其他数据集的工作流程#
欢迎!本文将介绍从日志数据到准备训练的默认工作流程。
注意
此工作流程涵盖 DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。有关 FeedbackDataset 的工作流程,请点击此处查看。不确定使用哪个数据集?请查看我们关于选择数据集的部分。
安装库#
在 Colab 中安装最新版本的 Argilla,以及本 notebook 中使用的其他库和模型。
[ ]:
!pip install argilla datasets transformers evaluate spacy-transformers transformers[torch] requests
!python -m spacy download en_core_web_sm
设置 Argilla#
如果您已经部署了 Argilla Server,则可以跳过此步骤。否则,您可以通过两种不同的方式快速部署它
您可以将 Argilla Server 部署在 HF Spaces 上。
或者,如果您想在您自己的计算机上本地运行 Argilla,则启动并运行 Argilla UI 的最简单方法是在 Docker 上部署
docker run -d --name quickstart -p 6900:6900 argilla/argilla-quickstart:latest
有关安装的更多信息,请点击此处。
连接到 Argilla#
可以通过简单地导入 Argilla 库并使用环境变量和 rg.init() 连接到我们的 Argilla 实例。
ARGILLA_API_URL:这是 Argilla Server 的 URL。如果您正在使用 Docker,则默认情况下为
https://:6900。如果您正在使用 HF Spaces,则其构造为
https://[你的所有者名称]-[你的空间名称].hf.space。
ARGILLA_API_KEY:这是 Argilla Server 的 API 密钥。默认情况下为owner。HF_TOKEN:这是 Hugging Face API 令牌。仅当您使用 私有 HF Space 时才需要。您可以在您的个人资料中配置它:设置 > 访问令牌。workspace:这是您的 Argilla 实例内部的“空间”,授权用户可以在其中协作。默认情况下为argilla。
有关自定义配置(如标头、工作区隔离或访问凭据)的更多信息,请查看我们的配置页面。
[1]:
import argilla as rg
from argilla._constants import DEFAULT_API_KEY
[2]:
# Argilla credentials
api_url = "https://:6900" # "https://<YOUR-HF-SPACE>.hf.space"
api_key = DEFAULT_API_KEY # admin.apikey
# Huggingface credentials
hf_token = "hf_..."
[3]:
rg.init(api_url=api_url, api_key=api_key)
# # If you want to use your private HF Space
# rg.init(extra_headers={"Authorization": f"Bearer {hf_token}"})
C:\Users\sarah\Documents\argilla\src\argilla\client\client.py:154: UserWarning: Default user was detected and no workspace configuration was provided, so the default 'argilla' workspace will be used. If you want to setup another workspace, use the `rg.set_workspace` function or provide a different one on `rg.init`
warnings.warn(
启用遥测#
我们从您与教程的交互中获得宝贵的见解。为了改进我们为您提供最合适内容的方式,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
