🧑💻 创建和更新数据集#
反馈数据集#
注意
本节中介绍的数据集类是 FeedbackDataset。这个完全可配置的数据集将在 Argilla 2.0 中取代 DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。不确定要使用哪个数据集?请查看我们关于选择数据集的部分。
反馈任务数据集允许你组合多种不同类型的问题,因此第一步是定义你的项目的目标以及你需要的用于达成目标的数据和反馈类型。有了这些信息,你可以开始配置数据集并使用 Python SDK 格式化记录。下面的图片提供了通用的逐步概述。对于一些端到端示例,你可以查看我们的教程页面。

本指南将引导你完成配置 FeedbackDataset 所需的所有元素。有关如何添加记录、元数据、向量或建议和回复的更多信息,请参阅相应的指南。
注意
要遵循本指南中的步骤,你首先需要连接到 Argilla。查看我们的速查表,了解如何操作。
配置数据集#
Argilla 中的记录指的是需要标注的数据项,可以包含一个或多个 fields,即为了完成标注任务将在 UI 中向用户展示的信息片段。例如,在指令数据集的情况下,这可以是提示和输出对。此外,记录将包含标注者需要回答的 questions 和帮助他们完成任务的指南。
所有这些都可以使用 Python SDK 通过自定义配置进行完全配置。但是,我们也可以使用预制的Hugging Face 数据集或开箱即用的任务模板。
Hugging Face Hub 数据集#
Argilla 喜爱 Hugging Face,并与其生态系统紧密集成。要开始使用 FeedbackDataset,我们可以直接从 Hugging Face datasets hub 检索 Argilla 兼容的数据集。这些数据集已经包含完整的配置和数据。
import argilla as rg
ds = rg.FeedbackDataset.from_huggingface("<huggingface_dataset_id>")
任务模板#
FeedbackDataset 有一组预定义的任务模板,你可以使用这些模板快速设置你的数据集。这些模板包括任务所需的 fields 和 questions,以及提供给标注者的 guidelines。此外,你可以使用自定义配置来定制 fields、questions、guidelines、metadata 和 vectors,以满足你的特定需求。
import argilla as rg
ds = rg.FeedbackDataset.for_text_classification(
labels=["positive", "negative"],
multi_label=False,
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="text", use_markdown=True)
# ],
# questions=[
# LabelQuestion(name="label", labels=["positive", "negative"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_summarization(
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="text", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="summary", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_translation(
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="source", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="target", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_natural_language_inference(
labels=None
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="premise", use_markdown=True),
# TextField(name="hypothesis", use_markdown=True)
# ],
# questions=[
# LabelQuestion(name="label", labels=["entailment", "neutral", "contradiction"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_sentence_similarity(
rating_scale=7,
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="sentence-1", use_markdown=True),
# TextField(name="sentence-2", use_markdown=True)
# ],
# questions=[
# RatingQuestion(name="similarity", values=[1, 2, 3, 4, 5, 6, 7])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_question_answering(
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="question", use_markdown=True),
# TextField(name="context", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="answer", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_supervised_fine_tuning(
context=True,
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="response", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_preference_modeling(
number_of_responses=2,
