llamaindex:使用 LlamaIndex 构建 LLM 应用程序,并使用 Argilla 监控数据。#
此集成允许用户将 Argilla 提供的反馈循环包含到 LlamaIndex 生态系统中。它基于一个回调处理程序,在 LlamaIndex 工作流中运行。
LlamaIndex 是一个专门的数据框架,专为支持 LLM 驱动的应用程序开发而定制。它提供了一个复杂的结构,使开发人员能够将各种数据源与大型语言模型无缝集成。这些来源包括各种文件格式,如 PDF 和 PowerPoint,流行的应用程序,如 Notion 和 Slack,以及数据库,如 Postgres 和 MongoDB。通过一系列连接器,该框架简化了数据摄取,促进了与 LLM 的顺畅交互。此外,LlamaIndex 还为数据检索和查询提供了高效的接口。此功能允许开发人员输入 LLM 提示,并接收上下文丰富、知识增强的输出。
本质上,LlamaIndex 充当管理与 LLM 交互的中间人,通过从输入数据构建索引。然后利用此索引来回答与所提供数据相关的问题。LlamaIndex 非常灵活,能够生成不同类型的索引——向量、树、列表或关键字索引——以满足特定需求。
LlamaIndex 提供了广泛的工具,方便了数据摄取、检索、结构化以及与各种应用程序框架集成的过程。请随时查看 LlamaIndex 和 Argilla
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,您只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地机器上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种选项可以运行它
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 Notebook。不要忘记将运行时类型更改为 GPU,以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 Notebook 并在本地机器或您选择的 Jupyter Notebook 工具上运行它。
开始入门#
您首先需要按如下方式安装 argilla 和 argilla-llama-index
[ ]:
%pip install argilla-llama-index
用法#
只需简单一步即可将数据记录到 LlamaIndex 工作流中的 Argilla 中。我们只需要在开始使用 LLM 进行生产之前调用处理程序。我们将使用 OpenAI 的 GPT3.5 作为我们的 LLM。为此,您需要来自 OpenAI 的有效 API 密钥。您可以通过 此链接 获取更多信息并获取一个密钥。获得 API 密钥后,导入它的最简单方法是通过环境变量,或通过 getpass()。
[1]:
import os
openai_api_key = os.getenv("OPENAI_API_KEY")
现在,让我们编写所有必要的导入并初始化 Argilla 客户端。
[2]:
from llama_index.core import VectorStoreIndex, ServiceContext, SimpleDirectoryReader, set_global_handler
from llama_index.llms.openai import OpenAI
import argilla as rg
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
现在,我们将为 Llama Index 设置 Argilla 全局处理程序。通过这样做,我们确保使用 Llama Index 获得的预测会自动上传到我们之前初始化的 Argilla 客户端。在处理程序中,我们需要提供我们将使用的数据集名称。如果数据集不存在,将使用给定名称创建它。您还可以设置 API KEY、API URL 和 workspace 名称。您可以在此处了解有关控制 Argilla 初始化的变量的更多信息。
[ ]:
set_global_handler("argilla", dataset_name="query_model")
现在让我们创建 llm 实例,使用 OpenAI 的 GPT-3.5。
[5]:
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.8, openai_api_key=openai_api_key)
使用下面的代码片段,您可以创建一个使用 LlamaIndex 的基本工作流。您还需要一个 txt 文件作为文件夹 data 中的数据源。我们为您准备了一个示例 .txt 文件,从 Llama Index 文档中获得。
[ ]:
service_context = ServiceContext.from_defaults(llm=llm)
docs = SimpleDirectoryReader("../../data").load_data()
index = VectorStoreIndex.from_documents(docs, service_context=service_context)
query_engine = index.as_query_engine()
现在,让我们运行 query_engine 以获得模型的响应。
[ ]:
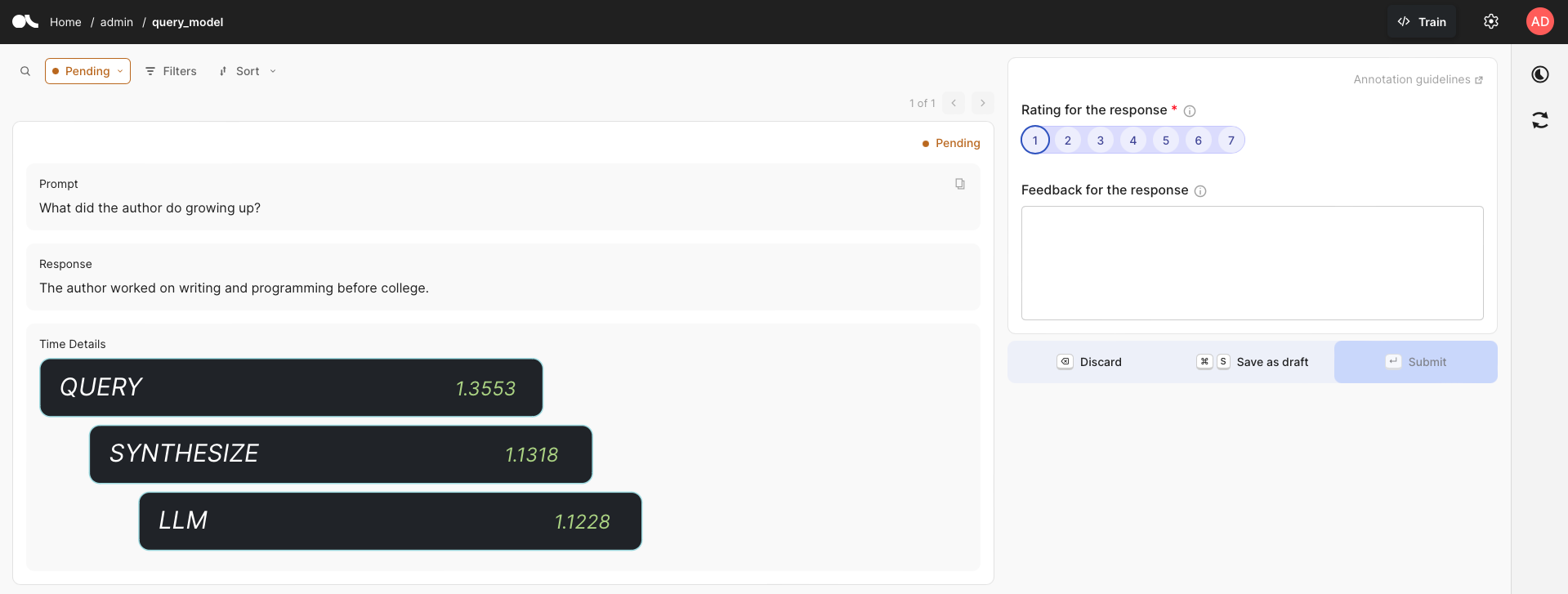
response = query_engine.query("What did the author do growing up?")
response
由于设置了全局处理程序,因此创建了一个 Argilla 数据集,数据集名称是我们作为参数引入的名称。使用 query 函数预测的所有内容都将自动记录在此数据集中,其中包含有关生成预测的步骤的信息。给出的提示和响应都已记录,您可以在 Argilla UI 的此示例中看到