🤔 使用建议和回复#
反馈数据集#
注意
本节涵盖的数据集类是 FeedbackDataset。这个完全可配置的数据集将在 Argilla 2.0 中取代 DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。不确定使用哪个数据集?请查看我们关于选择数据集的部分。

与元数据和向量不同,suggestions 和 responses 未定义为 FeedbackDataset 模式的一部分。相反,它们在您创建记录时添加到记录中。
格式化 suggestions#
建议指的是可以添加到记录中的建议回复(例如,模型预测),以加快标注过程。这些可以在创建记录期间或稍后阶段添加。每个问题只能提供一个建议,并且建议值必须符合预定义的问题,例如,如果我们有一个 1 到 5 的 RatingQuestion,则建议应具有该范围内的有效值。
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "relevant",
"value": "YES",
"score": 0.7,
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "content_class",
"value": ["hate", "violent"],
"score": [0.3, 0.2],
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "preference",
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
"score": [0.20, 0.10, 0.01],
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "quality",
"value": 5,
"score": 0.7,
"agent": model_name,
}
]
)
from argilla.client.feedback.schemas import SpanValueSchema
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "entities",
"value": [
SpanValueSchema(
start=0, # position of the first character of the span
end=10, # position of the character right after the end of the span
label="ORG",
score=1.0
)
],
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "corrected-text",
"value": "This is a *suggestion*.",
"score": 0.7,
"agent": model_name,
}
]
)
添加 suggestions#
