🏷️ 使用您自己的数据微调情感分类器#
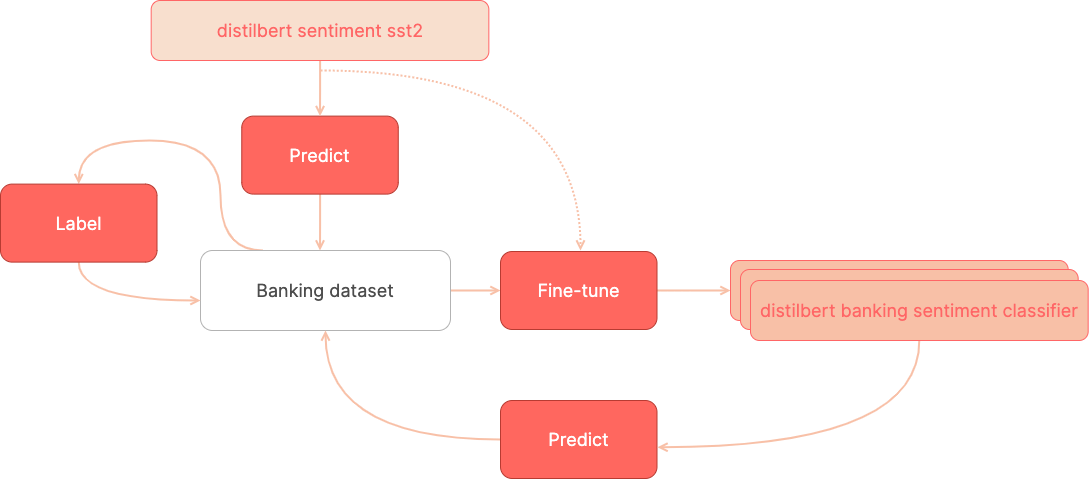
在本教程中,我们将按如下步骤构建一个用于银行领域用户请求的情感分类器
🏁 从 Hugging Face Hub 上最受欢迎的情感分类器开始(截至 2021 年 12 月,每月下载量近 400 万次),该分类器已在 SST2 情感数据集上进行了微调。
🏷️ 从预训练的情感分类器预测开始,标注包含银行用户请求的训练数据集。
⚙️ 使用您的训练数据集微调预训练的分类器。
🏷️ 通过更正微调模型的预测来标注更多数据。
⚙️ 使用扩展的训练数据集微调预训练的分类器。
简介#
本教程将向您展示如何为您自己的领域微调情感分类器,从没有标注数据开始。
大多数关于微调模型的在线教程都假设您已经拥有训练数据集。您会找到许多关于使用广泛使用的数据集(例如,用于情感分析的 IMDB)微调预训练模型的教程。
但是,通常您想要的是为您自己的用例微调模型。众所周知,NLP 模型性能通常会随着“领域外”数据而降低。例如,在电影评论(例如,IMDB)上预训练的情感分类器在客户请求方面表现不佳。
这是我们将要遵循的工作流程概述
让我们开始吧!