context=False,
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True),
# TextField(name="response1", use_markdown=True),
# TextField(name="response2", use_markdown=True),
# ],
# questions=[
# RankingQuestion(name="preference", values=["Response 1", "Response 2"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>"
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_proximal_policy_optimization(
rating_scale=7,
context=True,
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="response", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_direct_preference_optimization(
number_of_responses=2,
context=False,
use_markdown=True,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True),
# TextField(name="response1", use_markdown=True),
# TextField(name="response2", use_markdown=True),
# ],
# questions=[
# RankingQuestion(name="preference", values=["Response 1", "Response 2"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_retrieval_augmented_generation(
number_of_retrievals=1,
rating_scale=7,
use_markdown=False,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="query", use_markdown=False),
# TextField(name="retrieved_document_1", use_markdown=False),
# ],
# questions=[
# RatingQuestion(name="rating_retrieved_document_1", values=[1, 2, 3, 4, 5, 6, 7]),
# TextQuestion(name="response", use_markdown=False),
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_multi_modal_classification(
labels=["video", "audio", "image"],
multi_label=False,
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="content", use_markdown=True, required=True),
# ],
# questions=[
# LabelQuestion(name="label", labels=["video", "audio", "image"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_multi_modal_transcription(
guidelines=None,
metadata_properties=None,
vectors_settings=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="content", use_markdown=True, required=True),
# ],
# questions=[
# TextQuestion(name="description", use_markdown=True, required=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# vectors_settings="<Vectors Settings>",
# )
在初始化 FeedbackDataset 模板之后,我们仍然可以更改 fields、questions、guidelines、metadata 和 vectors 以满足我们的特定需求,你可以参考更新配置部分。
自定义配置#
定义 fields#
Argilla 中的记录指的是需要标注的数据项,可以包含一个或多个字段,即为了完成标注任务将在 UI 中向用户展示的信息片段。例如,在指令数据集的情况下,这可以是提示和输出对。
作为 FeedbackDataset 配置的一部分,你将需要指定要在记录卡中显示的字段列表。截至 Argilla 1.8.0,我们仅支持一种字段类型,TextField,这是一个纯文本字段。我们计划在 Argilla 未来的版本中扩展支持的字段类型范围。
你可以使用 Python SDK 定义字段,并提供以下参数
name:字段的名称,将在内部可见。title(可选):字段的名称,将在 UI 中显示。默认为name值,但首字母大写。required(可选):字段是否为必需。默认为True。请注意,至少一个字段必须是必需的。use_markdown(可选):指定是否要在 UI 中渲染 markdown。默认为False。如果将其设置为True,你将能够使用所有 Markdown 功能进行文本格式化,以及嵌入多媒体内容和 PDF。要深入了解详细信息,请参阅此教程。
注意
Markdown 中的多媒体功能已在此处,但仍处于实验阶段。在我们探索早期阶段时,由于 ElasticSearch 的限制,文件大小受到限制,并且可视化和加载时间可能因你的浏览器而异。我们正在努力改进这一点,并欢迎你的反馈和建议!
fields = [
rg.TextField(name="question", required=True),
