🔎 过滤和查询数据集#
反馈数据集#
注意
本节涵盖的数据集类是 FeedbackDataset。这个完全可配置的数据集将取代 Argilla 2.0 中的 DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。不确定使用哪个数据集?请查看我们关于 选择数据集 的章节。
过滤器#
从 Argilla 1.15.0 开始,filter_by 方法已包含在推送到 Argilla 的 FeedbackDataset 中,它允许你根据记录注释的 response_status 过滤数据集中的记录。因此,为了能够使用 filter_by 方法,你需要确保你在 Argilla 中使用 FeedbackDataset。
警告
filter_by 方法返回一个新的实例,该实例是一个 FeedbackDataset,其中包含过滤后的记录并与 Argilla 同步,这意味着你将只能访问符合应用过滤器的记录。因此,调用 filter_by 将返回一个包含记录子集的 FeedbackDataset,但记录不会被修改,除非在记录级别专门应用更新或删除。因此,不允许以下方法:delete、delete_records、add_records、records.add 和 records.delete;虽然你仍然可以执行记录级别的操作,例如 update 或 delete。
按 fields 内容#
在 UI 中,你可以使用记录卡顶部的左上角搜索栏,根据字段中的内容过滤记录。例如,你可以通过在搜索栏中简单地输入“John Wick”来阅读或注释所有提及 John Wick 的记录。如果你的记录有多个字段,你将能够选择一个特定字段进行搜索,或者如果你想在所有字段中搜索,则选择“全部”。匹配项以 珊瑚色 显示。
按元数据属性#
在 UI 中,你将找到一个元数据过滤器,可让你轻松设置基于为你的数据集定义的元数据属性的过滤器组合。
注意
请注意,如果将元数据属性设置为 visible_for_annotators=False,则此元数据属性仅在具有 admin 或 owner 角色的用户的元数据过滤器中显示。
在 Python SDK 中,你还可以使用为你的数据集定义的元数据属性的一个或多个元数据过滤器来过滤记录。根据你要过滤的元数据类型,你需要选择以下其中之一:IntegerMetadataFilter、FloatMetadataFilter 或 TermsMetadataFilter。
以下是你需要为过滤器定义的参数
name:你要按其过滤的元数据属性的名称。ge:在IntegerMetadataFilter或FloatMetadataFilter中,匹配大于或等于提供的值的值。应至少提供ge或le之一。le:在IntegerMetadataFilter或FloatMetadataFilter中,匹配小于或等于提供的值的值。应至少提供ge或le之一。values:在TermsMetadataFilter中,返回至少具有提供的其中一个值的记录。
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my-dataset", workspace="my-workspace")
filtered_records = dataset.filter_by(
metadata_filters=[
