unstructured:面向 LLM 的大规模文档处理#
在本 notebook 中,我们将向您展示如何使用出色的库 unstructured 以及 argilla 和 HuggingFace transformers 来训练自定义摘要模型。在本例中,我们将构建一个摘要模型,目标是摘要 战争研究所 关于乌克兰战争的每日报告。您可以在此处查看其中一份报告的示例,以下是截图。
致谢 🎉
此 notebook 由来自 Unstructured 的 Matt Robinson 开发。Unstructured 是收集 Argilla 数据集的非结构化格式(如 HTML 文档和 PDF)的推荐库。如果您还不了解 Unstructured,请访问 unstructured GitHub 仓库,如果您喜欢他们正在构建的内容,请留下一个 star。
简介#
结合 unstructured、argilla 和 transformers 库,我们能够在几个小时内完成一个以前可能需要一周或更长时间的数据科学项目!
第 1 节:使用 unstructured 进行数据收集和暂存
第 2 节:使用 Argilla 进行标签验证
第 3 节:使用 transformers 进行模型训练

运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部 notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,您只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地机器上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能使用外部 notebook 服务。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种运行方式
使用本页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 notebook 并在本地机器或您选择的 Jupyter Notebook 工具上运行它。
[ ]:
%pip install "unstructured==0.4.4" -qqq
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,您需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您正在运行私有 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含我们需要的导入
[ ]:
import calendar
from datetime import datetime
import re
import time
import requests
from transformers import pipeline
import tqdm
from unstructured.partition.html import partition_html
from unstructured.documents.elements import NarrativeText, ListItem
from unstructured.staging.argilla import stage_for_argilla
import nltk
nltk.download('averaged_perceptron_tagger')
第 1 节:使用 unstructured 进行数据收集和暂存#
首先,我们将从 ISW 网站上拉取我们的文档。我们将使用内置的 Python datetime 和 calendar 库来迭代我们想要拉取的报告的日期,并找到相关的 URL。
[4]:
ISW_BASE_URL = "https://www.understandingwar.org/backgrounder/russian-offensive-campaign-assessment"
def datetime_to_url(dt):
month = dt.strftime("%B").lower()
return f"{ISW_BASE_URL}-{month}-{dt.day}"
[5]:
urls = []
year = 2022
for month in range(3, 13):
_, last_day = calendar.monthrange(year, month)
for day in range(1, last_day + 1):
dt = datetime(year, month, day)
urls.append(datetime_to_url(dt))
一旦我们有了 URL,我们就可以使用 requests 库从 Web 上拉取每个报告的 HTML 文档。通常,您需要使用像 lxml 或 beautifulsoup 这样的库编写自定义 HTML 解析代码,以便从网页中提取叙述性文本用于模型训练。使用 unstructured 库,您只需调用 partition_html 函数即可提取感兴趣的内容。
[6]:
def url_to_elements(url):
r = requests.get(url)
if r.status_code != 200:
return None
elements = partition_html(text=r.text)
return elements
在对文档进行分区后,我们将从 ISW 报告中提取 Key Takeaways 部分,如下面的屏幕截图所示。Key Takeaways 部分将作为我们摘要模型的目标文本。虽然编写 HTML 解析代码来查找此内容会很耗时,但使用 unstructured 库很容易。由于 partition_html 函数将文档的元素分解为不同的类别,如 Title、NarrativeText 和 ListItem,我们所需要做的就是找到 Key Takeaways 标题,然后抓取 ListItem 元素,直到列表结束。此逻辑在 get_key_takeaways 函数中实现。

[12]:
def _find_key_takeaways_idx(elements):
for idx, element in enumerate(elements):
if element.text == "Key Takeaways":
return idx
def get_key_takeaways(elements):
key_takeaways_idx = _find_key_takeaways_idx(elements)
if not key_takeaways_idx:
return None
takeaways = []
for element in elements[key_takeaways_idx + 1:]:
if not isinstance(element, ListItem):
break
takeaways.append(element)
takeaway_text = " ".join([el.text for el in takeaways])
return NarrativeText(text=takeaway_text)
[13]:
elements = url_to_elements(urls[200])
[14]:
print(get_key_takeaways(elements))
Russian forces continue to prioritize strategically meaningless offensive operations around Donetsk City and Bakhmut over defending against continued Ukrainian counter-offensive operations in Kharkiv Oblast. Ukrainian forces liberated a settlement southwest of Lyman and are likely continuing to expand their positions in the area. Ukrainian forces continued to conduct an interdiction campaign in Kherson Oblast. Russian forces continued to conduct unsuccessful assaults around Bakhmut and Avdiivka. Ukrainian sources reported extensive partisan attacks on Russian military assets and logistics in southern Zaporizhia Oblast. Russian officials continued to undertake crypto-mobilization measures to generate forces for war Russian war efforts. Russian authorities are working to place 125 “orphan” Ukrainian children from occupied Donetsk Oblast with Russian families.