运行 Argilla#
在本教程中,您需要运行 Argilla 服务器。 有两种主要的部署和运行 Argilla 的选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上拥有帐户,则只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您希望 在本地计算机上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。 有两种运行它的选项
使用此页面顶部的“在 Colab 中打开”按钮。 此选项允许您直接在 Google Colab 上运行 Notebook。 不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
单击页面顶部的“查看源代码”链接下载 .ipynb 文件。 此选项允许您下载 Notebook 并在本地计算机或您选择的 Jupyter Notebook 工具上运行它。
[ ]:
%pip install argilla "transformers[torch]" datasets sklearn ipywidgets -qqq
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
如果您运行的是私有 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含我们需要的导入
[ ]:
import numpy as np
from datasets import load_dataset, load_metric, concatenate_datasets
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
from transformers import TrainingArguments, Trainer
启用遥测#
我们从您与教程的互动中获得宝贵的见解。 为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。 虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。 有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
预备知识#
为了构建我们微调的分类器,我们将使用两个主要资源,它们都可以在 🤗 Hub 中找到
银行领域的数据集:banking77
数据集:Banking 77#
此数据集包含带有相应意图注释的在线银行用户查询。
在我们的例子中,我们将标注这些查询的情感。 这可能对数字助理和客户服务分析很有用。
让我们直接从 Hub 加载数据集,并将数据集拆分为两个 50% 的子集。 我们将从 to_label1 拆分开始进行数据探索和注释,并将 to_label2 保留用于进一步迭代。
[ ]:
banking_ds = load_dataset("PolyAI/banking77")
to_label1, to_label2 = (
banking_ds["train"].train_test_split(test_size=0.5, seed=42).values()
)
模型:情感 distilbert 在 sst-2 上微调#
截至 2021 年 12 月,distilbert-base-uncased-finetuned-sst-2-english 在 Hugging Face Hub 中最受欢迎的文本分类模型中排名前五。
此模型是一个 distilbert 模型,在 SST-2(斯坦福情感树库)上进行了微调,这是一个非常流行的情感分类基准。
正如我们稍后将看到的,这是一个通用情感分类器,需要针对特定用例和文本风格进行进一步微调。 在我们的例子中,我们将探索其在银行用户查询方面的质量,并构建一个训练集以使其适应此领域。
让我们加载模型并使用数据集中的一个示例对其进行测试
[3]:
sentiment_classifier = pipeline(
model="distilbert-base-uncased-finetuned-sst-2-english",
task="sentiment-analysis",
top_k=None,
)
to_label1[3]["text"], sentiment_classifier(to_label1[3]["text"])
[3]:
('Hi, Last week I have contacted the seller for a refund as directed by you, but i have not received the money yet. Please look into this issue with seller and help me in getting the refund.',
[[{'label': 'NEGATIVE', 'score': 0.9934700727462769},
{'label': 'POSITIVE', 'score': 0.0065299225971102715}]])