rg.IntegerMetadataFilter(
name="tokens-length",
ge=900, # at least one of ge or le should be provided
le=1000
),
rg.TermsMetadataFilter(
name="task",
values=["summarization", "information-extraction"]
)
]
)
按回复#
在 UI 过滤器中,你可以根据 当前用户 给出的回复值过滤记录。
注意
这适用于以下类型问题的回复:LabelQuestion、MultiLabelQuestion 和 RatingQuestion。
按建议#
在 Argilla UI 中,你可以根据建议过滤记录。当这些建议可用时,可以按建议分数、值和代理进行过滤。
注意
这适用于以下类型问题的建议:LabelQuestion、MultiLabelQuestion 和 RatingQuestion。
按状态#
在 UI 中,你可以找到一个状态选择器,它允许你根据 当前用户 给出的回复状态选择记录队列。在这里,你可以选择查看具有 Pending、Discarded 或 Submitted 回复的记录。
在 Python SDK 中,filter_by 方法允许你根据 所有用户 给出的回复的 response_status 过滤数据集中的记录。注释的 response_status 可以是以下之一
pending:具有此状态的记录没有回复。在 UI 中,它们将显示在Pending队列下。draft:具有此状态的记录具有已保存为草稿但尚未提交或丢弃的回复。在 UI 中,它们将显示在Draft队列下。discarded:具有此状态的记录可能具有也可能没有回复,但已被注释者丢弃。在 UI 中,它们将显示在Discarded队列下。submitted:具有此状态的记录具有注释者已提交的回复。在 UI 中,它们将显示在Submitted队列下。
注意
从 Argilla 1.14.0 开始,调用 from_argilla 将从 Argilla 中拉取 FeedbackDataset,但该实例将是远程的,这意味着记录的添加、更新和删除将在进行时立即推送到 Argilla。这与以前版本的 Argilla 不同,在以前的版本中,你必须再次调用 push_to_argilla 才能将更改推送到 Argilla。
你可以按单个状态或状态列表过滤记录。
例如,要按状态“submitted”过滤记录,你可以执行以下操作
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my-dataset", workspace="my-workspace")
filtered_dataset = dataset.filter_by(response_status="submitted")
要按状态列表过滤记录,你可以执行以下操作
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my-dataset", workspace="my-workspace")
filtered_dataset = dataset.filter_by(response_status=["submitted", "draft"])
排序#