rg.TextField(name="answer", required=True, use_markdown=True),
]
注意
UI 中字段的顺序遵循这些字段添加到 Python SDK 中 fields 属性的顺序。
定义 questions#
要收集数据集的反馈,你需要提出问题。反馈任务当前支持以下问题类型
LabelQuestion:这些问题要求标注者从选项列表中选择一个标签。此类型适用于文本分类任务。在 UI 中,LabelQuestion的标签将具有圆形。MultiLabelQuestion:这些问题要求标注者从选项列表中选择所有适用的标签。此类型适用于多标签文本分类任务。在 UI 中,MultiLabelQuestion的标签将具有方形。RankingQuestion:此问题要求标注者对选项列表进行排序。它有助于收集关于一组选项的偏好或相关性的信息。允许并列,并且所有选项都需要排名。RatingQuestion:这些问题要求标注者从整数值列表中选择一个选项。此类型适用于收集数值评分。SpanQuestion:在这里,要求标注者选择特定字段的文本的一部分并对其应用标签。此问题类型适用于命名实体识别或信息提取任务。TextQuestion:这些问题为标注者提供了一个自由文本区域,他们可以在其中输入任何文本。此类型适用于收集自然语言数据,例如更正或解释。
你可以使用 Python SDK 定义你的问题并设置以下配置
name:问题的名称,将在内部可见。title(可选):问题的名称,将在 UI 中显示。默认为name值,但首字母大写。required(可选):问题是否为必需。默认为True。请注意,至少一个问题必须是必需的。description(可选):要在 UI 中问题工具提示中显示的文本。你可以使用它为标注者提供更多上下文或信息。
以下参数适用于特定问题类型
values:在RatingQuestion中,这将是任何表示标注者可以选择的选项的唯一整数列表。这些值必须在 [0, 10] 范围内定义。在RankingQuestion中,values 将是一个字符串列表,其中包含他们需要排名的选项。如果你希望选项的文本在 UI 中和内部不同,你可以传递一个字典,其中键是内部名称,值是要在 UI 中显示的文本。labels:在LabelQuestion、MultiLabelQuestion和SpanQuestion中,这是一个字符串列表,其中包含这些问题的选项。如果你希望标签的文本在 UI 中和内部不同,你可以传递一个字典,其中键是内部名称,值将是在 UI 中显示的文本。field:SpanQuestion始终附加到特定字段。在这里,你应该传递一个字符串,其中包含SpanQuestion的标签应使用的字段的名称。allow_overlapping:在SpanQuestion中,此值指定是否允许重叠跨度。默认设置为False。设置为True以允许重叠跨度。visible_labels(可选):在LabelQuestion、MultiLabelQuestion和SpanQuestion中,这是在 UI 中乍一看可见的标签数量。默认情况下,UI 将显示 20 个标签并折叠其余标签。设置你喜欢的数字以更改此限制,或设置visible_labels=None以显示所有选项。labels_order(可选):在MultiLabelQuestion中,这决定了标签在 UI 中显示的顺序。将其设置为natural以按定义的顺序显示标签,或设置为suggestion以优先考虑与建议关联的标签。如果分数可用,标签将按降序排列。默认为natural。use_markdown(可选):在TextQuestion中,定义字段是否应渲染 markdown 文本。默认为False。如果将其设置为True,你将能够使用所有 Markdown 功能进行文本格式化,以及嵌入多媒体内容和 PDF。要深入了解详细信息,请参阅此教程。
注意
Markdown 中的多媒体功能已在此处,但仍处于实验阶段。在我们探索早期阶段时,由于 ElasticSearch 的限制,文件大小受到限制,并且可视化和加载时间可能因你的浏览器而异。我们正在努力改进这一点,并欢迎你的反馈和建议!
查看以下选项卡,了解如何根据问题类型设置问题
rg.LabelQuestion(
name="relevant",
title="Is the response relevant for the given prompt?",
labels={"YES": "Yes", "NO": "No"}, # or ["YES","NO"]
required=True,
visible_labels=None
)

rg.MultiLabelQuestion(
name="content_class",
title="Does the response include any of the following?",
description="Select all that apply",
labels={"hate": "Hate Speech" , "sexual": "Sexual content", "violent": "Violent content", "pii": "Personal information", "untruthful": "Untruthful info", "not_english": "Not English", "inappropriate": "Inappropriate content"}, # or ["hate", "sexual", "violent", "pii", "untruthful", "not_english", "inappropriate"]
required=False,
visible_labels=4,
labels_order="natural"
)
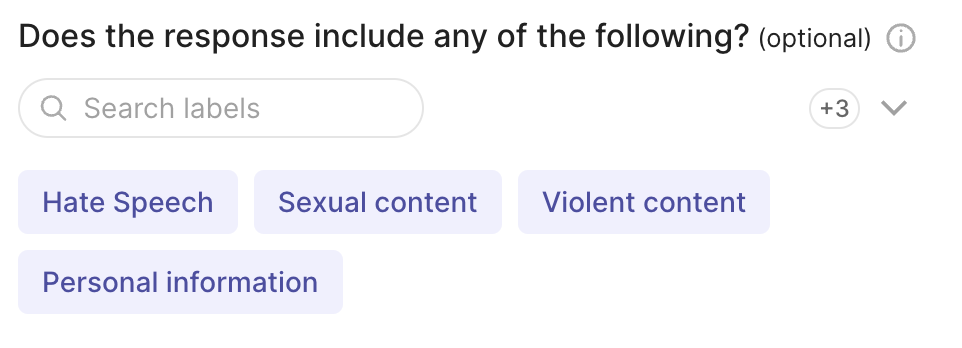
rg.RankingQuestion(
name="preference",
title="Order replies based on your preference",
description="1 = best, 3 = worst. Ties are allowed.",
required=True,
values={"reply-1": "Reply 1", "reply-2": "Reply 2", "reply-3": "Reply 3"} # or ["reply-1", "reply-2", "reply-3"]
)
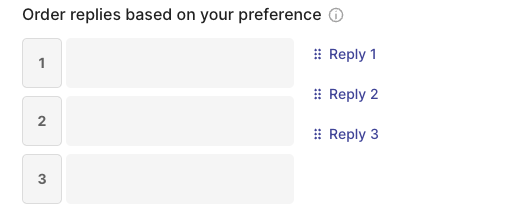
