Argilla 概念#
反馈数据集#
注意
本节涵盖的数据集类是 FeedbackDataset。这个完全可配置的数据集将在 Argilla 2.0 中取代 DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。不确定使用哪个数据集?请查看我们关于 选择数据集 的章节。
这份综合指南介绍了 Argilla 反馈中的关键实体。Argilla 反馈是一个强大的平台,旨在收集和管理来自标注者或注释者的反馈数据。通过理解这些实体及其关系,你可以有效地利用该平台,并为各种应用利用收集到的反馈。
请参考下图,以可视化 Argilla 反馈中实体之间的关系

数据集#
**数据集** 代表反馈记录的集合。它作为组织和管理反馈数据的容器。一个数据集由多个 **记录** 组成,这些记录是单独的反馈数据点。通过数据集,你可以配置标注者提供反馈的结构、字段和问题。
字段#
**字段** 定义了记录中特定数据元素的模式或结构。它代表标注者在反馈过程中将看到和交互的信息片段。字段的示例可以包括文本输入、复选框或下拉菜单。字段在收集反馈时为标注者提供必要的上下文和指导。
问题#
**问题** 代表呈现给标注者以征求反馈的特定查询或指令。问题在指导标注者和捕获他们的输入方面起着至关重要的作用。Argilla 反馈支持不同类型的问题,以适应各种反馈场景。
**标签问题 (LabelQuestion)**:这种类型的问题旨在以单个标签的形式捕获反馈。标注者可以使用预定义的选项集对给定的方面或属性进行分类。它适用于获取选项互斥的分类。
**多标签问题 (MultiLabelQuestion)**:这种类型的问题旨在以一个或多个标签的形式捕获反馈。标注者可以使用预定义的选项集对给定的方面或属性进行分类。它适用于获取选项非互斥的分类。
**排序问题 (RankingQuestion)**:这种类型的问题旨在捕获标注者的偏好。标注者可以根据自己的偏好或相关性对预定义的选项集进行排序。它适用于获取关于标注者在多个选项中偏好的反馈。
**评分问题 (RatingQuestion)**:这种类型的问题旨在捕获数字评分反馈。标注者可以使用预定义的量表或选项集对给定的方面或属性进行评分。它适用于获取定量反馈或评估特定标准。
**跨度问题 (SpanQuestion)**:这种类型的问题旨在突出显示记录字段中相关的文本片段。它适用于诸如命名实体识别或信息提取之类的任务。
**文本问题 (TextQuestion)**:这种类型的问题适用于收集来自标注者的自然语言反馈或文本回复。它允许他们提供详细且描述性的反馈以响应问题。
指南#
指南是反馈收集过程的关键组成部分。它们为标注者提供在提供反馈时需要遵循的说明、期望和任何特定指导。指南有助于确保收集到的反馈的一致性和质量。提供清晰简洁的指南以帮助标注者理解反馈任务的背景和要求至关重要。
记录#
**记录** 代表数据集中的单个反馈数据点。它包含你希望标注者提供反馈的信息或数据。每个记录包含一个或多个 **字段**,这些字段是标注者在反馈过程中将与之交互的特定数据元素或属性。字段定义了反馈记录的结构和内容。
回复#
Argilla 允许多个并发注释者,无缝地从许多标注者那里收集反馈。每个 **回复** 代表标注者针对数据集中的特定问题提供的输入。它包括标注者的身份标识、反馈值本身以及指示回复是否已提交或丢弃的状态。这些回复构成了收集到的反馈数据的基础,捕捉了标注者的不同观点和见解。
建议#
**建议** 通过向标注者提供机器生成的反馈来增强反馈收集过程。建议充当自动化决策辅助工具,利用规则、模型或语言模型 (LLM) 来加速反馈过程。
通过建议,每个记录都可以配备多个机器生成的推荐(每个问题一个)。这些建议可以充当弱信号,与人工反馈无缝结合,以提高反馈收集工作流程的效率和准确性。通过利用自动化建议的力量,标注者可以做出更明智的决策,从而实现更精简、部分自动化和更有效的反馈收集过程。
