💡 使用 GPT-3 构建和评估零样本情感分类器#
在本教程中,我们将使用 GPT-3 和 Argilla 为金融领域的客户请求构建和评估情感分类器。
GPT-3 是 OpenAI 提供的强大的模型和 API,可以执行各种自然语言任务。Argilla 使您能够快速构建和迭代用于 NLP 的数据。
在本教程中,您将学习如何:
设置和使用零样本情感分类器,它不仅分析情感,还包括对其预测的解释!
使用 Argilla 评估预测质量并审查现有的训练集。
本教程重点介绍了构建涉及 GPT-3 等大型语言模型的人工参与工作流程的潜力。
让我们开始吧!
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。 有两种主要的部署和运行 Argilla 的选项:
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 Notebook(例如,Google Colab)运行教程,并且您在 Hugging Face 上有帐户,则只需单击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看官方 Hugging Face Hub 指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在本地计算机上运行 Argilla,这是推荐的选项。 请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。 有两种运行它的选项:
使用此页面顶部的“在 Colab 中打开”按钮。 此选项允许您直接在 Google Colab 上运行 Notebook。 不要忘记将运行时类型更改为 GPU,以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。 此选项允许您下载 Notebook 并在本地计算机或您选择的 Jupyter Notebook 工具上运行它。
设置#
在本教程中,我们将使用 openai 和 datasets 库。
[ ]:
%pip install openai datasets argilla -qqq
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下所示设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
现在让我们包含所需的导入
[174]:
import os
from json import loads
import openai
from datasets import load_dataset
import pandas as pd
from argilla.metrics.text_classification import f1
from argilla.metrics.commons import text_length
启用遥测#
我们从您与教程的互动中获得宝贵的见解。 为了改进自身,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。 虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。 有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
0. 数据集:banking77 情感数据集#
对于本教程,我们将使用一个小数据集,其中包含使用 Argilla 创建的标签,作为其他教程的一部分。
此数据集基于 banking77 数据集,该数据集包含在线银行用户查询,并使用其相应的意图进行注释。
对于我们的用例,我们标注了这些查询的情感,这可能对数字助理和客户服务分析很有用。
让我们直接从 Hub 加载已标注的数据集。
[5]:
banking_ds = load_dataset("argilla/banking_sentiment_setfit")
# preview dataset content
banking_ds["train"].to_pandas().head(15)
[5]:
| text | label | |
|---|---|---|
| 0 | 您要给我寄卡吗? | 1 |
| 1 | 两天前,我做了一笔转账到另一个账户... | 1 |
| 2 | 为什么我没有收到正确的现金金额? | 0 |
| 3 | 我的虚拟卡无法工作有什么原因吗? | 0 |
| 4 | 为什么转账后我的余额还是一样的? | 1 |
| 5 | 我的钱还没有转账。 | 0 |
| 6 | 它还在待处理,我还在等待。 您的... | 0 |
| 7 | 你们将卡片送到哪些地方? | 1 |
| 8 | 为什么我的取款突然被拒绝了? | 1 |
| 9 | 如何重置我的密码? | 1 |
| 10 | 我没有看到我转入这个账户的钱... | 0 |
| 11 | SEPA 转账我要花多少钱? | 1 |
| 12 | 请向我提供... | 1 |
| 13 | 您能告诉我如何知道我的资金来自哪里吗... | 1 |
| 14 | 我无法让充值工作! 怎么回事... | 0 |
关于情感分析和数据注释的说明#
情感分析是 NLP 中最主观的任务之一。 我们对情感的理解会因应用程序而异,并且取决于项目的业务目标。 此外,情感可以用不同的方式建模,从而导致不同的标注方案。
例如,情感可以建模为实值(从 -1 到 1,从 0 到 1.0 等)或使用 2 个或更多标签(包括不同程度的标签,如正面、负面、中性等)
对于本教程,我们将使用以下标注方案:POSITIVE、NEGATIVE 和 NEUTRAL。
1. 使用 GPT-3 构建零样本情感分类器#
为了构建零样本情感分类器,我们需要设计一个提示,这是一种称为“提示工程”的技术。 对于本教程,我们使用 OpenAI playground 试验了几个提示,并受到 Michele Pangrazzi 的优秀博客文章的启发。
我们将使用 Completion API,您可以查看参考文档以了解不同的函数参数。
为了找到提示模板,我们使用 OpenAI playground UI 尝试了不同的变体,如下所示
我们提示的主要结构是:
定义任务:客户请求的情感分类
定义格式和标签:我们想要三个标签和一个 JSON 格式(到目前为止,此格式仅适用于最新的且功能最强大的模型
text-davinci-003)定义要分类的文本:这部分将在我们数据集的每个示例中添加。
此提示最有趣的地方可能是我们要求模型解释其预测并将其添加到响应中。 稍后您将看到,这是一种强大的机制,可以理解模型决策、任务,甚至审查我们手动标注的真实标签。
由于我们想测试零样本功能,因此我们不会提供任何示例。 在后续教程中,我们将通过在提示本身中提供示例来扩展到 N 样本,并展示如何使用标注的示例微调 GPT-3。 如果您有兴趣,请加入我们令人惊叹的社区,让我们讨论一下!