rg.RatingQuestion(
name="quality",
title="Rate the quality of the response:",
description="1 = very bad - 5= very good",
required=True,
values=[1, 2, 3, 4, 5]
)
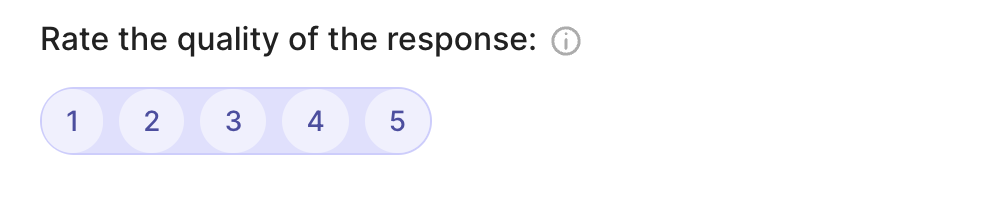
rg.SpanQuestion(
name="entities",
title="Highlight the entities in the text:",
labels={"PER": "Person", "ORG": "Organization", "EVE": "Event"},
# or ["PER", "ORG", "EVE"],
field="text",
required=True,
allow_overlapping=False
)
rg.TextQuestion(
name="corrected-text",
title="Provide a correction to the response:",
required=False,
use_markdown=True
)

定义 metadata#
元数据属性允许你配置元数据信息的使用,以用于 UI 和 Python SDK 中可用的筛选和排序功能。
你可以使用 Python SDK 定义元数据属性,方法是提供以下参数
name:元数据属性的名称,将在内部使用。title(可选):元数据属性的名称,将在 UI 中显示。默认为name值,但首字母大写。visible_for_annotators(可选):一个布尔值,用于指定元数据属性是否可供具有annotator角色的用户在 UI 中访问 (True),或者是否仅对具有owner或admin角色的用户可见 (False)。默认设置为True。
以下参数适用于特定元数据类型
values(可选):在TermsMetadataProperty中,你可以传递此元数据属性的有效值列表,以防你要运行验证。如果未提供任何值,则将根据记录中提供的值计算值列表。min(可选):在IntegerMetadataProperty或FloatMetadataProperty中,你可以传递最小有效值。如果未提供任何值,则将根据记录中提供的值计算最小值。max(可选):在IntegerMetadataProperty或FloatMetadataProperty中,你可以传递最大有效值。如果未提供任何值,则将根据记录中提供的值计算最大值。
rg.TermsMetadataProperty(
name="groups",
title="Annotation groups",
values=["group-a", "group-b", "group-c"] #optional
)
rg.IntegerMetadataProperty(
name="integer-metadata",
title="Integers",
min=0, #optional
max=100, #optional
visible_for_annotators=False
)
rg.FloatMetadataProperty(
name="float-metadata",
title="Floats",
min=-0.45, #optional
max=1000.34, #optional
visible_for_annotators=False
)
注意
你还可以在配置数据集后定义元数据属性,或使用 add_metadata_property 方法将其添加到 Argilla 中的现有数据集。此外,你现在可以使用 TextDescriptivesExtractor 自动将字段的文本描述符添加为元数据。有关更多信息,请查看此处。
定义 vectors#
要在 UI 和 Python SDK 中使用相似性搜索,你将需要配置向量设置。这些设置使用 SDK 定义为最多 5 个向量的列表。它们具有以下参数
name:向量的名称,它将出现在记录中。dimensions:此设置中使用的向量的维度。title(可选):向量的名称,用于在 UI 中显示以提高可读性。
vectors_settings = [
rg.VectorSettings(
name="my_vector",
dimensions=768
),
rg.VectorSettings(
name="my_other_vector",
title="Another Vector", # optional
dimensions=768
)
]
注意
你还可以在配置数据集后定义向量设置,或将其添加到 Argilla 中的现有数据集。为此,请使用 add_vector_settings 方法。此外,你现在可以使用 SentenceTransformersExtractor 自动将字段的文本描述符添加为元数据。有关更多信息,请查看此处。
定义 guidelines#
一旦你决定了要显示的数据和要提出的问题,向标注者提供清晰的指南就非常重要。这些指南帮助他们理解任务并一致地回答问题。你可以通过两种方式提供指南
在数据集指南中:这在你在 Python SDK 中创建数据集时作为参数添加(请参阅下方)。它将显示在 UI 中的数据集设置中。
作为问题描述:这些在你在 Python SDK 中创建问题时作为参数添加(请参阅上方)。此文本将显示在 UI 中问题旁边的工具提示中。
最佳实践是至少使用数据集指南(如果不是两种方法都使用)。问题描述应简短并为特定问题提供上下文。它们可以是该问题指南的摘要,但这通常不足以协调整个标注团队。在指南中,你可以包含项目描述、关于如何回答每个问题的详细信息和示例、关于何时丢弃记录的说明等。
创建数据集#
一旦定义了项目的范围,这意味着了解 fields、questions 和 guidelines(如果适用),你就可以继续创建 FeedbackDataset。为此,你将需要定义以下参数
fields:要在记录卡中显示的字段列表。字段在 UI 中出现的顺序与此列表的顺序一致。questions:要在表单中显示的问题列表。问题在 UI 中出现的顺序与此列表的顺序一致。metadata(可选):此数据集中包含的元数据属性列表。allow_extra_metadata(可选):一个布尔值,用于指定此数据集是否允许记录中存在除metadata下指定的元数据字段之外的其他字段。请注意,这些字段对任何用户都无法从 UI 访问,只能使用 Python SDK 检索。vectors_settings(可选):用于相似性搜索的向量设置列表(最多 5 个)。guidelines(可选):一组标注者指南。这些指南将显示在 UI 中的数据集设置中。