上传数据#
Argilla 数据模型的主要组件称为 记录。记录可以是不同的类型,具体取决于当前支持的任务
TextClassificationRecordTokenClassificationRecordText2TextRecord
所有类型记录最关键的属性是
text:记录的输入文本(必需);annotation:以特定于任务的方式标注您的记录(可选);prediction:将特定于任务的模型预测添加到记录(可选);metadata:向记录添加一些任意元数据(可选);
Argilla 中的数据集是相同类型记录的集合。
[ ]:
# Create a basic text classification record
textcat_record = rg.TextClassificationRecord(
text="Hello world, this is me!",
prediction=[("LABEL1", 0.8), ("LABEL2", 0.2)],
annotation="LABEL1",
multi_label=False,
)
# Create a basic token classification record
tokencat_record = rg.TokenClassificationRecord(
text="Michael is a professor at Harvard",
tokens=["Michael", "is", "a", "professor", "at", "Harvard"],
prediction=[("NAME", 0, 7), ("LOC", 26, 33)],
)
# Create a basic text2text record
text2text_record = rg.Text2TextRecord(
text="My name is Sarah and I love my dog.",
prediction=["Je m'appelle Sarah et j'aime mon chien."],
)
# Upload (log) the records to corresponding datasets in the Argilla web app
rg.log(textcat_record, "my_textcat_dataset")
rg.log(tokencat_record, "my_tokencat_dataset")
rg.log(tokencat_record, "my_text2text_dataset")
现在您可以访问 Argilla Web 应用程序中的数据集,并查看您的第一批记录。
但是,大多数时候,您的数据将采用某种文件格式,例如 TXT、CSV 或 JSON。Argilla 依赖于两个著名的 Python 库来读取这些文件:pandas 和 datasets。在使用这些库之一读取文件后,Argilla 提供了快捷方式来自动创建您的记录。请确保将列名与您要创建的记录类型的必需属性相匹配。
# Using a pandas dataframe
dataset_rg = rg.read_pandas(dataframe, task="TextClassification")
# Using a Dataset
dataset_rg = rg.read_datasets(dataset, task="TokenClassification")
如前所述,您根据要处理的任务选择记录类型。
1. 文本分类#
在我们的示例中,我们将使用 Hugging Face 上提供的 IMDb 数据集的一部分。此处的底层任务可能是按情感对评论进行分类。
[75]:
from datasets import load_dataset
dataset = load_dataset("imdb", split="train").shuffle(seed=42).select(range(100))
[36]:
dataset[0]
[36]:
{'text': 'There is no relation at all between Fortier and Profiler but the fact that both are police series about violent crimes. Profiler looks crispy, Fortier looks classic. Profiler plots are quite simple. Fortier\'s plot are far more complicated... Fortier looks more like Prime Suspect, if we have to spot similarities... The main character is weak and weirdo, but have "clairvoyance". People like to compare, to judge, to evaluate. How about just enjoying? Funny thing too, people writing Fortier looks American but, on the other hand, arguing they prefer American series (!!!). Maybe it\'s the language, or the spirit, but I think this series is more English than American. By the way, the actors are really good and funny. The acting is not superficial at all...',
'label': 1}
正如我们所见,数据集有两列:text 和 label。我们将使用标签作为我们记录的标注。因此,为了匹配 TextClassificationRecord 的必需属性,我们需要重命名列。
[76]:
dataset = dataset.rename_column("label", "annotation")
现在,我们可以检查我们的数据集。
[77]:
dataset.select(range(3)).to_pandas()
[77]:
| text | annotation | |
|---|---|---|
| 0 | Fortier 和 ... 之间根本没有关系 ... | 1 |
| 1 | 这部电影很棒。情节非常真实 ... | 1 |
| 2 | George P. Cosmatos 的“第一滴血” ... | 0 |
一旦我们检查一切正确,我们就可以将其转换为 Argilla 数据集。
[ ]:
dataset_rg = rg.read_datasets(dataset, task="TextClassification")
我们将此数据集上传到 Web 应用程序,并将其命名为 imdb
[ ]:
rg.log(dataset_rg, "imdb")
您可以使用 configure_dataset_settings 方法以编程方式配置标签
labels = ["pos", "neg"]
settings = rg.TextClassificationSettings(label_schema=labels)
rg.configure_dataset_settings(name="imdb", settings=settings)
2. 令牌分类#
在此示例中,我们将使用 Hugging Face 的 ag_news。此处的底层任务可能是提取新闻标题中描述的事件中涉及的地点和人物。
因此,我们将首先加载数据集并对其进行分析。
[78]:
from datasets import load_dataset
dataset = load_dataset("ag_news", split="train").shuffle(seed=50).select(range(100))
[79]:
# The best way to visualize a Dataset is actually via pandas
dataset.select(range(3)).to_pandas()
[79]:
| text | label | |
|---|---|---|
| 0 | 比尔队米洛伊准备在本赛季首次亮相 (美联社) ... | 1 |
| 1 | MLB:亚特兰大 6,休斯顿 5 JD Drew 扩大了亚特兰 ... | 1 |
| 2 | PARMALAT:金融时报,邦迪想要从 I ... 获得 10 亿美元 | 2 |
由于在这种情况下不需要标签,我们将将其作为元数据添加。