元数据#
**元数据** 将保存你希望记录拥有的额外信息。例如,如果它属于训练数据集或测试数据集,或者关于该特定记录的快速事实。随意使用它,根据你的需要!
向量#
**向量** 可以添加到记录中,以表示 **字段** 或其组合的语义含义。它们可以在 UI 或 SDK 中使用,以搜索数据集中最相似或最不相似的记录。
其他数据集#
注意
本节涵盖的记录类对应于三个数据集:DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。这些将在 Argilla 2.0 中被弃用,并由完全可配置的 FeedbackDataset 类取代。不确定使用哪个数据集?请查看我们关于 选择数据集 的章节。
Argilla 是围绕一些简单的概念构建的。本节阐明这些概念是什么。让我们来看看 Argilla 的数据模型
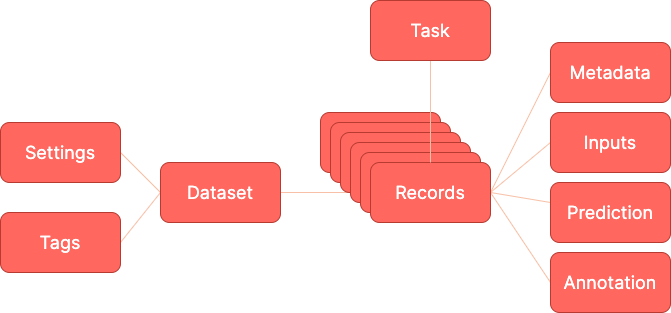
数据集#
数据集是相同类型 记录 的集合。你可以使用 Argilla 客户端以编程方式 构建数据集,并将它们 log 到 Web 应用程序。在 Web 应用程序中,你可以 深入研究你的数据集 以探索和注释你的记录。你还可以 load 将你的数据集加载回客户端,并将它们导出为各种格式,或者 准备它以训练 模型。
记录#
记录是由 **文本** 输入以及可选的 **预测** 和 **注释** 组成的数据项。
将预测视为你的系统对该输入所做的分类(例如:“弗吉尼亚·伍尔夫”),并将注释视为你手动分配给该输入的真值(因为你知道,在这种情况下,它应该是“威廉·莎士比亚”)。记录由它们相关的 **任务** 类型定义。让我们看三个不同的例子
示例#
注意
有关新 FeedbackDataset 的数据模型的信息,请查看 本指南。
文本分类#
单标签
文本分类处理的是预测文本属于哪些类别。就像给你看一张图片,你可以很快分辨出里面是狗还是猫一样,我们构建 NLP 模型来区分简·奥斯汀的小说和夏洛蒂·勃朗特的诗歌。这完全是关于用标记的例子喂养模型,并观察它们如何开始预测相同的标签。
让我们看一些垃圾邮件分类器的例子。
record = rg.TextClassificationRecord(
text="Access this link to get free discounts!",
prediction = [('SPAM', 0.8), ('HAM', 0.2)],
prediction_agent = "link or reference to agent",
annotation = "SPAM",
annotation_agent= "link or reference to annotator",
# Extra information about this record
metadata={
"split": "train"
},
)
多标签
另一个与文本分类类似但又略有不同的任务是多标签文本分类,只有一个关键区别;可以预测多个标签。虽然在常规文本分类任务中,我们可能会决定推文 “I can’t wait to travel to Egypt and visit the pyramids” 适合 #Travel 标签,这是准确的,但在多标签文本分类中,我们可以将其分类为多个标签,例如 #Travel #History #Africa #Sightseeing #Desert。
record = rg.TextClassificationRecord(
text="I can't wait to travel to Egypt and visit the pyramids",
multi_label = True,
prediction = [('travel', 0.8), ('history', 0.6), ('economy', 0.3), ('sports', 0.2)],
prediction_agent = "link or reference to agent",
annotation = ['travel', 'history'],
annotation_agent= "link or reference to annotator",
)
令牌分类#
令牌分类类型的任务是 NLP 任务,旨在将输入文本分成单词或音节,并为其分配某些值。想想给句子中的每个词语赋予其语法类别,或者突出显示医疗报告的哪些部分属于特定专业。有一些流行的任务,如 NER 或 POS 标记。
record = rg.TokenClassificationRecord(
text = "Michael is a professor at Harvard",
tokens = ["Michael", "is", "a", "professor", "at", "Harvard"],
# Predictions are a list of tuples with all your token labels and their starting and ending positions
prediction = [('NAME', 0, 7), ('LOC', 26, 33)],
prediction_agent = "link or reference to agent",
# Annotations are a list of tuples with all your token labels and their starting and ending positions
annotation = [('NAME', 0, 7), ('ORG', 26, 33)],
annotation_agent = "link or reference to annotator",
metadata={ # Information about this record
"split": "train"
},
)
文本到文本#
文本到文本任务,如文本生成,是模型接收和输出令牌序列的任务。此类任务的示例包括机器翻译、文本摘要、释义生成等。
record = rg.Text2TextRecord(
text = "Michael is a professor at Harvard",
# The prediction is a list of texts or tuples if you want to add a score to a prediction
prediction = ["Michael es profesor en Harvard", "Michael es un profesor de Harvard"],
prediction_agent = "link or reference to agent",
# The annotation is a string representing the expected output text for the given input text
annotation = "Michael es profesor en Harvard"
)
注释#
注释是分配给记录的信息片段,可以是标签、令牌级标签或一组标签,通常由人工代理完成。
预测#
预测是分配给记录的信息片段,可以是标签或一组标签,通常由机器过程完成。
元数据#
元数据将保存你希望记录拥有的额外信息:如果它属于训练数据集或测试数据集,或者关于该特定记录的快速事实……随意使用它,根据你的需要!
任务#
任务定义了记录内预测和注释的目标和形式。你可以在 任务 中查看我们支持的任务。
设置#
目前,只有一组预定义的标签(标签模式)是可配置的。但是,诸如注释者和元数据模式之类的其他设置计划作为数据集设置的一部分得到支持。