该模型为 NEGATIVE 类分配了更高的概率。 按照我们的注释策略(请阅读下文了解更多信息),我们将把这样的示例标记为 POSITIVE,因为它们是通用问题,与银行应用程序的问题或故障无关。 最终目标将是微调模型以预测这些情况下的 POSITIVE。
关于情感分析和数据注释的说明#
情感分析是 NLP 中最具主观性的任务之一。 我们对情感的理解会因应用程序而异,并取决于项目的业务目标。 此外,情感可以用不同的方式建模,从而导致不同的标注方案。 例如,情感可以建模为实值(从 -1 到 1,从 0 到 1.0 等)或使用 2 个或更多标签(包括不同程度,例如正面、负面、中性等)
在本教程中,我们将使用预训练模型定义的原始标注方案,该方案由两个标签组成:POSITIVE 和 NEGATIVE。 我们可以添加 NEUTRAL 标签,但为了简单起见,我们先不添加。
在进行数据注释项目时,另一个重要问题是注释指南,它解释了如何将标签分配给特定示例。 正如我们稍后将看到的,我们将标注的消息大多是带有中性情感的问题,我们将使用 POSITIVE 标签进行标注,而另一些是负面问题,我们将使用 NEGATIVE 标签进行标注。 稍后,我们将展示每个标签的一些示例。
1. 在数据集上运行预训练模型并记录预测#
第一步,让我们使用预训练模型对我们的原始数据集进行预测。 为此,我们将使用 datasets 库中方便的 dataset.map 方法。
通过使用 Hugging Face pipeline 的自动监控支持可以简化以下步骤。 您可以在 监控指南 中找到更多详细信息。
预测#
[ ]:
def predict(examples):
return {"predictions": sentiment_classifier(examples["text"], truncation=True)}
# Add .select(range(10)) before map if you just want to test this quickly with 10 examples
to_label1 = to_label1.map(predict, batched=True, batch_size=4)
注意
如果您不想自己运行预测,也可以直接从 Hugging Face Hub 加载带有预测的记录:load_dataset("argilla/sentiment-banking", split="train"),请参阅下文了解更多详细信息。
构建和记录数据集#
以下代码构建了一个包含预测的 Argilla 记录列表,并将这些记录记录到 Argilla 以标注我们的第一个训练集。
[ ]:
records = []
for example in to_label1.shuffle():
record = rg.TextClassificationRecord(
text=example["text"],
metadata={
"category": example["label"]
}, # Log the intents for exploration of specific intents
prediction=[(pred["label"], pred["score"]) for pred in example["predictions"]],
prediction_agent="distilbert-base-uncased-finetuned-sst-2-english",
)
records.append(record)
rg.log(name="labeling_with_pretrained", records=records)
2. 使用预训练模型探索和标注数据#
在此步骤中,我们将首先探索预训练模型在我们的数据集上的表现。
初步观察
预训练的情感分类器倾向于将大多数示例标记为
NEGATIVE(5,001 条记录中的 4,835 条)。 您可以使用预测 / 预测为:过滤器自行查看使用此过滤器并按预测为
POSITIVE进行过滤,我们看到诸如“我没有取出应用程序中显示的现金金额。”之类的示例未按预期进行预测(根据我们在预备知识中描述的基本“注释策略”)。
考虑到此分析,我们可以开始标注我们的数据。
Argilla 为您提供了一个搜索驱动的 UI 来注释数据,使用自由文本搜索、搜索过滤器和 Elasticsearch 查询 DSL 进行高级查询。 这对于稀疏数据集、标签数量较多的任务或不平衡的类特别有用。 在标准情况下,我们建议您遵循以下工作流程
按顺序开始标注示例,无需使用搜索功能。 这样,您将注释一部分与数据集分布对齐的数据。
一旦您对数据有所了解,就可以开始使用过滤器和搜索功能来注释带有特定标签的示例。 在我们的例子中,我们将标注由我们的预训练模型预测为
POSITIVE的示例,然后标注一些预测为NEGATIVE的示例。
几分钟后,我们标注了将近 5% 的原始数据集,超过 200 个注释示例,这是一个小型数据集,但应该足以对我们的银行情感分类器进行首次微调
3. 微调预训练模型#