如果你尚未这样做,请查看以上部分以了解有关它们的更多信息。
以下是一个快速示例,展示了如何在本地创建一个 FeedbackDataset,用于评估问答任务中回答的质量。FeedbackDataset 包含两个字段:问题 (question) 和答案 (answer),以及两个用于衡量答案质量并在需要时进行纠正的问题。
dataset = rg.FeedbackDataset(
fields=[
rg.TextField(name="question"),
rg.TextField(name="answer"),
],
questions=[
rg.RatingQuestion(
name="answer_quality",
description="How would you rate the quality of the answer?",
values=[1, 2, 3, 4, 5],
),
rg.TextQuestion(
name="answer_correction",
description="If you think the answer is not accurate, please, correct it.",
required=False,
),
],
metadata_properties = [
rg.TermsMetadataProperty(
name="groups",
title="Annotation groups",
values=["group-a", "group-b", "group-c"] #optional
),
rg.FloatMetadataProperty(
name="temperature",
min=-0, #optional
max=1, #optional
visible_for_annotators=False
)
],
allow_extra_metadata = False,
vectors_settings=[
rg.VectorSettings(
name="sentence_embeddings",
dimensions=768,
title="Sentence Embeddings" #optional
)
],
guidelines="Please, read the question carefully and try to answer it as accurately as possible."
)
定义数据集后,可以通过 field_by_name、question_by_name、metadata_property_by_name 和 vector_settings_by_name 方法获取其专用属性。
dataset.field_by_name("question")
# rg.TextField(name="question")
dataset.question_by_name("answer_quality")
# rg.RatingQuestion(
# name="answer_quality",
# description="How would you rate the quality of the answer?",
# values=[1, 2, 3, 4, 5],
# )
dataset.metadata_property_by_name("groups")
# rg.TermsMetadataProperty(
# name="groups",
# title="Annotation groups",
# values=["group-a", "group-b", "group-c"]
# )
dataset.vector_settings_property_by_name("sentence_embeddings")
# rg.VectorSettings(
# name="sentence_embeddings",
# title="Sentence Embeddings",
# dimensions=768
# )
注意
配置数据集后,您仍然可以从 UI 界面编辑主要信息,例如字段标题、问题、描述和 Markdown 格式。更多信息请参阅 数据集设置。
注意
UI 界面中的字段和问题遵循它们添加到 Python SDK 中 fields 和 questions 属性的顺序。
提示
如果您作为标注团队的一员工作,并且想要控制标注员之间的重叠程度,您应该在配置和推送数据集之前,考虑 设置标注团队指南 中的不同工作流程。
推送到 Argilla#
要将数据集导入到您的 Argilla 实例,您可以使用 FeedbackDataset 实例中的 push_to_argilla 方法。推送后,您将能够在 UI 界面中看到您的数据集。
注意
从 Argilla 1.14.0 开始,调用 push_to_argilla 不仅会将 FeedbackDataset 推送到 Argilla 中,还会返回远程 FeedbackDataset 实例,这意味着记录的添加、更新和删除将在完成后立即推送到 Argilla。这与之前版本的 Argilla 不同,在之前的版本中,您需要再次调用 push_to_argilla 才能将更改推送到 Argilla。
remote_dataset = dataset.push_to_argilla(name="my-dataset", workspace="my-workspace")
dataset.push_to_argilla(name="my-dataset", workspace="my-workspace")
更新配置#
配置更新行为略有不同,具体取决于您使用的是本地还是远程 FeedbackDataset 实例。我们不允许从 Python SDK 更改远程 FeedbackDataset 的 fields 和 questions,但允许从 Argilla UI 界面更改它们的 description 和 title。此外,guidelines、metadata_properties 和 vector_settings 可以从 Argilla UI 界面和 Python SDK 进行更改。对于本地 FeedbackDataset 实例,我们允许更改所有这些属性。配置更新受到限制,因为我们想要避免数据集与定义的记录和标注之间出现不一致。
这仅适用于本地 FeedbackDataset 实例。
# Add new fields
dataset = rg.FeedbackDataset(...)