要将建议添加到记录中,这稍微取决于您使用的是 FeedbackDataset 还是 RemoteFeedbackDataset。有关端到端示例,请查看我们的关于添加建议和回复的教程。
注意
尚未推送到 Argilla 或从 HuggingFace Hub 拉取的数据集是 FeedbackDataset 的实例,而从 Argilla 拉取的数据集是 RemoteFeedbackDataset 的实例。两者之间的区别在于,前者是本地数据集,对其所做的更改保留在本地。另一方面,后者是远程数据集,对其所做的更改直接反映在 Argilla 服务器上的数据集上,这可以加快您的流程。
for record in dataset.records:
record.suggestions = [
{
"question_name": "relevant",
"value": "YES",
"agent": model_name,
}
]
modified_records = []
for record in dataset.records:
record.suggestions = [
{
"question_name": "relevant",
"value": "YES",
"agent": model_name,
}
]
modified_records.append(record)
dataset.update_records(modified_records)
注意
您也可以遵循相同的策略来修改现有建议。
格式化 responses#
如果您的数据集包含一些注释,您可以在创建记录时将其添加到记录中。确保回复遵循与 Argilla 输出相同的格式,并满足所回答的特定问题类型的模式要求。另请确保包含 user_id,以防您计划为同一问题添加多个回复。您只能使用空的 user_id 指定一个回复:user_id=None 的首次出现将被设置为活动的 user_id,而其余 user_id=None 的回复将被丢弃。
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"relevant":{
"value": "YES"
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"content_class":{
"value": ["hate", "violent"]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"preference":{
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"quality":{
"value": 5
}
}
}
]
)
from argilla.client.feedback.schemas import SpanValueSchema
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"entities":{
"value": [
SpanValueSchema(