在此步骤中,我们将从 Argilla 加载我们的训练集,并使用 Hugging Face transformers 中的 Trainer API 进行微调。 为此,我们密切遵循 transformers 文档中的指南 微调预训练模型。
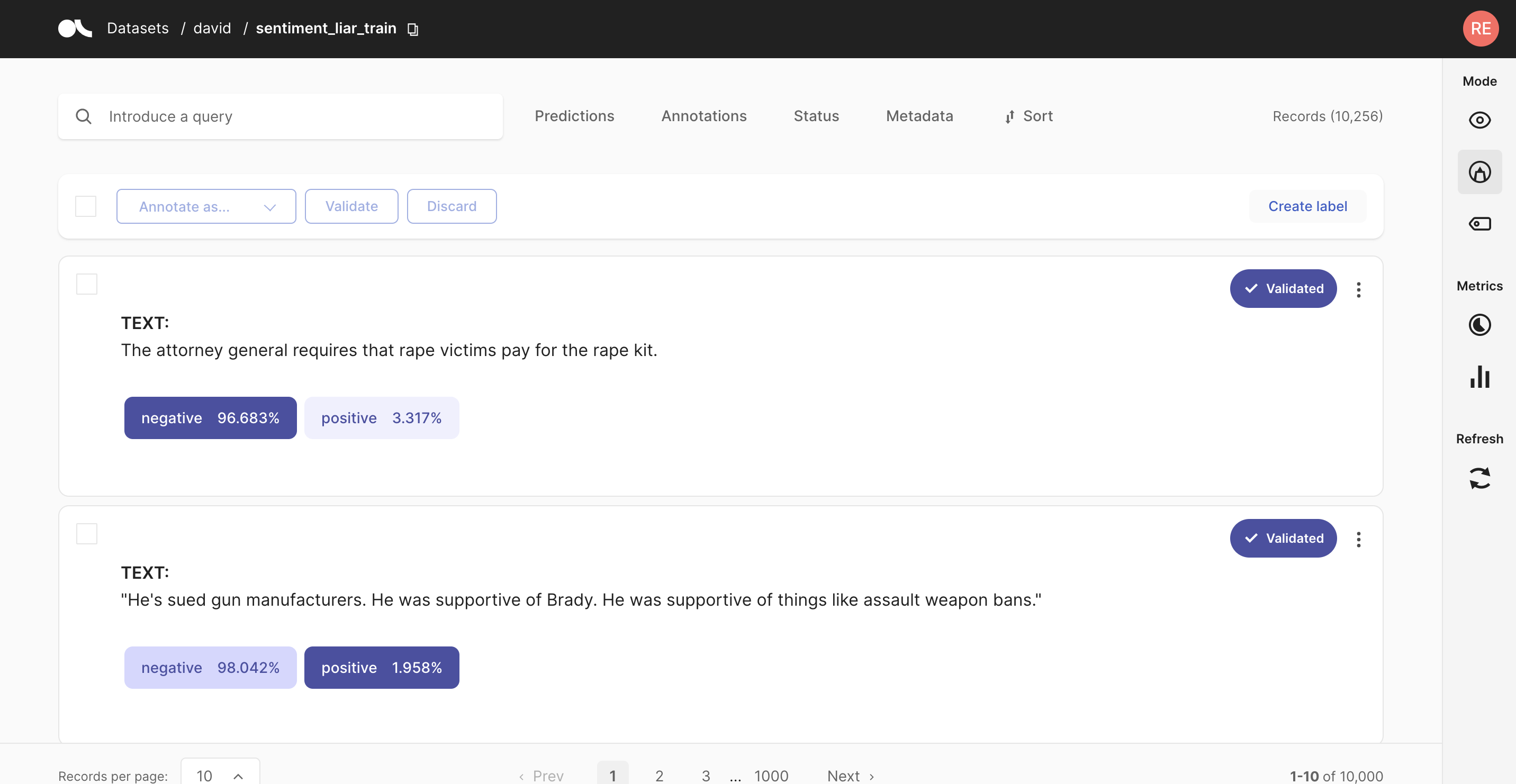
首先,让我们使用 load 方法中的 query 参数从我们的数据集加载注释。 Validated 状态对应于已注释的记录。
[47]:
rb_dataset = rg.load(name="labeling_with_pretrained", query="status:Validated")
rb_dataset.to_pandas().head(3)
[47]:
| inputs | prediction | prediction_agent | annotation | annotation_agent | multi_label | explanation | id | metadata | status | event_timestamp | metrics | search_keywords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | {'text': '我想取消购买。'} | [(NEGATIVE, 0.9997695088386536), (POSITIVE, 0.... | distilbert-base-uncased-finetuned-sst-2-english | POSITIVE | argilla | False | None | 0002cbd9-b687-462a-bbd2-3130f4c88d8d | {'category': 52} | Validated | None | None | None |
| 1 | {'text': '我收到的额外费用是怎么回事?'} | [(NEGATIVE, 0.9968097805976868), (POSITIVE, 0.... | distilbert-base-uncased-finetuned-sst-2-english | NEGATIVE | argilla | False | None | 0009f445-4844-4ccd-9ea8-207a1fb0e239 | {'category': 19} | Validated | None | None | None |
| 2 | {'text': '你们在 ... 时有年龄要求吗'} | [(NEGATIVE, 0.9825802445411682), (POSITIVE, 0.... | distilbert-base-uncased-finetuned-sst-2-english | POSITIVE | argilla | False | None | 0012e385-643c-4660-ad66-5b4339bb3999 | {'category': 1} | Validated | None | None | None |
准备训练和测试数据集#
现在让我们准备我们的数据集,用于训练和测试我们的情感分类器,使用 datasets 库
[ ]:
# Create 🤗 dataset with labels as numeric ids
train_ds = rb_dataset.prepare_for_training()
# Tokenize our datasets
tokenizer = AutoTokenizer.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_train_ds = train_ds.map(tokenize_function, batched=True)
# Split the data into a training and evaluation set
train_dataset, eval_dataset = tokenized_train_ds.train_test_split(
test_size=0.2, seed=42
).values()
训练我们的情感分类器#
正如我们之前提到的,我们将微调 distilbert-base-uncased-finetuned-sst-2-english 模型。 另一种选择是从头开始微调 distilbert 掩码语言模型,但我们将此实验留给您。
让我们加载模型并配置训练器
[ ]:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
)
training_args = TrainingArguments(
"distilbert-base-uncased-sentiment-banking",
evaluation_strategy="epoch",
logging_steps=30,
)
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
args=training_args,
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
最后,我们可以训练我们的第一个模型!
