query="annotated_as:card_arrival"
)