下面我们定义提示模板,在调用 openai.Completion.create 函数之前,我们将要分类的文本附加到该模板。
[161]:
PROMPT_TEMPLATE = """
Classify the sentiment of the customer request using the following JSON format. Use positive, negative, and neutral in lowercase:
{"prediction": sentiment label string, "explanation": sentence string describing why you think is the sentiment}
Customer request:
"""
现在,让我们定义我们的分类函数。 此函数将输入文本添加到提示模板,调用 OpenAI API,并尝试解析 JSON 响应。 在我们的一些实验中,有时返回的 JSON 无效。 我们考虑到这一点,并将这些预测标记为 None,并将 json 响应添加到解释字段中。
注意
如果您想跳过对 OpenAI 的预测调用,可以通过运行以下代码并直接转到步骤 2,从 Hugging Face Hub 加载带有预测和标签的记录
records = load_dataset("argilla/banking_sentiment_zs_gpt3", split="train")
rg.log(records, "banking_sentiment_zs_gpt3")
[162]:
# set your api key as ENV, for example with Python: os.environ["OPENAI_API_KEY"]
openai.api_key = os.getenv("OPENAI_API_KEY")
def classify(text):
# build prompt with template and input
prompt = f"{PROMPT_TEMPLATE}\n{text}\n"
# use create completion template
completion = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=256
)
# get first choice text
json_response = completion["choices"][0]["text"].strip()
try:
prediction = loads(json_response)
except:
# for some examples, json is not correctly formatted
return {"prediction": None, "explanation": f"Wrong JSON format: {json_response}" }
return prediction
现在,让我们为 banking 情感测试集中的每个示例调用此方法,以便我们可以将其与其他方法(SetFit、小样本 GPT-3 和其他方法)进行比较。
我们使用 datasets 库中的 map 方法,并在表格中显示结果,如下所示
[190]:
# let's predict over the test set to eval our zero-shot classifier
test_ds_with_preds = banking_ds["test"].map(lambda example: classify(example["text"]))
pd.set_option('display.max_colwidth', None)
test_ds_with_preds.to_pandas().head(15)
[190]:
| text | label | prediction | explanation | |
|---|---|---|---|---|
| 0 | 我的银行卡付款汇率有误 | 0 | negative | 客户对他们的银行卡付款汇率错误表示不满,表明是负面情绪。 |
| 1 | 我认为我的一笔银行卡付款被取消了。 | 1 | neutral | 客户表达了一种想法,但没有表达对情况的任何情感。 |
| 2 | 为什么我取现金要收费? | 1 | negative | 客户对取现金收费表示沮丧和困惑,表明是负面情绪。 |
| 3 | 我一周前存入现金到我的账户,但仍然不可用,请告诉我为什么? 我现在需要退回现金。 | 0 | negative | 客户对他们的现金延迟可用表示沮丧和迫切,表明是负面情绪。 |
| 4 | 你们接受现金吗? | 1 | neutral | 客户只是在问一个问题,没有表达任何情感。 |
| 5 | 充值金额是无限的吗? | 1 | neutral | 客户正在询问一个事实性问题,没有表达任何意见或情感。 |
| 6 | 我认为我是欺诈的受害者。 我注意到我的帐户上有一笔我没有进行的收费,因为我今天没有碰过我的卡。 您能撤销收费并退款吗? | 0 | negative | 客户对他们帐户上的欺诈性收费表示担忧,表明是负面情绪。 |
| 7 | 为什么我在账单上看到额外的 1 欧元收费? | 0 | neutral | 客户在提问,没有表达任何情感。 |
| 8 | 我试图将钱转给收款人,但他们没有收到正确的金额。 发生了什么事,我应该联系谁来帮助我? | 0 | negative | 客户对尚未解决的问题表示沮丧,表明是负面情绪。 |
| 9 | 我昨天存入的支票尚未列出。 这不是很慢吗? 我需要看到余额因该支票而增加。 | 0 | negative | 客户对他们的支票存款处理缓慢表示沮丧,表明是负面情绪。 |
| 10 | 我无法从 ATM 取钱 | 1 | negative | 客户对无法从 ATM 取钱表示沮丧,表明是负面情绪。 |
| 11 | 我的卡上有几笔付款显示我无需负责。 发生了什么事? 也许有人可以访问我的帐户。 | 0 | negative | 客户对他们的帐户安全表示担忧和担忧,表明是负面情绪。 |
| 12 | 您能激活我的卡吗 | 1 | neutral | 客户正在请求一项服务,这没有表明任何情感。 |
| 13 | 为什么现金提款会待处理? | 0 | neutral | 客户在提问,没有表达任何情感。 |
| 14 | 同一笔购买我被收取了两次费用! | 0 | negative | 客户对同一笔购买被收取两次费用表示沮丧,表明是负面情绪。 |
2. 评估我们的零样本情感分类器#
现在我们有了带有 GPT-3 零样本分类器预测的小型测试数据集。 现在是时候使用 Argilla 来评估我们的模型了。