[ ]:
trainer.train()
4. 测试微调模型#
在此步骤中,让我们首先测试我们刚刚训练的模型。
让我们使用我们的模型创建一个新的 pipeline
[ ]:
finetuned_sentiment_classifier = pipeline(
model=model.to("cpu"),
tokenizer=tokenizer,
task="sentiment-analysis",
return_all_scores=True,
)
然后,我们可以将其预测与预训练模型和一个示例进行比较
[ ]:
finetuned_sentiment_classifier(
"I need to deposit my virtual card, how do i do that."
), sentiment_classifier("I need to deposit my virtual card, how do i do that.")
如您所见,我们的微调模型现在将这些一般性问题(与问题或故障无关)分类为 POSITIVE,而预训练模型仍然将其分类为 NEGATIVE。
现在让我们检查一个与问题相关的示例,其中两个模型都按预期工作
[ ]:
finetuned_sentiment_classifier(
"Why is my payment still pending?"
), sentiment_classifier("Why is my payment still pending?")
5. 在数据集上运行我们的微调模型并记录预测#
现在让我们从剩余的记录(我们在第一次注释会话中未注释的记录)创建一个数据集。
我们将使用 Default 状态执行此操作,这意味着该记录尚未分配标签。 从这里开始,这基本上与步骤 1 相同,在本例中,我们使用微调模型。 让我们利用数据集 map 功能进行批量预测。 之后,我们可以再次将数据集直接转换为 Argilla 记录并将其记录到 Web 应用程序。
[ ]:
rb_dataset = rg.load(name="labeling_with_pretrained", query="status:Default")
def predict(examples):
texts = [example["text"] for example in examples["inputs"]]
return {
"prediction": finetuned_sentiment_classifier(texts),
"prediction_agent": ["distilbert-base-uncased-banking77-sentiment"]
* len(texts),
}
ds_dataset = rb_dataset.to_datasets().map(predict, batched=True, batch_size=8)
records = rg.read_datasets(ds_dataset, task="TextClassification")
rg.log(records=records, name="labeling_with_finetuned")
6. 使用微调模型探索和标注数据#
在此步骤中,我们将首先探索微调模型在我们的数据集上的表现。
初步观察,使用按 POSITIVE 预测的过滤器,然后按 NEGATIVE 预测的过滤器,我们可以观察到微调模型的预测更符合我们的“注释策略”。
既然该模型在我们的用例中表现更好,我们将使用高度信息化的示例来扩展我们的训练集。 执行此操作的典型工作流程如下
使用预测分数过滤器来标注不确定的示例。
标注由我们的微调模型预测为
POSITIVE的示例,然后标注预测为NEGATIVE的示例以更正预测。
花费几分钟后,我们标注了将近 2% 的原始数据集,大约 80 个注释示例,这是一个小型数据集,但希望其中包含高度信息化的示例。
7. 使用扩展的训练数据集进行微调#
在此步骤中,我们将新示例添加到我们的训练集中,并微调我们银行情感分类器的新版本。
将标注的示例添加到我们之前的训练集中#
让我们将我们的新示例添加到我们之前的训练集中。
[ ]:
rb_dataset = rg.load("labeling_with_finetuned")
train_ds = rb_dataset.prepare_for_training()
tokenized_train_ds = train_ds.map(tokenize_function, batched=True)
train_dataset = concatenate_datasets([train_dataset, tokenized_train_ds])
训练我们的情感分类器#
由于我们想衡量向训练集添加示例的效果,我们将
从预训练的情感权重进行微调(与我们之前所做的相同)
使用之前的测试集和扩展的训练集(获得一个指标,我们用它来将此新版本与我们之前的模型进行比较)
[ ]:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
)
train_ds = train_dataset.shuffle(seed=42)
trainer = Trainer(
args=training_args,
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
model.save_pretrained("distilbert-base-uncased-sentiment-banking")
总结#
在本教程中,您学习了如何在预训练模型的帮助下从头开始构建训练集,执行了两次 predict > log > label 迭代。
虽然这在某种程度上是一个玩具示例,但您将能够将此工作流程应用于您自己的项目,以调整现有模型或从头开始构建模型。
在本教程中,我们介绍了一种构建训练集的方法:手动标注。如果您对其他可以与手动标注相结合的方法感兴趣,请查看以下内容