[ ]:
def metadata_to_dict(row):
metadata = {}
metadata["label"] = row["label"]
row['metadata'] = metadata
return row
dataset = dataset.map(metadata_to_dict, remove_columns=["label"])
与其他类型相反,令牌分类记录需要输入文本和相应的令牌。因此,让我们在一个小的辅助函数中对输入文本进行令牌化,并将令牌添加到名为 tokens 的新列中。
注意
我们将使用 spaCy 对文本进行令牌化,但您可以使用您喜欢的任何库。
[ ]:
import spacy
# Load a english spaCy model to tokenize our text
nlp = spacy.load("en_core_web_sm")
# Define our tokenize function
def tokenize(row):
tokens = [token.text for token in nlp(row["text"])]
return {"tokens": tokens}
# Map the tokenize function to our dataset
dataset = dataset.map(tokenize)
让我们快速浏览一下我们扩展的 Dataset
[82]:
dataset.select(range(3)).to_pandas()
[82]:
| text | metadata | tokens | |
|---|---|---|---|
| 0 | 比尔队米洛伊准备在本赛季首次亮相 (美联社) ... | {'label': 1} | [比尔队, ', 米洛伊, 准备, 在, 本赛季, 首次, 亮相, (, 美联社, ), ...] |
| 1 | MLB:亚特兰大 6,休斯顿 5 JD Drew 扩大了亚特兰 ... | {'label': 1} | [MLB, :, 亚特兰大, 6, ,, 休斯顿, 5, JD, Drew, ...] |
| 2 | PARMALAT:金融时报,邦迪想要从 I ... 获得 10 亿美元 | {'label': 2} | [PARMALAT, :, 金融时报, ,, 邦迪, 想要, 1, BLN, DOL ...] |
我们现在可以使用 Argilla 读取此 Dataset,这将自动创建记录并将它们放入 Argilla Dataset 中。
[69]:
# Read Dataset into a Argilla Dataset
dataset_rg = rg.read_datasets(dataset, task="TokenClassification")
我们将此数据集上传到 Web 应用程序,并将其命名为 ag_news。
[ ]:
# Log the dataset to the Argilla web app
rg.log(dataset_rg, "ag_news")
您可以使用 configure_dataset_settings 方法以编程方式配置标签
labels = ["PER", "ORG", "LOC", "MISC"]
settings = rg.TokenClassificationSettings(label_schema=labels)
rg.configure_dataset_settings(name="ag_news", settings=settings)
您还可以在 Dataset:nbsphinx-math:`Settings` 中创建标签并开始标注
3. 文本到文本#
在本例中,我们将使用欧洲疾病预防控制中心的英语句子,这些句子可在 Hugging Face Hub 上找到。此处的底层任务可能是将句子翻译成其他欧洲语言。
[83]:
from datasets import load_dataset
# Load the Dataset from the Hugging Face Hub and extract a subset of the train split as example
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train").shuffle(seed=30).select(range(100))
