🗺️ 将偏差平等特性添加到带有 disaggregators 的数据集中#
在本教程中,我们将向您展示如何使用 disaggregators 包来识别训练数据中潜在的偏差。我们将通过以下步骤引导您完成此操作
📰 加载新闻摘要数据
🗺️ 应用分解器特性
📊 分析潜在偏差
简介#
“解决机器学习模型中的公平性和偏差比以往任何时候都更加重要!公平性的一种形式是不同群体或特征之间的性能均等。为了衡量这一点,评估数据集必须根据不同的目标群体进行分解。” - HuggingFace。
简而言之,disaggregators 包旨在回答以下问题:“您的数据集中包含什么,以及这如何影响目标群体?”。
有关其他偏差和可解释性度量,请查看我们的 关于可解释性的其他教程。
让我们开始吧!
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部笔记本(例如 Google Colab)运行教程,并且您在 Hugging Face 上有帐户,则只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地机器上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能与外部笔记本服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是 Jupyter Notebook。有两种运行方式
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 notebook 并在本地机器或您选择的 Jupyter notebook 工具上运行它。
设置#
要完成本教程,您需要使用 pip 安装 Argilla 客户端和一些第三方库。您还需要从 spaCy 下载预训练模型
[ ]:
%pip install argilla disaggregators -qqq
!python -m spacy download en_core_web_lg -qqq
让我们导入 Argilla 模块以进行数据读取和写入