你还可以根据一个或多个属性对记录进行排序,包括插入和上次更新时间、建议分数、评分问题的回复和建议值以及元数据属性。在 UI 中,你可以使用 Sort 菜单轻松完成此操作。
在 Python SDK 中,你可以使用 sort_by 方法使用以下参数进行排序
field:这指的是将用于排序的信息。这可以是记录创建的时间 (created_at)、上次更新的时间 (updated_at) 或为你的数据集配置的任何元数据属性 (metadata.my-metadata-name)。order:顺序应该是升序 (asc) 还是降序 (des)。
sorted_records = remote.sort_by(
[
SortBy(field="metadata.my-metadata", order="asc"),
SortBy(field="updated_at", order="des"),
]
)
提示
你还可以组合过滤器和排序:dataset.filter_by(...).sort_by(...)
语义搜索#
在反馈数据集中,你还可以根据记录与其他记录的相似性来检索记录。为此,请确保已将 vector_settings 添加到你的 数据集配置,并且你的 记录包含向量。
在 UI 中,转到你想用于语义搜索的记录,然后单击记录卡右上角的 查找相似。如果存在多个向量,系统将要求你选择要使用的向量。你还可以选择是要最相似还是最不相似的记录,以及你想查看的结果数量。
你可以随时展开或折叠用作参考的搜索记录。如果要撤消搜索,只需单击参考记录旁边的叉号即可。
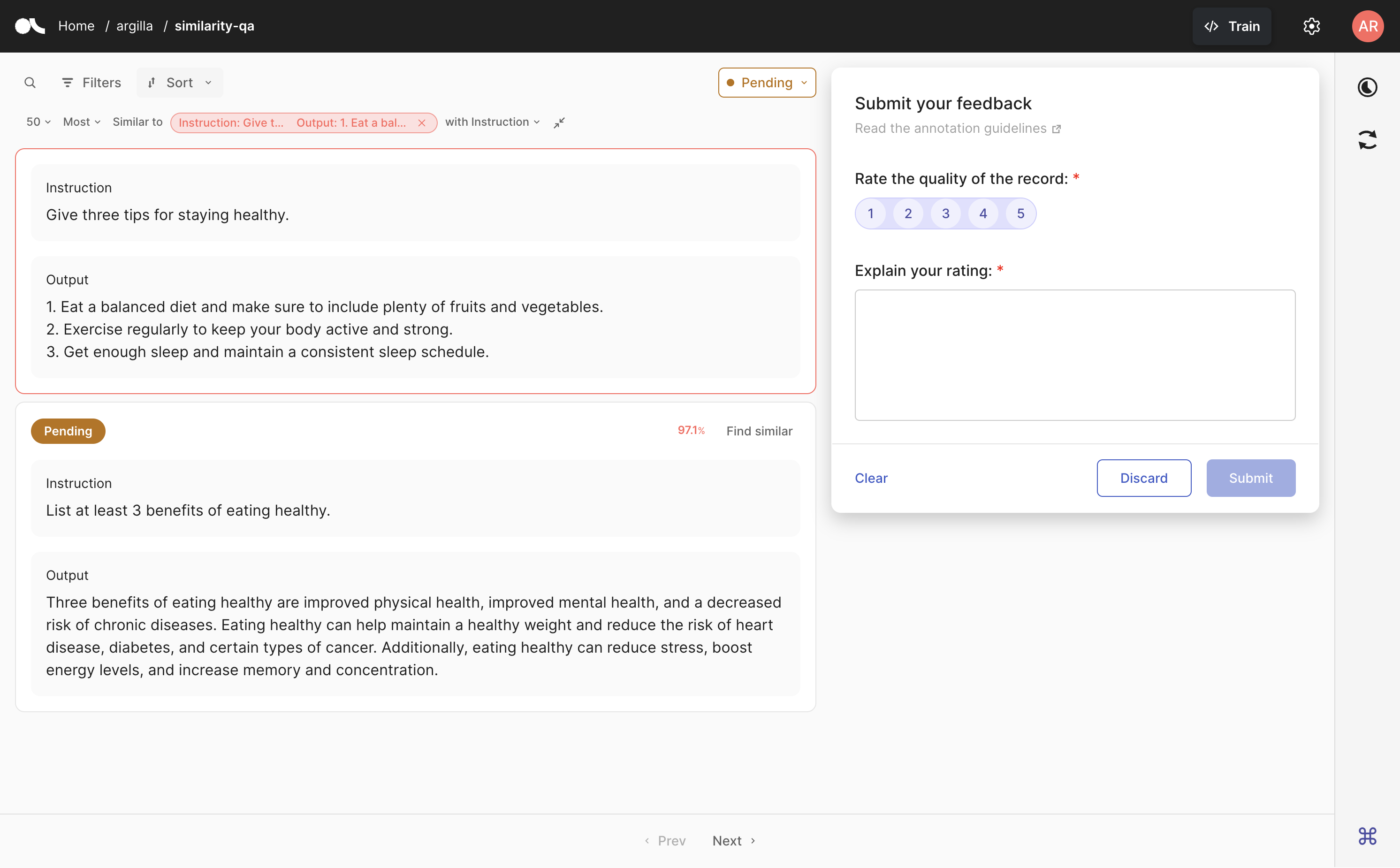
在 Python SDK 中,你还可以使用 find_similar_records 方法获取语义上接近给定嵌入的反馈记录列表。以下是此函数的参数
vector_name:要在搜索中使用的向量的name。value:用于相似性搜索的向量,格式为List[float]。必须包含value或record。record:要用作搜索一部分的FeedbackRecord。必须包含value或record。max_results(可选):此搜索的最大结果数。默认值为50。
这将返回一个元组列表,其中包含记录及其相似性评分(介于 0 和 1 之间)。
ds = rg.FeedbackDataset.from_argilla("my_dataset", workspace="my_workspace")
# using text embeddings
similar_records = ds.find_similar_records(
vector_name="my_vector",
value=embedder_model.embeddings("My text is here")
# value=embedder_model.embeddings("My text is here").tolist() # for numpy arrays
)
# using another record
similar_records = ds.find_similar_records(
vector_name="my_vector",
record=ds.records[0],
max_results=5
)
# work with the resulting tuples
for record, score in similar_records:
...
你还可以像这样组合过滤器和语义搜索
similar_records = (dataset
.filter_by(metadata=[rg.TermsMetadataFilter(values=["Positive"])])
.find_similar_records(vector_name="vector", value=model.encode("Another text").tolist())
)
其他数据集#
注意
本节中涵盖的记录类对应于三个数据集:DatasetForTextClassification、DatasetForTokenClassification 和 DatasetForText2Text。这些将在 Argilla 2.0 中弃用,并由完全可配置的 FeedbackDataset 类替换。不确定使用哪个数据集?请查看我们关于 选择数据集 的章节。
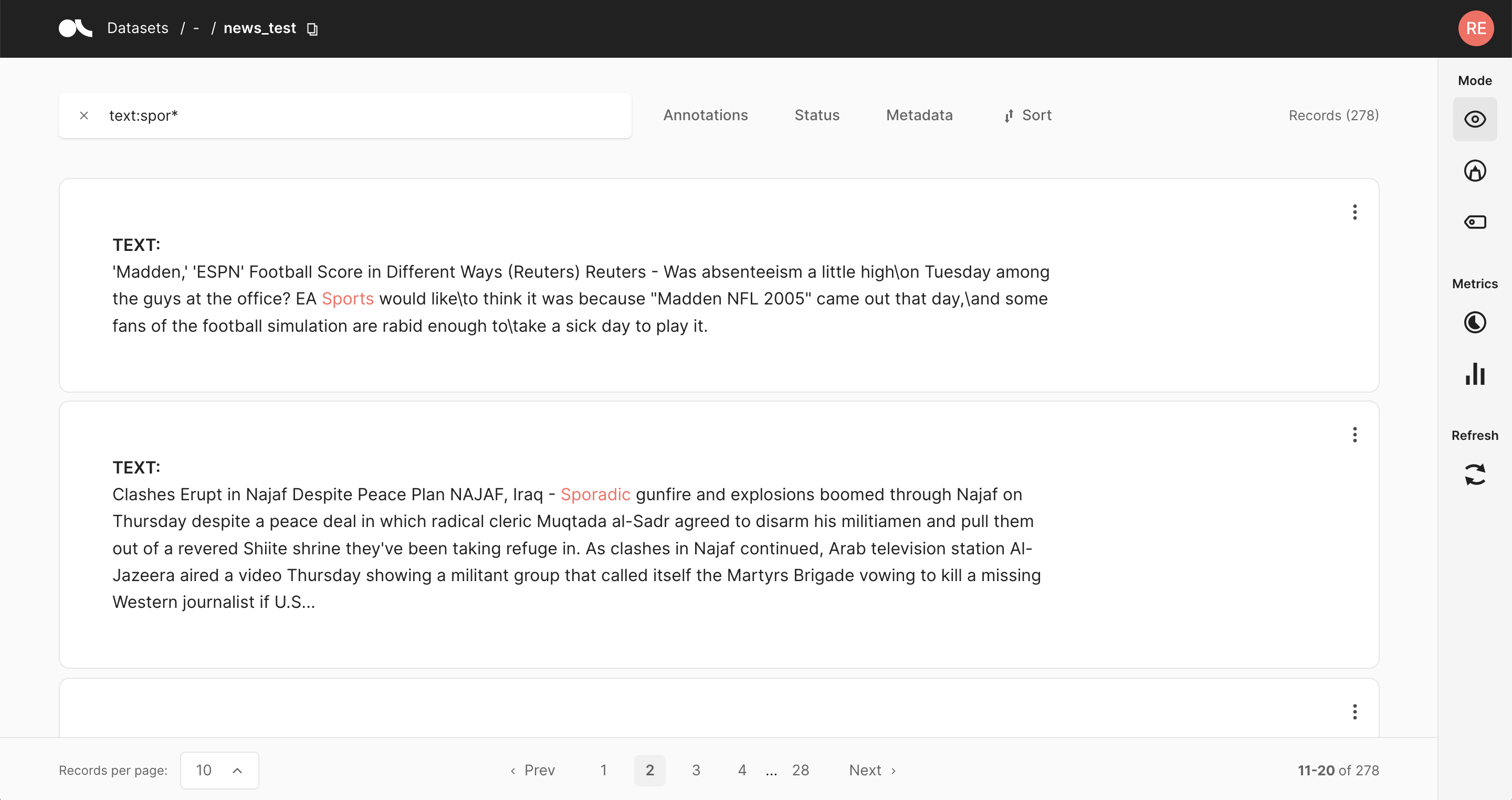
Argilla 中的搜索由 Elasticsearch 强大的 查询字符串语法 驱动。它允许你执行单词和短语的简单模糊搜索,或充分利用 Argilla 数据模型的复杂查询。
相同的查询可以在 Argilla Web 应用程序的搜索栏中使用,也可以在 Python 客户端中用作可选参数。
import argilla as rg
rg.load("my_dataset", query="text.exact:example")
此外,我们提供了语法的简要摘要,但要获得完整的概述,请深入研究下面的文档。
text 字段使用 Elasticsearch 的 标准分析器,该分析器忽略大小写并删除大多数标点符号;text.exact 字段使用 空格分析器,该分析器区分大小写,并考虑标点符号;
text:dog.或text:fox:匹配两个记录。text.exact:dog或text.exact:FOX:不匹配任何记录。text.exact:dog.或text.exact:fox:仅匹配第一个记录。text.exact:DOG或text.exact:FOX\!:仅匹配第二个记录。
类似的推理适用于 inputs,用于查找 subject 键包含单词 news 的记录,你将搜索
inputs.subject:news
同样,与 text 字段一样,你也可以使用空格分析器通过指定 exact 字段来执行更精细的搜索。
inputs.subject.exact:NEWS
假设你提供了记录所属的拆分作为元数据,即 metadata={"split": "train"} 或 metadata={"split": "test"}。然后,你可以通过在查询中指定相应的字段来仅搜索你的训练数据
metadata.split:train
就像元数据一样,你也可以在查询中使用过滤器字段。以下是一些在查询字符串中模拟过滤器的示例
status:Validatedannotated_as:HAMpredicted_by:Model A
可以为日期、数字或字符串字段指定范围。包含范围用方括号指定,排除范围用大括号指定
score:[0.5 TO 0.6]score:{0.9 TO *}event_timestamp:[1984-01-01T01:01:01.000000 TO *]last_updated:{* TO 1984-01-01T01:01:01.000000}
