使用 classy-classification 进行文本分类主动学习#
在本教程中,我们将向您展示如何在直接的主动学习循环中使用直观的少样本学习包。它将引导您完成以下步骤
💿 将数据加载到 Argilla 中
⏱ 使用
classy-classification训练少样本分类器🕵🏽♂️ 定义主动学习启发式方法
🔁 设置主动学习循环
🎥 实时演示视频
简介#
主动学习中可能出现的难题之一是模型更新的速度。 Transformer 模型非常出色,但确实需要 GPU 进行微调,而人们并非总是能够访问这些资源。 同样,微调 Transformer 模型需要相当数量的初始数据。 幸运的是,classy-classification 可以用来解决这两个问题!
这些其他的积极学习方法可以在此处找到。
让我们开始吧!
运行 Argilla#
在本教程中,您需要运行 Argilla 服务器。 有两种主要的部署和运行 Argilla 的选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上拥有帐户,则只需单击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看官方 Hugging Face Hub 指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在本地机器上运行 Argilla,建议使用此选项。 请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。 有两种运行它的选项
使用此页面顶部的“在 Colab 中打开”按钮。 此选项允许您直接在 Google Colab 上运行 Notebook。 不要忘记将运行时类型更改为 GPU,以加快模型训练和推理速度。
单击页面顶部的“查看源代码”链接下载 .ipynb 文件。 此选项允许您下载 Notebook 并在本地计算机或您选择的 Jupyter Notebook 工具上运行它。
[ ]:
%pip install "classy-classification[onnx]==0.6.0" -qqq
%pip install "argilla[listeners]>=1.1.0" -qqq
%pip install datasets -qqq
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含我们需要的导入
[ ]:
from classy_classification import ClassyClassifier
from datasets import load_dataset
from argilla import listener
启用遥测#
我们从您与教程的互动中获得宝贵的见解。 为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。 虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。 有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
💿 将数据加载到 Argilla 中#
对于此分析,我们将使用来自 HuggingFace Hub 的我们的新闻数据集。 这是一个新闻分类任务,需要将文本分类为 4 个类别:["World", "Sports", "Sci/Tech", "Business"]。 由于与HuggingFace Hub 的良好集成,我们可以轻松地在几行代码内完成此操作。
[ ]:
# Load from datasets
my_dataset = load_dataset("argilla/news")
dataset_rg = rg.read_datasets(my_dataset["train"], task="TextClassification")
# Log subset into argilla
rg.log(dataset_rg[:500], "news-unlabelled")
现在我们已经加载了数据,我们可以开始为我们的少样本分类器创建一些训练示例。 为了获得良好的开端,我们将在 Argilla UI 中为每个类别标记大约 4 个标签。
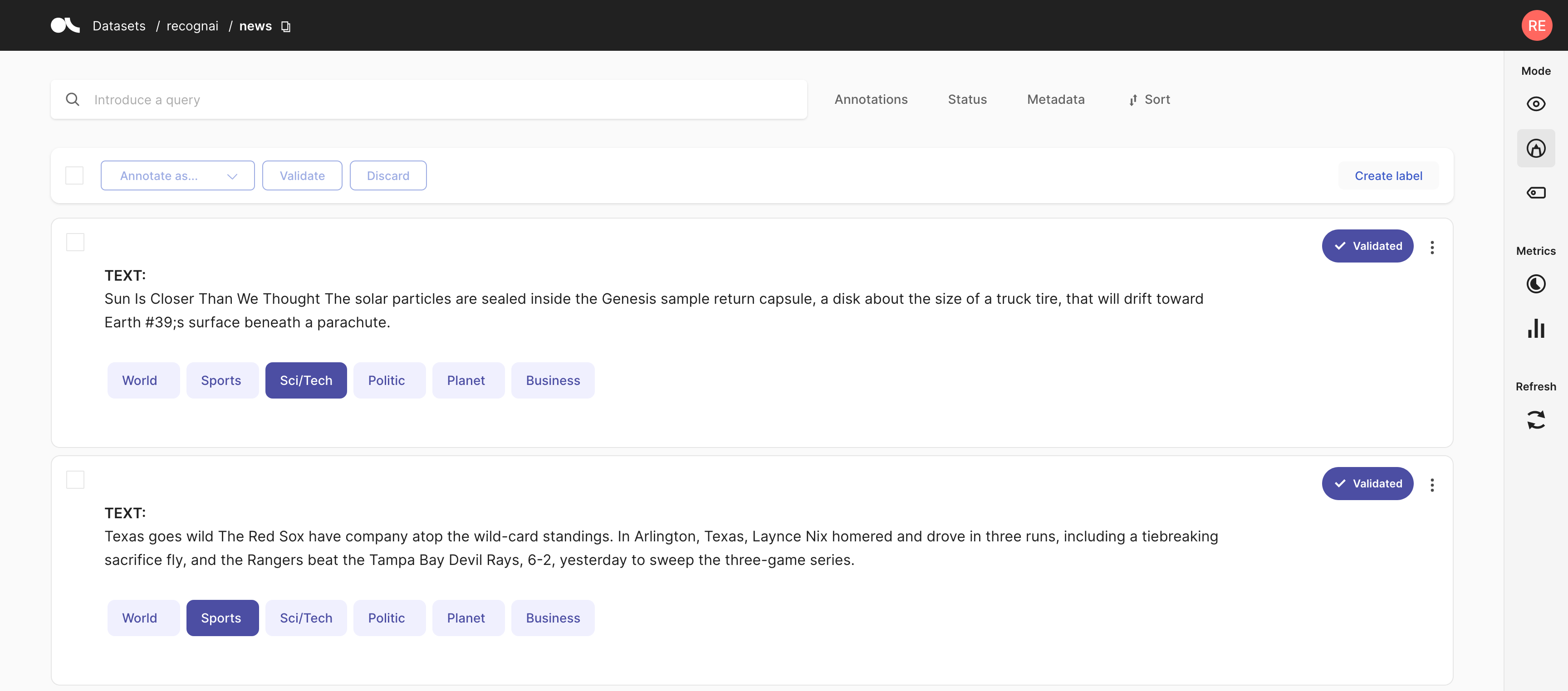
⏱ 训练少样本分类器#
使用标记的数据,我们现在可以为我们的少样本分类器获取训练样本。
[3]:
# Load the dataset
train_rg = rg.load("news-unlabelled", query="status: Validated")
# Get some annotated examples per class
n_samples_per_class = 5
data = {"World": [], "Sports": [], "Sci/Tech": [], "Business": []}
while not all([len(value)== n_samples_per_class for key,value in data.items()]):
for idx, rec in enumerate(train_rg):
if len(data[rec.annotation]) < n_samples_per_class:
data[rec.annotation].append(rec.text)
# Train a few-shot classifier
classifier = ClassyClassifier(data=data, model="all-MiniLM-L6-v2")
classifier("This texts is about games, goals, matches and sports.")