并快速浏览一下结果 dataset Dataset 的第一行
[ ]:
dataset[0]
{'translation': {'en': 'Vaccination against hepatitis C is not yet available.',
'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
我们可以看到英语句子嵌套在 translation 列内的字典中。
为了将英语句子提取到新的 text 列中,我们将编写一个快速辅助函数,并使用它 map 整个 Dataset。
法语句子将被提取到新的 prediction 列中,并用“[ ]”括起来,因为 Text2TextRecord 的预测字段接受字符串或元组列表。
[ ]:
# Define our helper extract function
def extract(row):
return {"text": row["translation"]["en"], "prediction":[row["translation"]["fr"]]}
# Map the extract function to our dataset
dataset = dataset.map(extract, remove_columns = ["translation"])
让我们快速浏览一下我们扩展的 Dataset
[ ]:
dataset.select(range(3)).to_pandas()
| text | prediction | |
|---|---|---|
| 0 | 尚未提供针对丙型肝炎的疫苗接种 ... | [Aucune vaccination contre l’hépatite C n’est ... |
| 1 | 艾滋病毒感染 | [艾滋病毒感染] |
| 2 | 人类免疫缺陷病毒 (HIV) 仍然是 ... | [L’infection par le virus de l’immunodéficienc ... |
我们现在可以使用 Argilla 读取此 Dataset,这将自动创建记录并将它们放入 Argilla Dataset 中。
[ ]:
# Read Dataset into a Argilla Dataset
dataset_rg = rg.read_datasets(dataset, task="Text2Text")
我们将此数据集上传到 Web 应用程序,并将其命名为 ecdc_en
[ ]:
# Log the dataset to the Argilla web app
rg.log(dataset_rg, "ecdc_en")
标注数据集#
Argilla 提供了几种标注数据的方法。使用 Argilla 的 UI,您可以混合和匹配以下选项
使用针对每种任务类型优化的专用界面手动标注每个记录;
利用用户提供的模型并验证其预测;
定义启发式规则以生成“噪声标签”,然后可以将其与弱监督相结合;
每种方法都有其优点和缺点,最佳匹配很大程度上取决于您的个人用例。
标注指南#
在团队开始标注过程之前,重要的是统一团队中每个人认为自己拥有的不同真理。因为同一文本将由多个标注者独立标注,或者我们可能希望稍后重新访问旧数据集。除了显而易见的错误之外,我们还经常遇到不确定的灰色区域。考虑以下用于 NER 标注的短语 Harry Potter and the Prisoner of Azkaban 可以通过多种方式解释。整个短语作为电影标题,Harry Potter 是一个人,而 Azkaban 是一个地点。也许我们甚至不想标注虚构的地点和人物。因此,重要的是预先定义这些假设,并与团队一起迭代它们。查看我们来自 suberb.ai 的朋友的这篇博客或 Grammarly 的这篇博客,了解更多背景信息。
1. 手动标注#
如果您没有适用于您的用例的合适模型,或者无法为您的数据集提出良好的启发式规则,则可能需要手动标注的直接方法。如果您拥有大量的标注劳动力,或者需要少量但公正且高质量的标签,那么它也可能是一个好方法。
Argilla 试图使这种相对繁琐的方法尽可能轻松。通过直观且自适应的 UI、其详尽的搜索和筛选功能以及批量标注功能,Argilla 将手动标注过程转变为高效的选择。
查看我们专门的功能参考,以获取有关使用 Argilla 手动标注数据集的详细且说明性的指南。