start=0,
end=10,
label="ORG"
)
]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
)
添加 responses#
要将回复添加到记录中,这稍微取决于您使用的是 FeedbackDataset 还是 RemoteFeedbackDataset。有关端到端示例,请查看我们的关于添加建议和回复的教程。
注意
尚未推送到 Argilla 或从 HuggingFace Hub 拉取的数据集是 FeedbackDataset 的实例,而从 Argilla 拉取的数据集是 RemoteFeedbackDataset 的实例。两者之间的区别在于,前者是本地数据集,对其所做的更改保留在本地。另一方面,后者是远程数据集,对其所做的更改直接反映在 Argilla 服务器上的数据集上,这可以加快您的流程。
for record in dataset.records:
record.responses = [
{
"values":{
"label":{
"value": "YES",
}
}
}
]
from datetime import datetime
modified_records = []
for record in dataset.records:
record.responses = [
{
"values":{
"label":{
"value": "YES",
}
},
"inserted_at": datetime.now(),
"updated_at": datetime.now(),
}
]
modified_records.append(record)
dataset.update_records(modified_records)
注意
您也可以遵循相同的策略来修改现有回复。
其他数据集#
注意
本节中涵盖的记录类对应于三个数据集:DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。这些将在 Argilla 2.0 中弃用,并由完全可配置的 FeedbackDataset 类取代。不确定使用哪个数据集?请查看我们关于选择数据集的部分。
添加 suggestions#
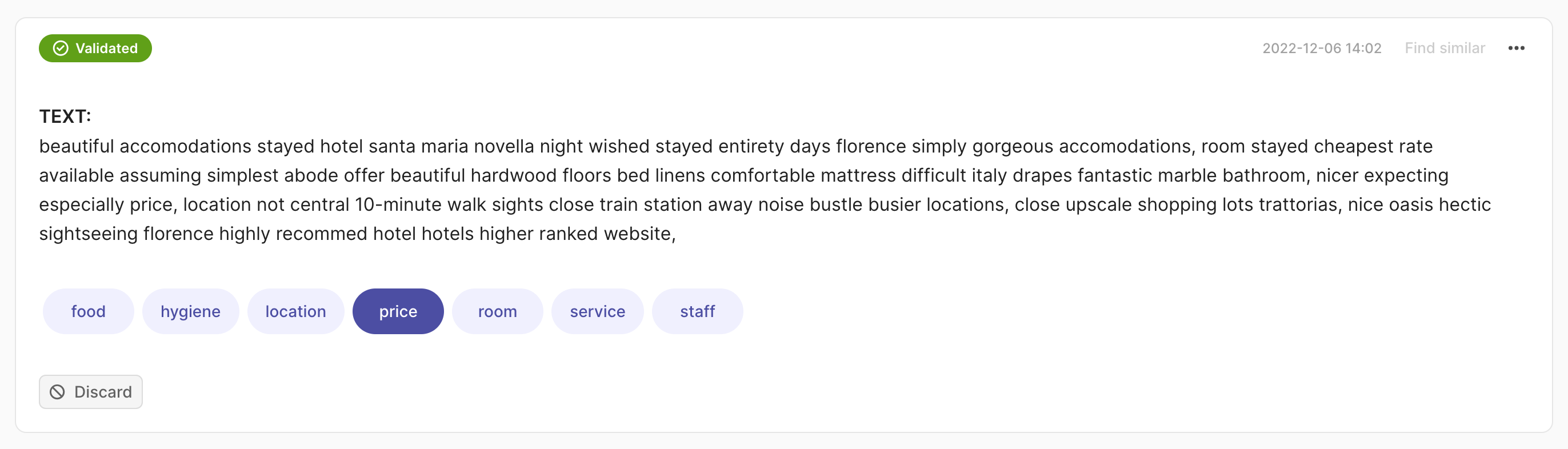
建议指的是可以添加到记录中的建议回复(例如,模型预测),以加快标注过程。这些可以在创建记录期间或稍后阶段添加。我们允许每个记录有多个建议。
在这种情况下,我们期望一个 List[Tuple[str, float]] 作为预测,其中元组的第一个元素是标签,第二个元素是置信度分数。
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
prediction=[("label_1", 0.75), ("label_2", 0.25)],
)
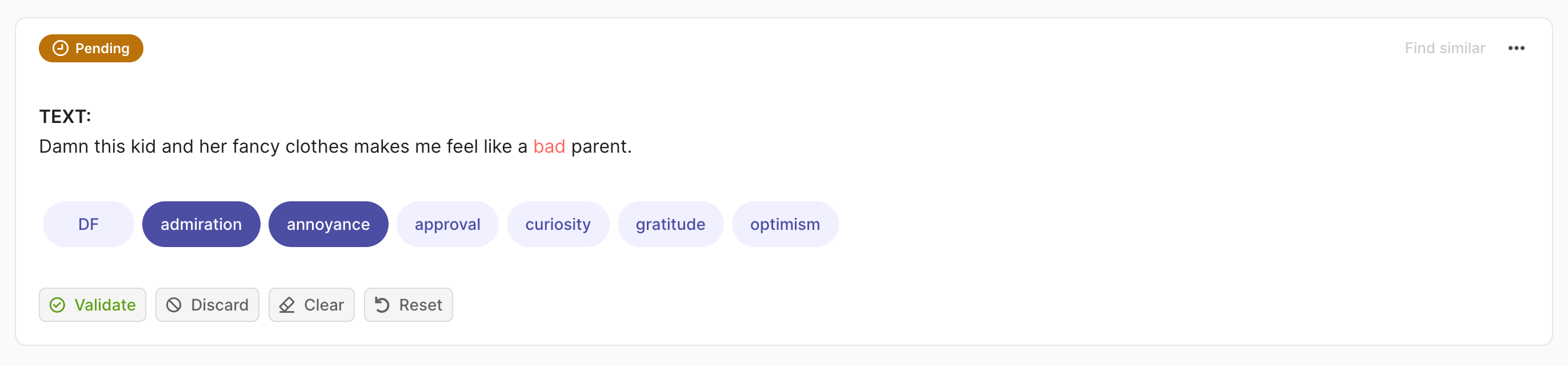