[3]:
{'Business': 0.2686566277246892,
'Sci/Tech': 0.2415910117784897,
'Sports': 0.22240821993980525,
'World': 0.267344140557016}
预测还不够好,但一旦我们开始主动学习循环,它们将会变得更好。
🕵🏽♂️ 主动学习启发式方法#
在主动学习循环期间,我们希望简化每次训练迭代期间的标注过程。 我们将通过以下方式做到这一点
每个循环使用
5个样本。定义确定性阈值为
0.9,对于该阈值,我们将假设可以自动验证预测。使用上一个循环中的模型推断记录预测分数。
检查和标注未达到自动验证的样本。
将标注的样本添加到我们的训练数据中。
为第二个循环的
5个样本进行预测。
在这些循环中,我们的预测将产生更确定的分数,这将使标注过程更容易。
[ ]:
# Define heuristic variables variables
NUM_SAMPLES_PER_LOOP = 5
CERTAINTY_THRESHOLD = 0.9
loop_data = data
# Load input data
ds = rg.load("news-unlabelled", query="status: Default", limit=1000)
# Create the active learning dataset
DATASET_NAME = "news-active-learning"
try:
rg.delete(DATASET_NAME)
except Exception:
pass
settings = rg.TextClassificationSettings(label_schema=list(data.keys()))
rg.configure_dataset_settings(name=DATASET_NAME, settings=settings)
# Evaluate and update records
def evaluate_records(records, idx = 0):
texts = [rec.text for rec in records]
predictions = [list(pred.items()) for pred in classifier.pipe(texts)]
for pred, rec in zip(predictions, records):
max_score = max(pred, key=lambda item: item[1])
if max_score[1] > CERTAINTY_THRESHOLD:
rec.annotation = max_score[0]
rec.status = "Validated"
rec.prediction = pred
rec.metadata = {"idx": idx}
return records
# Log initial predictions
ds_slice = evaluate_records(ds[:NUM_SAMPLES_PER_LOOP])
rg.log(ds[:NUM_SAMPLES_PER_LOOP], DATASET_NAME)
🔁 设置主动学习循环#
我们将使用Argilla 监听器设置主动学习循环。 Argilla 监听器使您能够构建细粒度的复杂工作流程作为后台进程,就像直接与 Argilla 集成的低调作业调度替代方案。 因此,它们非常适合等待新的标注并在后台添加记录新推断的预测。
请注意,重新启动循环也需要重置用于初始分类器训练的 data。
准备
启动循环
将状态过滤器设置为
Default验证最初记录的 10 条记录
不要忘记刷新记录页面
使用标注的数据更新分类器
对新数据进行预测
记录预测
标注第二个循环
[5]:
# Set up the active learning loop with the listener decorator
@listener(
dataset=DATASET_NAME,
query="(status:Validated OR status:Discarded) AND metadata.idx:{idx}",
condition=lambda search: search.total == NUM_SAMPLES_PER_LOOP,
execution_interval_in_seconds=1,
idx=0,
)
def active_learning_loop(records, ctx):
idx = ctx.query_params["idx"]
new_idx = idx+NUM_SAMPLES_PER_LOOP
print("1. train a few-shot classifier with validated data")
for rec in records:
if rec.status == "Validated":
loop_data[rec.annotation].append(rec.text)
classifier.set_training_data(loop_data)
print("2. get new record predictions")
ds_slice = ds[new_idx: new_idx+NUM_SAMPLES_PER_LOOP]
records_to_update = evaluate_records(ds_slice, new_idx)
texts = [rec.text for rec in ds_slice]
predictions = [list(pred.items()) for pred in classifier.pipe(texts)]
print("3. update query params")
ctx.query_params["idx"] = new_idx
print("4. Log the batch to Argilla")
rg.log(records_to_update, DATASET_NAME)
print("Done!")
print(f"Waiting for next {new_idx} annotations ...")
[ ]:
active_learning_loop.start()
🎥 实时演示视频#
为了向您展示在我们 UI 中的实际用法,我们创建了一个实时演示,您可以在下面观看。
总结#
在本教程中,我们学习了如何将主动学习器与 Argilla 一起使用,以及我们可以应用哪些启发式方法来定义主动学习器。 这可以帮助我们减少创建新的文本分类模型所需的开发时间。