[1]:
import argilla as rg
如果您正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
现在让我们包含我们需要导入的库
[ ]:
from datasets import load_dataset
from disaggregators import Disaggregator
import pandas as pd
启用遥测#
我们从您与我们的教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
📰 加载新闻摘要数据#
对于此分析,我们将使用来自 HuggingFace Hub 的 我们的新闻摘要数据集。此数据集侧重于 text2text 摘要任务,该任务需要将新闻文本概括为单个句子或标题。由于与 HuggingFace Hub 的良好集成,我们可以轻松地在几行代码内完成此操作。
[ ]:
# load from datasets
my_dataset = load_dataset("argilla/news-summary")
dataset_rg = rg.read_datasets(my_dataset["train"], task="Text2Text")
# log subset into argilla
rg.log(dataset_rg[:1000], "news-summary", chunk_size=50) # set smaller chunk size to overcome io-issues
🗺️ 应用分解器特性#
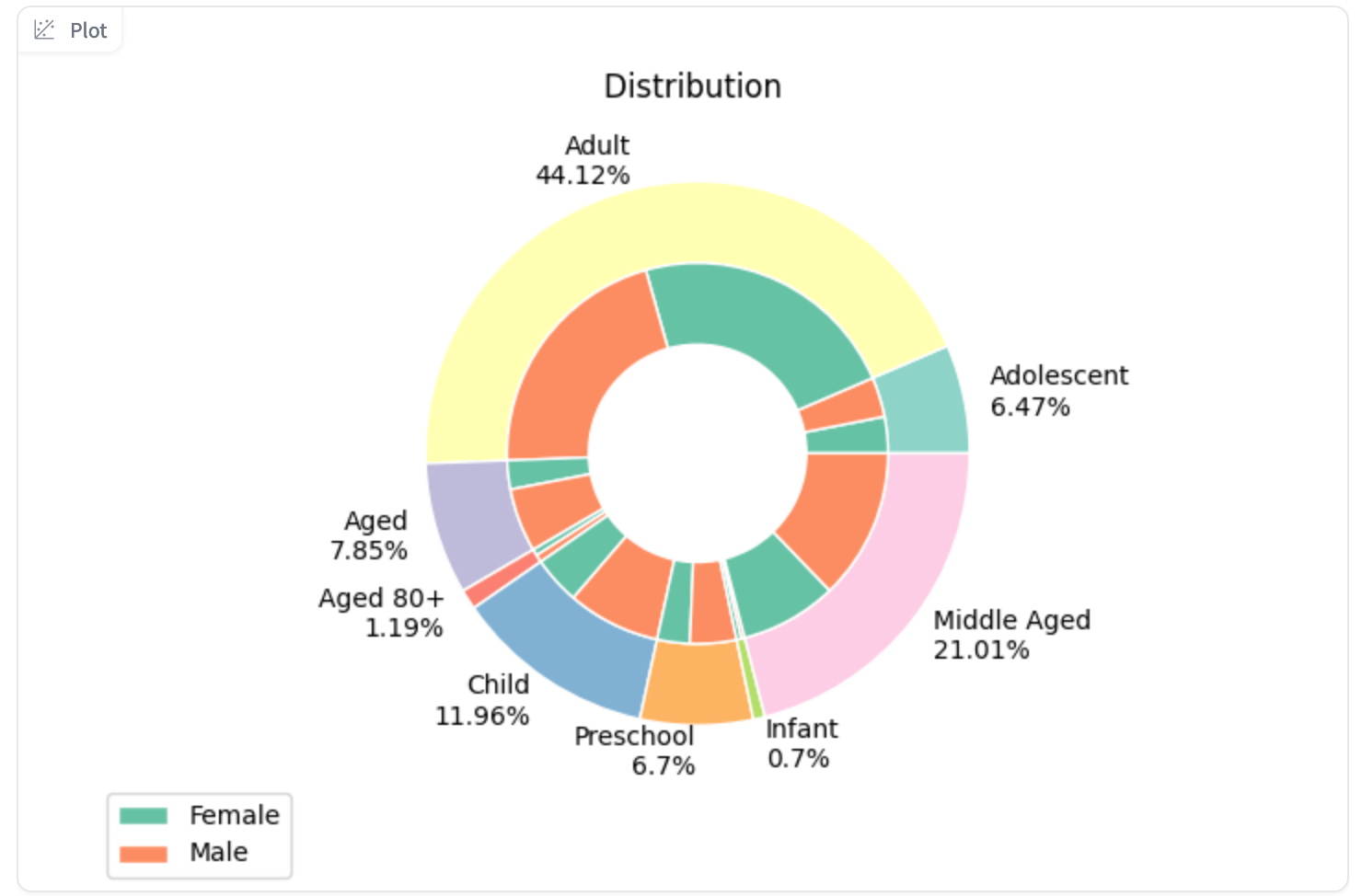
上传数据后,我们现在可以仔细查看 disaggregators 包提供的潜在分解器。它侧重于 5 个主要类别,以及可以根据单词匹配分配给文本的几个子类别。这意味着每个文本也可以分配给多个类别。
“age”:[“child”, “youth”, “adult”, “senior”]
“gender”:[“male”, “female”]