你可以使用熟悉的布尔运算符 AND、OR 和 NOT 在搜索中组合任意数量的术语和字段。以下示例展示了这些运算符的强大功能
text:(quick AND fox):返回包含单词 quick 和 fox 的记录。AND运算符是默认运算符,因此text:(quick fox)是等效的。text:(quick OR brown):返回包含单词 quick 或 brown 的记录。text:(quick AND fox AND NOT news):返回包含单词 quick 和 fox 但不包含 news 的记录。metadata.split:train AND text:fox:返回包含单词 fox 并且具有元数据 “split: train” 的记录。NOT _exists_:metadata.split:返回没有元数据 split 的记录。
正则表达式模式可以通过将它们包装在正斜杠“/”中嵌入到查询字符串中
text:/joh?n(ath[oa]n)/:匹配 jonathon、jonathan、johnathon 和 johnathan。
受支持的正则表达式语法在官方 Elasticsearch 文档 中进行了解释。
你可以使用 模糊 运算符搜索与搜索词相似但不完全相同的术语。这对于涵盖人为拼写错误很有用
text:quikc~:匹配 quick 和 quikc。
通配符搜索可以在单个搜索词上运行,使用 ? 替换单个字符,使用 * 替换零个或多个字符
text:(qu?ck bro*)text.exact:"Lazy Dog*":例如,匹配 “Lazy Dog”、“Lazy Dog.” 或 “Lazy Dogs”。inputs.\*:news:在所有输入字段中搜索单词 news。
搜索字段#
使用 Elasticsearch 进行搜索时,一个重要的概念是 字段 概念。Argilla 中的每个搜索词都定向到记录底层数据模型的特定字段。例如,在搜索栏中写入 text:fox 将在字段 text 中搜索包含单词 fox 的记录。
如果你在查询字符串中未提供任何字段,则默认情况下 Argilla 将在 text 字段中搜索。有关可用字段及其内容的完整列表,请查看下面的字段词汇表。
注意
在版本 >=0.16.0 中,未在查询字符串中指定任何字段时的默认行为已更改。在此版本之前,Argilla 在已弃用的 word 和 word.extended 字段的混合中搜索,这些字段允许搜索诸如 ! 和 . 之类的特殊字符。如果你现在要搜索特殊字符,则必须指定 text.exact 字段。例如,如果你想搜索末尾带有感叹号的单词,则查询如下:text.exact:*\!
如果在版本更新后未检索到任何结果,则应在旧数据集的搜索查询中使用 words 和 words.extended 字段,而不是 text 和 text.exact 字段。
text 和 text.exact#
(可以说)最重要的字段是 text 和 text.exact 字段。它们都包含记录的文本,但以两种不同的形式
让我们看一些例子。假设我们有 2 条记录,文本如下
The quick brown fox jumped over the lazy dog.
THE LAZY DOG HATED THE QUICK BROWN FOX!