首先,我们将构建数据集并使用 rg.log 方法将其记录到 Argilla 中。 我们将 explanation 作为输入的一部分包含在内,以便我们可以快速查看预测及其解释
[ ]:
import argilla as rg
# get the label strings to turn int ids into string names
labels = banking_ds["test"].features["label"].names
records = []
for example in test_ds_with_preds:
# create a record with ground-truth annotations and gpt-3 predictions
record = rg.TextClassificationRecord(
inputs={"text": example["text"], "explanation": example["explanation"]},
annotation=labels[example["label"]],
prediction=[(example["prediction"].lower(), 1.0)]
)
records.append(record)
# create a dataset in Argilla
rg.log(records, "banking_sentiment_zs_gpt3")
这将花费 1 秒,并在 Argilla UI 中创建一个完全可浏览的数据集。 现在让我们分析 GPT-3 预测的质量。
总体指标#
使用 metrics 模块,我们可以快速概览总体性能指标,如下所示。 该模型实现了约 0.77 F1 微平均值。
[180]:
f1("banking_sentiment_zs_gpt3").visualize()
另一个有趣的指标是按输入文本长度的分布
[181]:
text_length("banking_sentiment_zs_gpt3").visualize()
使用 ES 查询字符串 DSL,我们可以计算数据集中感兴趣区域的性能指标。 例如,我们可以看到,较长文本(> 175)和中性示例的性能远低于较短文本(<175)。
请注意,这是一个非常小的数据集,但对于较大的数据集,我们可以分析我们的模型是否难以处理较长的文本,或者例如,较长的文本是否往往是负面的。
[187]:
f1("banking_sentiment_zs_gpt3", query="metrics.text_length:[175 TO *]").visualize()
[188]:
f1("banking_sentiment_zs_gpt3", query="metrics.text_length:[* TO 175]").visualize()
细粒度分析#
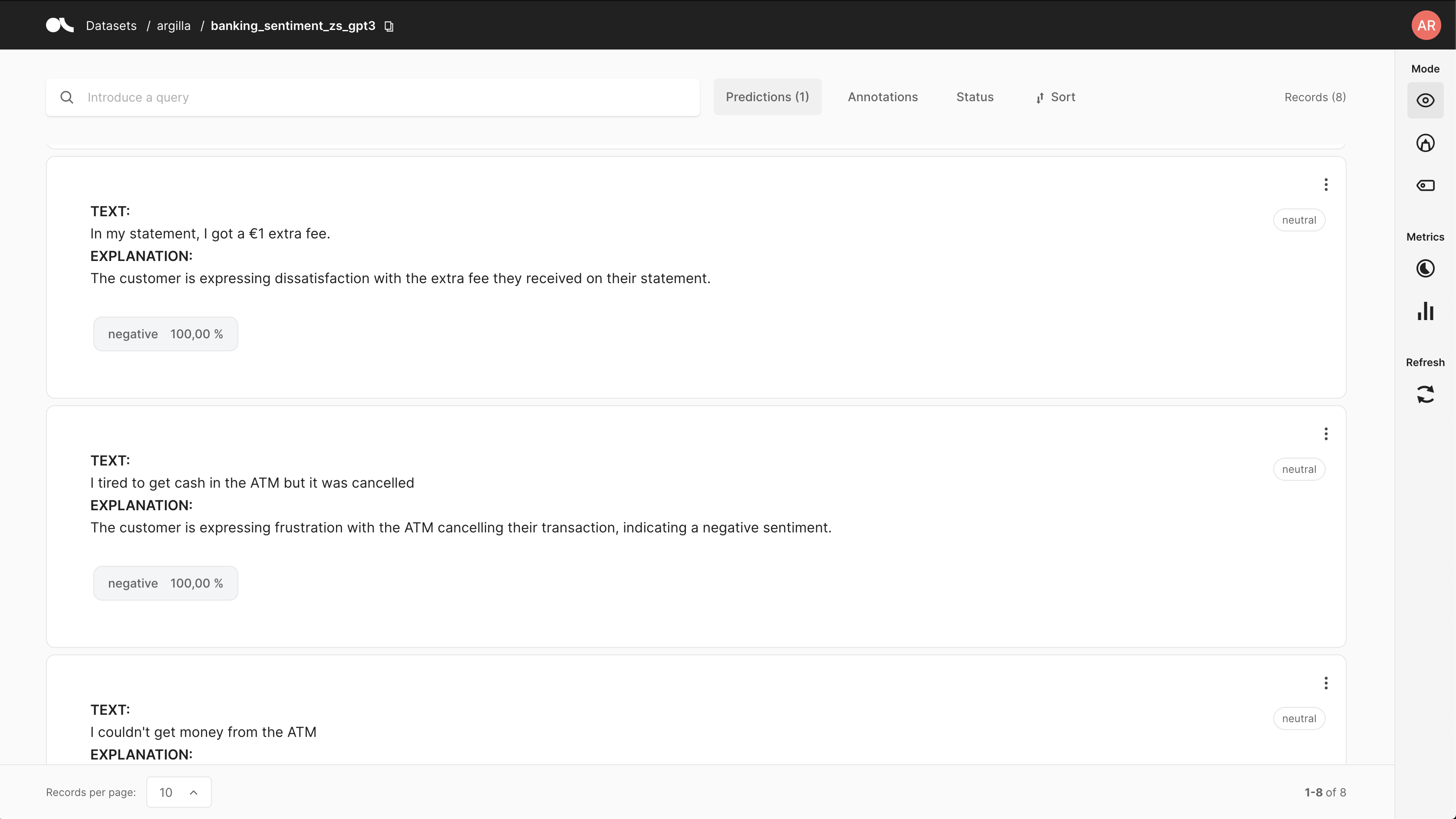
现在让我们使用 Argilla UI 对“不正确”的预测进行细粒度分析。 您可以使用 predicted 过滤器轻松完成此操作,如下所示
此过滤器将向您展示真实标签与 GPT-3 不一致的位置。 它还将向您展示 GPT-3 预测背后的解释。 查看一些示例,例如下面显示的示例,我们发现真实标签中的某些标签可能是错误的或至少是模棱两可的。 对于其他示例,可以通过示例或改进提示来更好地指导 GPT-3。
这突出了在使用 GPT-3 等大型语言模型的服务之上构建人工参与工作流程的潜力。