2. 验证预测#
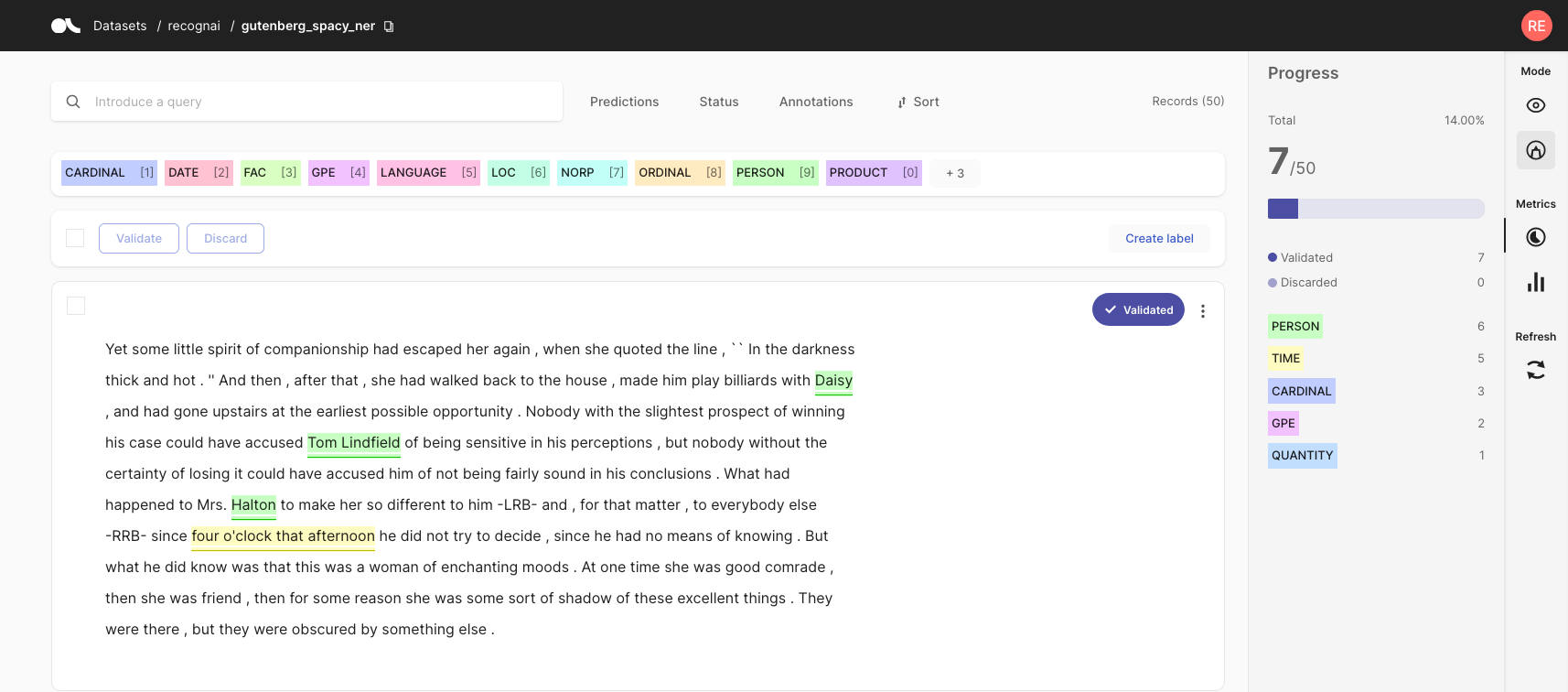
如今,许多预训练或零样本模型都可以通过模型存储库(如 Hugging Face Hub)在线获得。在大多数情况下,您可能会找到一个已经适合您的特定数据集任务的模型。在 Argilla 中,您可以通过在记录中包含来自这些模型的预测来预先标注您的数据。假设该模型在您的数据集上运行良好,您可以筛选出具有高预测分数的记录并验证预测。通过这种方式,您将快速标注部分数据,并减轻标注过程的负担。
这种方法的一个缺点是您的标注将受到预训练模型可能存在的偏差和错误的影响。当受到预训练模型的引导时,通常会看到人工标注者受到它们的影响。因此,在为最终模型评估构建严格的测试集时,建议避免预先标注。
查看入门教程,了解如何将预测添加到记录中。我们的功能参考包括有关在 Argilla Web 应用程序中验证预测的详细指南。
3. 弱标注规则#
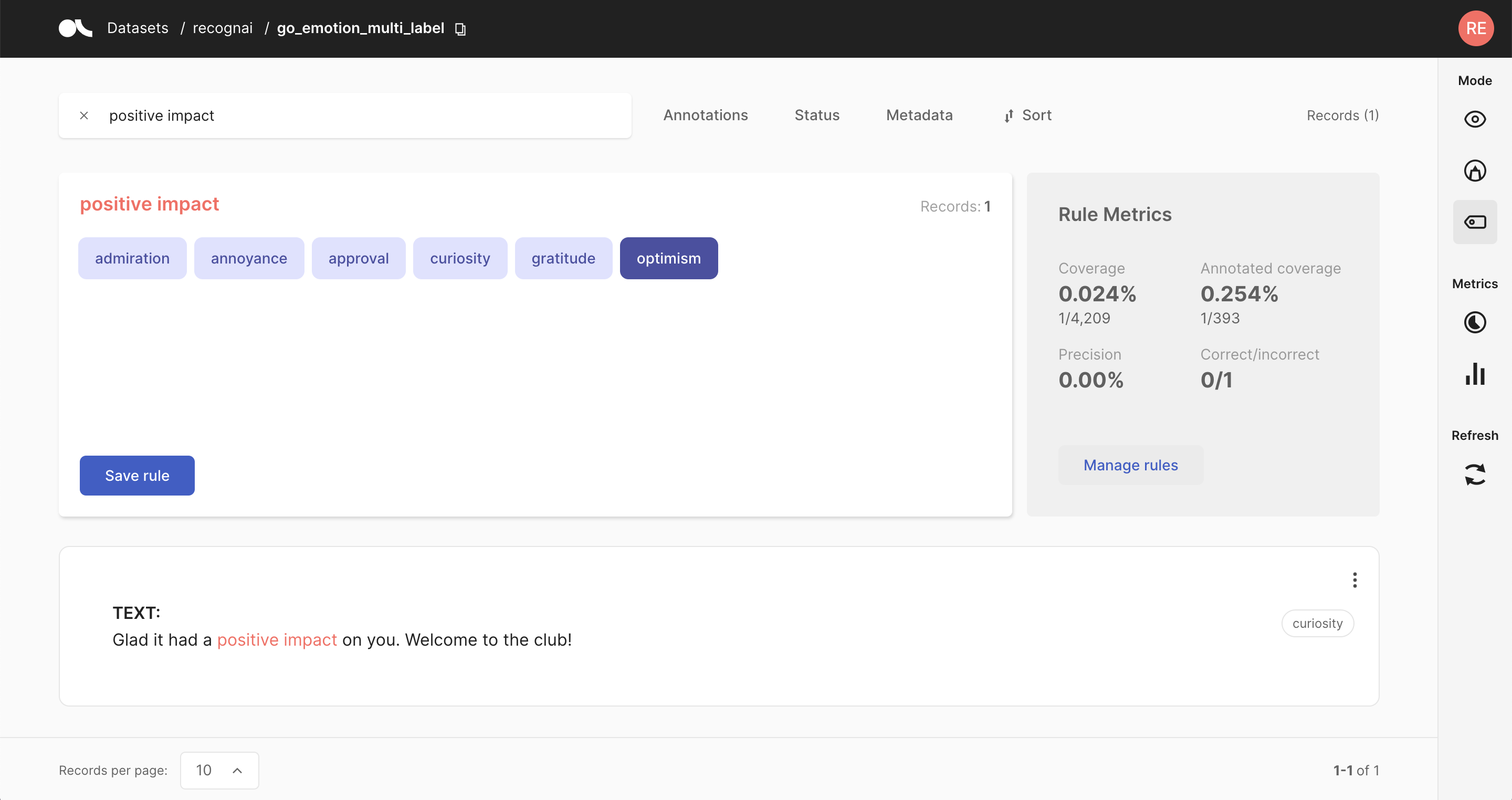
标注数据的另一种方法是定义针对您的数据集量身定制的启发式规则。例如,让我们假设您想将新闻文章分类为金融、体育和文化类别。在这种情况下,一个合理的规则是将所有包含“股票”一词的文章标记为金融。
规则可以变得任意复杂,并且还可以包括记录的元数据。这种方法的缺点是,对于某些数据集,提出可行的启发式规则可能具有挑战性。此外,规则很少 100% 精确,并且经常相互冲突。可以使用弱监督和标签模型来清理这些噪声标签,或者使用像多数投票这样简单的东西。这通常是在标注数据量和标签质量之间进行权衡。
查看我们的指南,以获取有关使用 Argilla 进行弱监督的广泛介绍。此外,请查看功能参考,了解 Web 应用程序的“定义规则”模式,并查看我们的各种教程,以查看弱监督工作流程的实际示例。
训练模型#
ArgillaTrainer 是我们许多最喜欢的 NLP 库的包装器。它提供了一个非常直观的抽象工作流程,以方便使用体面的默认预设配置进行简单的训练工作流程,而无需担心 Argilla 的任何数据转换。更多信息请点击此处。
[ ]:
from argilla.training import ArgillaTrainer
sentence = "I love this film, but the new remake is terrible."
trainer = ArgillaTrainer(
name="imdb",
workspace="argilla",
framework="spacy",
train_size=0.8
)
trainer.update_config(max_epochs=1, max_steps=1)
trainer.train(output_dir="my_easy_model")
records = trainer.predict(sentence, as_argilla_records=True)
# Print the prediction
print("\ntesting predictions...")
print(sentence)
print(f"Predicted_label: {records.prediction}")
Argilla 帮助您创建和管理训练数据。 它不是用于训练模型的完整框架,但我们确实提供集成。 您可以将 Argilla 与其他专注于开发和训练 NLP 模型的优秀开源框架互补使用。
这里我们列出了三个最常用的开源库,但还有更多可用的库,可能更适合您的特定用例
transformers:此库为各种 NLP 任务和模态提供数千个预训练模型。其出色的文档侧重于将这些模型微调到您的特定用例;
spaCy:此库还附带内置于管道中的预训练模型,可同时处理多个任务。由于它是一个纯粹的 NLP 库,因此它具有比模型训练更多的 NLP 功能;
spark-nlp:Spark NLP 是一个开源文本处理库,用于 Python、Java 和 Scala 编程语言的先进自然语言处理。该库构建于 Apache Spark 及其 Spark ML 库之上。
scikit-learn:这个事实上的标准库是用于机器学习的强大瑞士军刀,具有一些 NLP 支持。通常,与 transformers 或 spacy 相比,它们的 NLP 模型缺乏性能,但如果您想快速训练轻量级模型,请尝试一下;