现在考虑以下查询
text:dog.或text:fox:匹配两个记录。text.exact:dog或text.exact:FOX:不匹配任何记录。text.exact:dog.或text.exact:fox:仅匹配第一个记录。text.exact:DOG或text.exact:FOX\!:仅匹配第二个记录。
你可以看到如何使用 text.exact 字段以更精细的方式进行搜索。
TextClassificationRecord 的 inputs#
对于 文本分类记录,你可以在执行搜索时利用多个 inputs。例如,如果我们上传了 inputs={"subject": ..., "body": ...} 的记录,你可以通过在查询中指定 inputs.subject 或 inputs.body 字段来将搜索定向到这些输入之一。因此,要查找 subject 包含单词 news 的记录,你将搜索
inputs.subject:news
同样,与 text 字段一样,你也可以使用空格分析器通过指定 exact 字段来执行更精细的搜索
inputs.subject.exact:NEWS
单词和短语#
除了单个单词外,你还可以通过用双引号包围多个单词来搜索 短语。这将搜索短语中的所有单词,并按相同的顺序排列。
如果我们采用上面的两个示例,则以下查询将仅返回第二个示例
text:"lazy dog hated"
元数据字段#
在执行搜索时,你还可以使用记录的元数据。假设你提供了记录所属的拆分作为元数据,即 metadata={"split": "train"} 或 metadata={"split": "test"}。然后,你可以通过在查询中指定相应的字段来仅搜索你的训练数据
metadata.split:train
元数据被索引为关键字。这意味着你无法在其中搜索单个单词,并且会考虑大小写和标点符号。但是,你可以使用通配符。
警告
默认情况下,元数据字段的最大长度为 128 个字符,字段限制为 50。如果希望更改这些值,可以在服务器环境变量中设置你自己的 ARGILLA_METADATA_FIELD_LENGTH。了解更多 此处 默认情况下,元数据字段的最大长度为 128 个字符,字段限制为 50。如果希望更改这些值,可以在服务器环境变量中设置你自己的 ARGILLA_METADATA_FIELD_LENGTH。了解更多 此处
不可搜索的元数据字段#
如果你只想将元数据与记录一起存储,而不将其用于搜索,则可以通过使用前导下划线定义元数据字段来实现此目的。例如,如果你使用 metadata._my_hidden_field,则该字段将在记录级别可访问,但不会在搜索中使用。
提示
你可以使用此字段通过指向图像的 URL 将图像添加到记录中,如下所示:metadata = {"_image_url": "https://..."}
请注意,URL 不能超过元数据长度限制。
向量字段#
也可以查询向量字段的存在。假设你只想包含具有 vectors={"vector_1": vector_1} 的记录。然后你可以定义查询 vectors.vector_1: *。
过滤器作为查询字符串#
就像元数据一样,你也可以在查询中使用过滤器字段。以下是一些在查询字符串中模拟过滤器的示例
status:Validatedannotated_as:HAMpredicted_by:Model A
字段值被视为关键词,也就是说您无法在其中搜索单个词语,并且大小写和标点符号都会被考虑在内。但是,您可以使用通配符。
组合词条和字段#
你可以使用熟悉的布尔运算符 AND、OR 和 NOT 在搜索中组合任意数量的术语和字段。以下示例展示了这些运算符的强大功能
text:(quick AND fox):返回包含单词 quick 和 fox 的记录。AND运算符是默认运算符,因此text:(quick fox)是等效的。text:(quick OR brown):返回包含单词 quick 或 brown 的记录。text:(quick AND fox AND NOT news):返回包含单词 quick 和 fox 但不包含 news 的记录。metadata.split:train AND text:fox:返回包含单词 fox 并且元数据为 “split: train” 的记录。NOT _exists_:metadata.split:返回没有元数据 split 的记录。
查询字符串功能#
查询字符串语法具有许多强大的功能,您可以使用它们来创建复杂的搜索。以下只是您可以查阅官方 Elasticsearch 文档 的众多功能中精选的子集。
通配符#
通配符搜索可以在单个搜索词上运行,使用 ? 替换单个字符,使用 * 替换零个或多个字符
text:(qu?ck bro*)text.exact:"Lazy Dog*":例如,匹配 “Lazy Dog”、“Lazy Dog.” 或 “Lazy Dogs”。inputs.\*:news:在所有输入字段中搜索单词 news。
正则表达式#
正则表达式模式可以通过将它们包装在正斜杠“/”中嵌入到查询字符串中
text:/joh?n(ath[oa]n)/:匹配 jonathon、jonathan、johnathon 和 johnathan。
受支持的正则表达式语法在官方 Elasticsearch 文档 中进行了解释。
模糊性#
你可以使用 模糊 运算符搜索与搜索词相似但不完全相同的术语。这对于涵盖人为拼写错误很有用
text:quikc~:匹配 quick 和 quikc。