在这种情况下,我们期望一个 List[Tuple[str, float]] 作为预测,其中元组的第二个元素是预测的置信度分数。在多标签的情况下,记录的 multi_label 属性应设置为 True。
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
prediction=[("label_1", 0.75), ("label_2", 0.75)],
multi_label=True
)
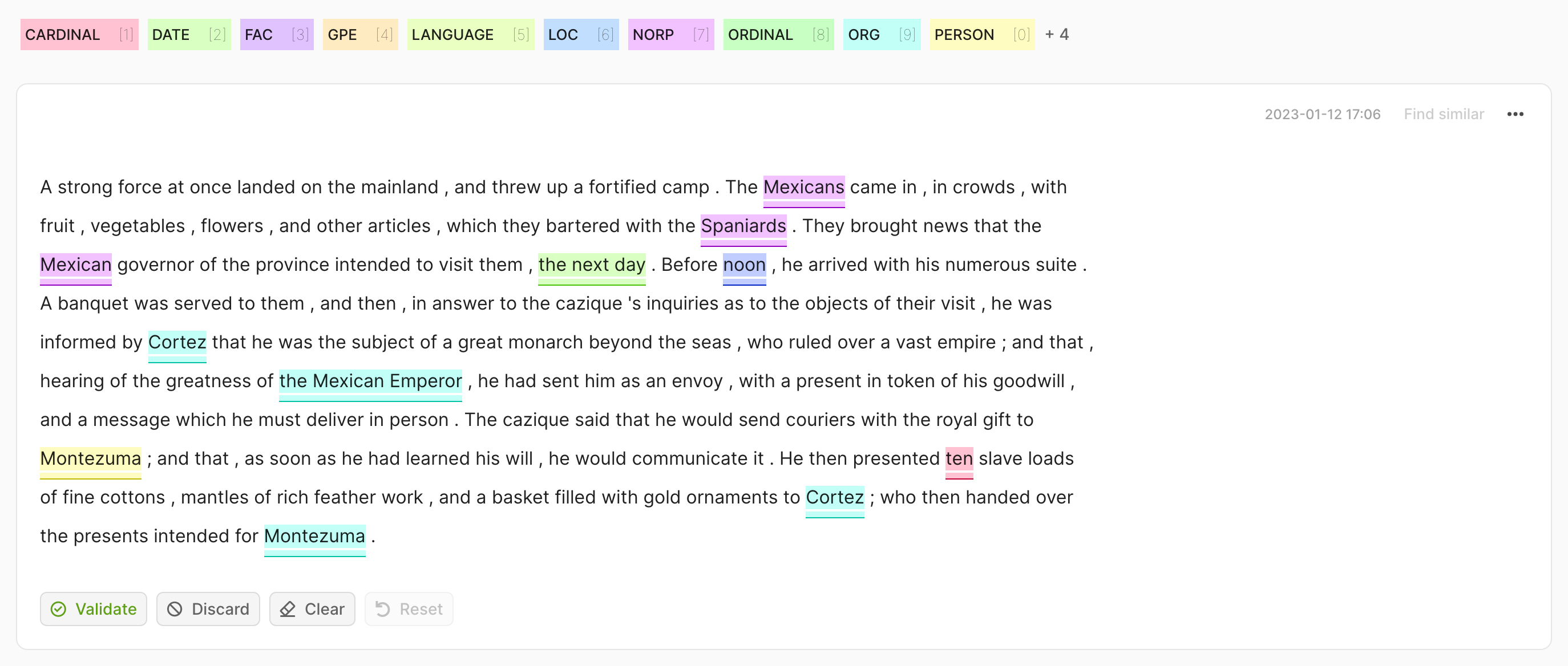
在这种情况下,我们期望一个 List[Tuple[str, int, int, float]] 作为预测,其中元组的第二个和第三个元素是文本中 token 的开始和结束索引。
import argilla as rg
rec = rg.TokenClassificationRecord(
text=...,
tokens=...,
prediction=[("label_1", 0, 7, 0.75), ("label_2", 26, 33, 0.8)],
)
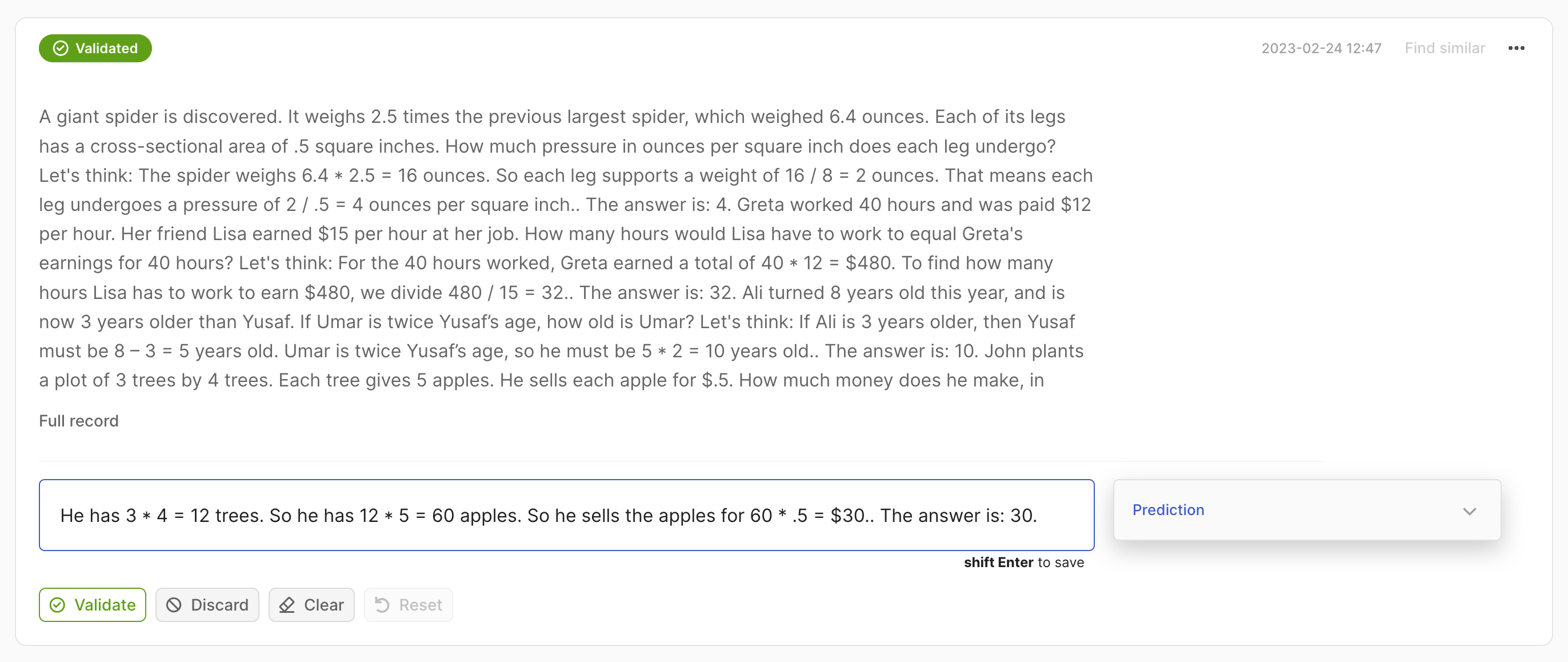
在这种情况下,我们期望一个 List[str] 作为预测。
import argilla as rg
rec = rg.Text2TextRecord(
text=...,
prediction=["He has 3*4 trees. So he has 12*5=60 apples."],
)
添加 responses#
如果您的数据集包含一些注释,您可以在创建记录时将其添加到记录中。确保回复遵循与 Argilla 输出相同的格式,并满足模式要求。
在这种情况下,我们期望一个 str 作为注释。
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
annotation="label_1",
)
在这种情况下,我们期望一个 List[str] 作为注释。在多标签的情况下,记录的 multi_label 属性应设置为 True。
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
annotation=["label_1", "label_2"],
multi_label=True
)
在这种情况下,我们期望一个 List[Tuple[str, int, int]] 作为注释,其中元组的第二个和第三个元素是文本中 token 的开始和结束索引。
import argilla as rg
rec = rg.TokenClassificationRecord(
text=...,
tokens=...,
annotation=[("label_1", 0, 7), ("label_2", 26, 33)],
)
在这种情况下,我们期望一个 str 作为注释。
import argilla as rg
rec = rg.Text2TextRecord(
text=...,
annotation="He has 3*4 trees. So he has 12*5=60 apples.",
)