new_fields=[
rg.Type_of_field(.,.,.),
rg.Type_of_field(.,.,.),
]
dataset.fields.extend(new_fields)
# Remove a non-required field
dataset.fields.pop(0)
这仅适用于本地 FeedbackDataset 实例。
# Add new questions
dataset = rg.FeedbackDataset(...)
new_questions=[
rg.Type_of_question(.,.,.),
rg.Type_of_question(.,.,.),
]
dataset.questions.extend(new_questions)
# Remove a non-required question
dataset.questions.pop(0)
这适用于本地和远程 FeedbackDataset 实例。update_metadata_properties 仅支持 RemoteFeedbackDataset 实例。
dataset = rg.FeedbackDataset(...)
# Add metadata properties
metadata = rg.TermsMetadataProperty(name="my_metadata", values=["like", "dislike"])
dataset.add_metadata_property(metadata)
# Change metadata properties title
metadata_cfg = dataset.metadata_property_by_name("my_metadata")
metadata_cfg.title = "Likes"
dataset.update_metadata_properties(metadata_cfg)
# Delete a metadata property
dataset.delete_metadata_properties(metadata_properties="my_metadata")
这适用于本地和远程 FeedbackDataset 实例。update_vectors_settings 仅支持 RemoteFeedbackDataset 实例。
dataset = rg.FeedbackDataset(...)
# Add vector settings to the dataset
dataset.add_vector_settings(rg.VectorSettings(name="my_vectors", dimensions=786))
# Change vector settings title
vector_cfg = ds.vector_settings_by_name("my_vectors")
vector_cfg.title = "Old vectors"
dataset.update_vectors_settings(vector_cfg)
# Delete vector settings
dataset.delete_vectors_settings("my_vectors")
这适用于本地和远程 FeedbackDataset 实例。
# Define new guidelines from the template
dataset = rg.FeedbackDataset(...)