“pronoun”:[“she_her”, “he_him”, “they_them”]
“religion”:[“judaism”, “islam”, “buddhism”, “christianity”]
“continent”:[“africa”, “americas”, “asia”, “europe”, “oceania”]
即使我们可以选择应用所有类别,我们现在也只会使用 age 和 gender 来简化分析。
[18]:
disaggregator_classes = ["age", "gender"]
ds = rg.load("news-summary")
df = pd.DataFrame({"text": [rec.text for rec in ds]})
disaggregator = Disaggregator(disaggregator_classes, column="text")
new_cols = df.apply(disaggregator, axis=1)
df = pd.merge(df, pd.json_normalize(new_cols), left_index=True, right_index=True)
df.head(5)
[18]:
| text | age.child | age.youth | age.adult | age.senior | gender.male | gender.female | |
|---|---|---|---|---|---|---|---|
| 0 | 墨西哥城(路透社)- 墨西哥央行 go... | True | True | False | False | True | False |
| 1 | 华盛顿(路透社)- 特朗普政府... | True | False | False | True | True | False |
| 2 | 迪拜(路透社)- 伊朗已提供能力... | False | False | False | False | False | False |
| 3 | 棕榈滩,佛罗里达州(路透社)- 美国当选总统... | False | False | False | False | True | False |
| 4 | 华盛顿(路透社)- 美国参议员比尔·纳尔逊... | False | False | False | False | True | False |
现在,我们已经找到并逮捕了每个潜在的 disaggregators,我们可以将它们分配给每个记录的 metadata 变量,并在 Argilla 数据库中更新相同的记录 ID。
[ ]:
metadata_ds = df[df.columns[1:]].to_dict(orient="records")
for metadata_rec, rec in zip(metadata_ds, ds):
rec.metadata = metadata_rec
rg.log(ds, "news-summary", chunk_size=50) # upsert records
📊 分析潜在偏差#
在 UI 中,我们可以通过两种直接方式分析分配的偏差信息。
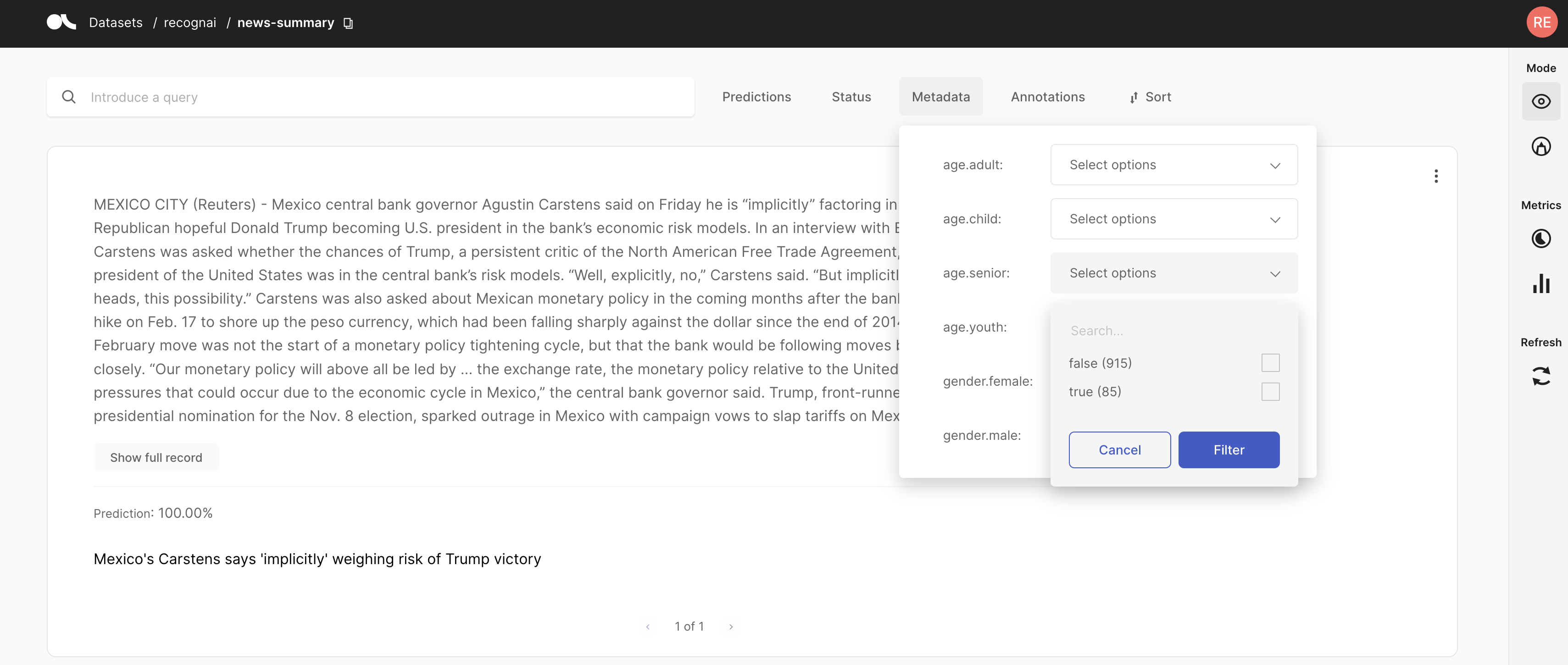
基于元数据信息筛选#
通过应用筛选器,我们可以选择平均分配标注数量,以应对潜在的偏差原因。通过这样做,我们确保最终的训练数据也均匀分布。或者,我们也可以决定仅标注没有分解的数据,假设它们不包含任何考虑的偏差。
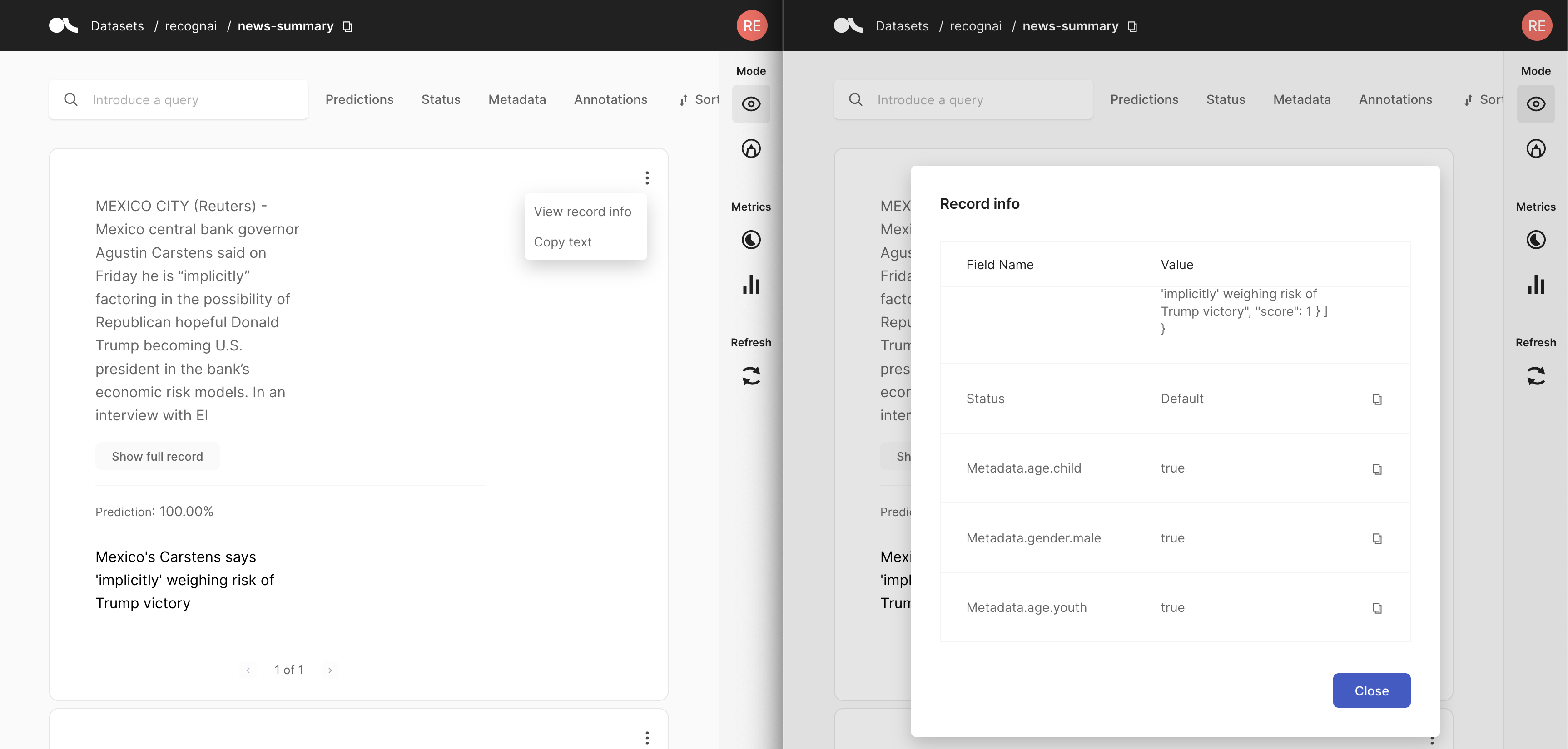
检查记录信息#
即使检查记录信息速度稍慢,我们也可以潜在地假设它可以为可能怀疑数据中存在偏差的标注者提供记录上下文。这将使他们能够在标注期间考虑到这一点。
替代方案#
除了上述分析之外,您可能还可以使用此包做更多有趣的事情。一个很好的例子是 这个 HuggingFace space。因此,发挥创意,同时避免偏差 😉
总结#
在本教程中,我们了解了 disaggregators 包,以及如何将其集成到 Argilla 中。这可以帮助数据科学家、ML 工程师和标注者管理和减轻数据集中的偏差。