范围#
可以为日期、数字或字符串字段指定范围。包含范围用方括号指定,排除范围用花括号指定
score:[0.5 TO 0.6]score:{0.9 TO *}
日期时间范围#
日期时间范围是一种特殊的范围查询,可以为 event_timestamp 和 last_updated 字段定义。格式类似于普通范围查询,但它们需要 iso 格式的日期时间,可以通过 datetime.now().isoformat() 获得,结果为 1984-01-01T01:01:01.000000。请注意,* 可以互换用于表示时间的结束或时间的开始。
event_timestamp:[1984-01-01T01:01:01.000000 TO *]last_updated:{* TO 1984-01-01T01:01:01.000000}
转义特殊字符#
查询字符串语法有一些保留字符,如果您想搜索它们,则需要转义。保留字符包括:+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ / 例如,要搜索 “(1+1)=2”,您需要写
text:\(1\+1\)\=2
字段词汇表#
这是一个包含可用字段的表格,您可以在查询字符串中使用这些字段
字段名称 |
描述 |
TextClass. |
TokenClass. |
TextGen. |
|---|---|---|---|---|
annotated_as |
注释 |
✔ |
✔ |
✔ |
annotated_by |
注释代理 |
✔ |
✔ |
✔ |
event_timestamp |
时间戳 |
✔ |
✔ |
✔ |
id |
id |
✔ |
✔ |
✔ |
inputs.* |
输入 |
✔ |
||
metadata.* |
元数据 |
✔ |
✔ |
✔ |
vectors.* |
向量 |
✔ |
✔ |
✔ |
last_updated |
上次更新日期 |
✔ |
✔ |
✔ |
predicted_as |
预测 |
✔ |
✔ |
✔ |
predicted_by |
预测代理 |
✔ |
✔ |
✔ |
score |
预测得分 |
✔ |
||
status |
status |
✔ |
✔ |
✔ |
text |
文本,标准分析器 |
✔ |
✔ |
✔ |
text.exact |
文本,空格分析器 |
✔ |
✔ |
✔ |
tokens |
tokens |
✔ |
||
- |
- |
- |
- |
- |
metrics.text_lengt |
输入文本长度 |
✔ |
✔ |
✔ |
metrics.tokens.idx |
记录中的 Token 索引 |
✔ |
||
metrics.tokens.value |
Token 的文本 |
✔ |
||
metrics.tokens.char_start |
Token 的起始字符索引 |
✔ |
||
metrics.tokens.char_end |
Token 的结束字符索引 |
✔ |
||
metrics.annotated.mentions.value |
提及的文本(注释) |
✔ |
||
metrics.annotated.mentions.label |
提及的标签(注释) |
✔ |
||
metrics.annotated.mentions.score |
提及的得分(注释) |
✔ |
||
metrics.annotated.mentions.capitalness |
提及的首字母大写(注释) |
✔ |
||
metrics.annotated.mentions.density |
局部提及密度(注释) |
✔ |
||
metrics.annotated.mentions.tokens_length |
提及的 token 长度(注释) |
✔ |
||
metrics.annotated.mentions.chars_length |
提及的字符长度(注释) |
✔ |
||
metrics.annotated.tags.value |
Token 的文本(注释) |
✔ |
||
metrics.annotated.tags.tag |
IOB 标签(注释) |
✔ |
||
metrics.predicted.mentions.value |
提及的文本(预测) |
✔ |
||
metrics.predicted.mentions.label |
提及的标签(预测) |
✔ |
||
metrics.predicted.mentions.score |
提及的得分(预测) |
✔ |
||
metrics.predicted.mentions.capitalness |
提及的首字母大写(预测) |
✔ |
||
metrics.predicted.mentions.density |
局部提及密度(预测) |
✔ |
||
metrics.predicted.mentions.tokens_length |
提及的 token 长度(预测) |
✔ |
||
metrics.predicted.mentions.chars_length |
提及的字符长度(预测) |
✔ |
||
metrics.predicted.tags.value |
Token 的文本(预测) |
✔ |
||
metrics.predicted.tags.tag |
IOB 标签(预测) |
✔ |