# Define new guidelines for a question
dataset.questions[0].description = 'New description for the question.'
其他数据集#
注意
本节中介绍的记录类对应于三个数据集:DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。这些数据集将在 Argilla 2.0 中被弃用,并由完全可配置的 FeedbackDataset 类取代。不确定使用哪个数据集?请查看我们关于 选择数据集 的章节。
在底层,Dataset 类将记录存储在一个简单的 Python 列表中。因此,使用 Dataset 类与使用简单的记录列表没有太大区别,但在创建数据集之前,我们应该首先定义数据集设置和标注模式。
Argilla 数据集具有某些设置,您可以通过 rg.*Settings 类进行配置,例如 rg.TextClassificationSettings。Dataset 类会为您执行一些额外的检查,以确保在向数据集追加或索引时不会混合记录类型。
配置数据集#
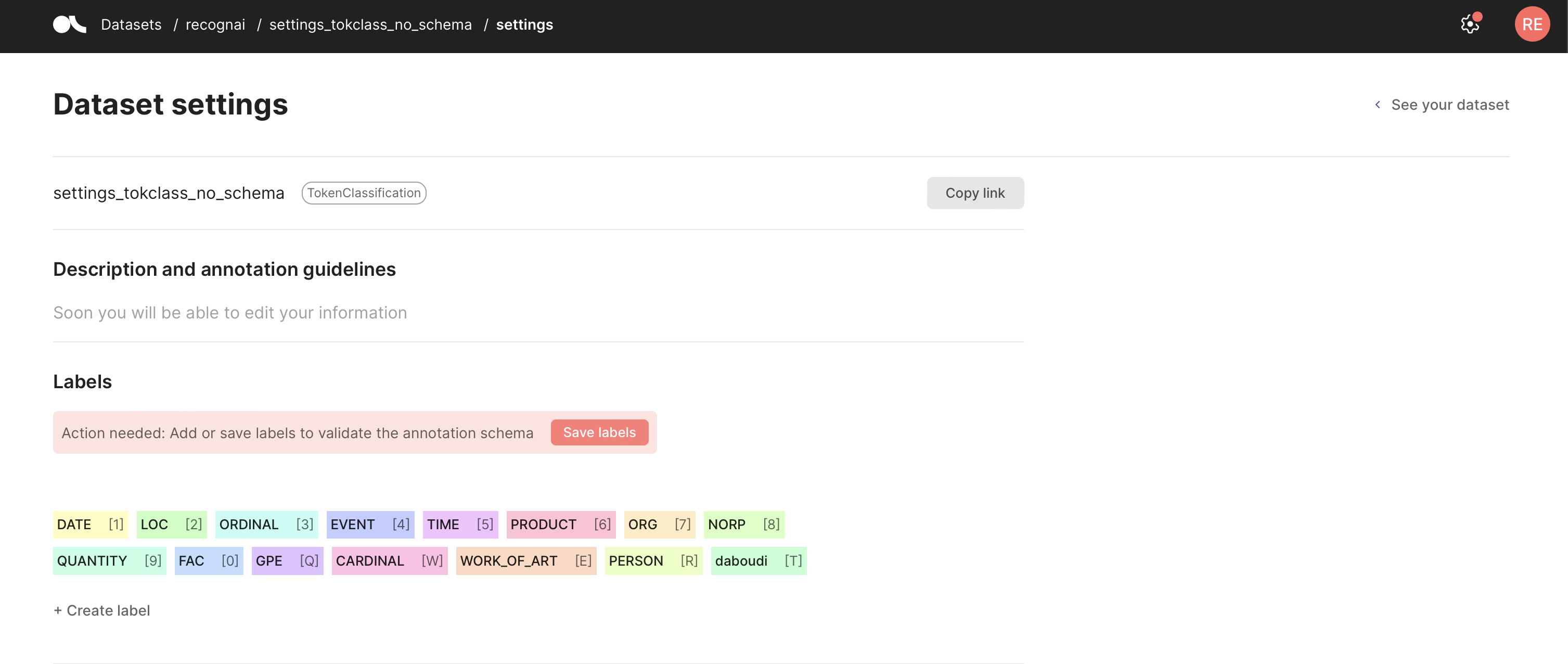
您可以定义您的 Argilla 数据集,这将设置您的预测和标注的允许标签。一旦您设置了标注模式,每次您登录到相应的数据集时,Argilla 都会对添加的预测和标注执行验证,以确保它们符合模式。您可以使用下面的代码或从 UI 界面中的 数据集设置页面 设置您的标签。有关如何添加 记录、元数据、向量 或 建议和回复 的更多信息,请参阅相应的指南。
如果您忘记定义标注模式,Argilla 将自动聚合在数据集中找到的标签,但您需要验证它。为此,请转到您的 数据集设置页面 并单击保存模式。
import argilla as rg
settings = rg.TextClassificationSettings(label_schema=["A", "B", "C"])
rg.configure_dataset_settings(name="my_dataset", settings=settings)
import argilla as rg
settings = rg.TokenClassificationSettings(label_schema=["A", "B", "C"])
rg.configure_dataset_settings(name="my_dataset", settings=settings)
因为我们不要求 Text2Text 具有标注模式,所以我们可以通过直接使用 rg.log() 记录记录来创建数据集。
推送到 Argilla#
我们可以使用 rg.log() 函数将记录推送到 Argilla。此函数接受记录列表以及我们要将记录推送到的数据集的名称。
import argilla as rg
rec = rg.TextClassificationRecord(
text="beautiful accommodations stayed hotel santa... hotels higher ranked website.",
prediction=[("price", 0.75), ("hygiene", 0.25)],
annotation="price"
)
rg.log(records=rec, name="my_dataset")