接下来,我们将从文档中抓取叙述性文本作为我们模型的输入。同样,使用 unstructured 也很容易,因为 partition_html 函数已经拆分了文本。我们将只抓取所有超过最小长度阈值的 NarrativeText 元素。在其中,我们还将清除文档中引用的原始文本,这些文本不是自然语言,可能会影响我们的摘要模型的质量。
[15]:
def get_narrative(elements):
narrative_text = ""
for element in elements:
if isinstance(element, NarrativeText) and len(element.text) > 500:
# NOTE: Removes citations like [3] from the text
element_text = re.sub("\[\d{1,3}\]", "", element.text)
narrative_text += f"\n\n{element_text}"
return NarrativeText(text=narrative_text.strip())
[28]:
# Show a sample of narrative text
print(get_narrative(elements).text[0:2000])
Russian forces continue to conduct meaningless offensive operations around Donetsk City and Bakhmut instead of focusing on defending against Ukrainian counteroffensives that continue to advance. Russian troops continue to attack Bakhmut and various villages near Donetsk City of emotional significance to pro-war residents of the Donetsk People’s Republic (DNR) but little other importance. The Russians are apparently directing some of the very limited reserves available in Ukraine to these efforts rather than to the vulnerable Russian defensive lines hastily thrown up along the Oskil River in eastern Kharkiv Oblast. The Russians cannot hope to make gains around Bakhmut or Donetsk City on a large enough scale to derail Ukrainian counteroffensives and appear to be continuing an almost robotic effort to gain ground in Donetsk Oblast that seems increasingly divorced from the overall realities of the theater.
Russian failures to rush large-scale reinforcements to eastern Kharkiv and to Luhansk Oblasts leave most of Russian-occupied northeastern Ukraine highly vulnerable to continuing Ukrainian counter-offensives. The Russians may have decided not to defend this area, despite Russian President Vladimir Putin’s repeated declarations that the purpose of the “special military operation” is to “liberate” Donetsk and Luhansk oblasts. Prioritizing the defense of Russian gains in southern Ukraine over holding northeastern Ukraine makes strategic sense since Kherson and Zaporizhia Oblasts are critical terrain for both Russia and Ukraine whereas the sparsely-populated agricultural areas in the northeast are much less so. But the continued Russian offensive operations around Bakhmut and Donetsk City, which are using some of Russia’s very limited effective combat power at the expense of defending against Ukrainian counteroffensives, might indicate that Russian theater decision-making remains questionable.
Ukrainian forces appear to be expanding positions east of the Oskil River and
现在我们已经设置好了一切,让我们收集所有报告!此步骤可能需要一段时间,因此我们在循环中添加了一个睡眠调用,以避免 ISW 的网页不堪重负。
[ ]:
inputs = []
annotations = []
for url in tqdm.tqdm(urls):
elements = url_to_elements(url)
if url is None or not elements:
continue
text = get_narrative(elements)
annotation = get_key_takeaways(elements)
if text and annotation:
inputs.append(text)
annotations.append(annotation.text)
# NOTE: Sleeping to reduce the volume of requests to ISW
time.sleep(1)
第 2 节:使用 argilla 进行标签验证#
现在我们已经收集了数据并使用 unstructured 进行了准备,我们准备好在 argilla 中处理我们的数据标签。首先,我们将使用 unstructured 库中的 stage_for_argilla 暂存块。这将自动将我们的数据集转换为 DatasetForText2Text 对象,然后我们可以将其导入 Argilla。
[31]:
dataset = stage_for_argilla(inputs, "text2text", annotation=annotations)
[32]:
dataset.to_pandas().head()
[32]:
| text | prediction | prediction_agent | annotation | annotation_agent | vectors | id | metadata | status | event_timestamp | metrics | search_keywords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 俄罗斯军队正在完成增援... | None | None | 俄罗斯军队正在为包围创造条件... | None | None | 1a5b66dcbf80159ce2c340b17644d639 | {} | 已验证 | 2023-01-31 11:19:52.784880 | None | None |
| 1 | 俄罗斯军队恢复了在...的进攻行动 | None | None | 俄罗斯军队恢复了针对...的进攻行动 | None | None | 32e2f136256a7003de06c5792a5474fe | {} | 已验证 | 2023-01-31 11:19:52.784941 | None | None |
| 2 | 俄罗斯军方继续其未成功的... | None | None | 俄罗斯军队从...开辟了一条新的进攻线 | None | None | 6e4c94cdc2512ee7b915c303161ada1d | {} | 已验证 | 2023-01-31 11:19:52.784983 | None | None |
| 3 | 俄罗斯军队继续专注于包围... | None | None | 俄罗斯军队已在...迅速推进 | None | None | 5c123326055aa4832014ed9ab07e80f1 | {} | 已验证 | 2023-01-31 11:19:52.785022 | None | None |
| 4 | 俄罗斯军队仍然部署在...的位置 | None | None | 俄罗斯军队没有进行重大进攻行动... | None | None | b6597ad2ca8a352bfc46a04b85b22421 | {} | 已验证 | 2023-01-31 11:19:52.785060 | None | None |
在为 argilla 暂存数据后,我们可以调用 argilla Python 库中的 rg.log 函数将数据上传到 Argilla UI。在运行此步骤之前,请确保 Argilla 服务器在后台运行。将数据记录到 Argilla 后,您的 UI 应如下面的屏幕截图所示。
[ ]:
rg.log(dataset, name="isw-summarization")
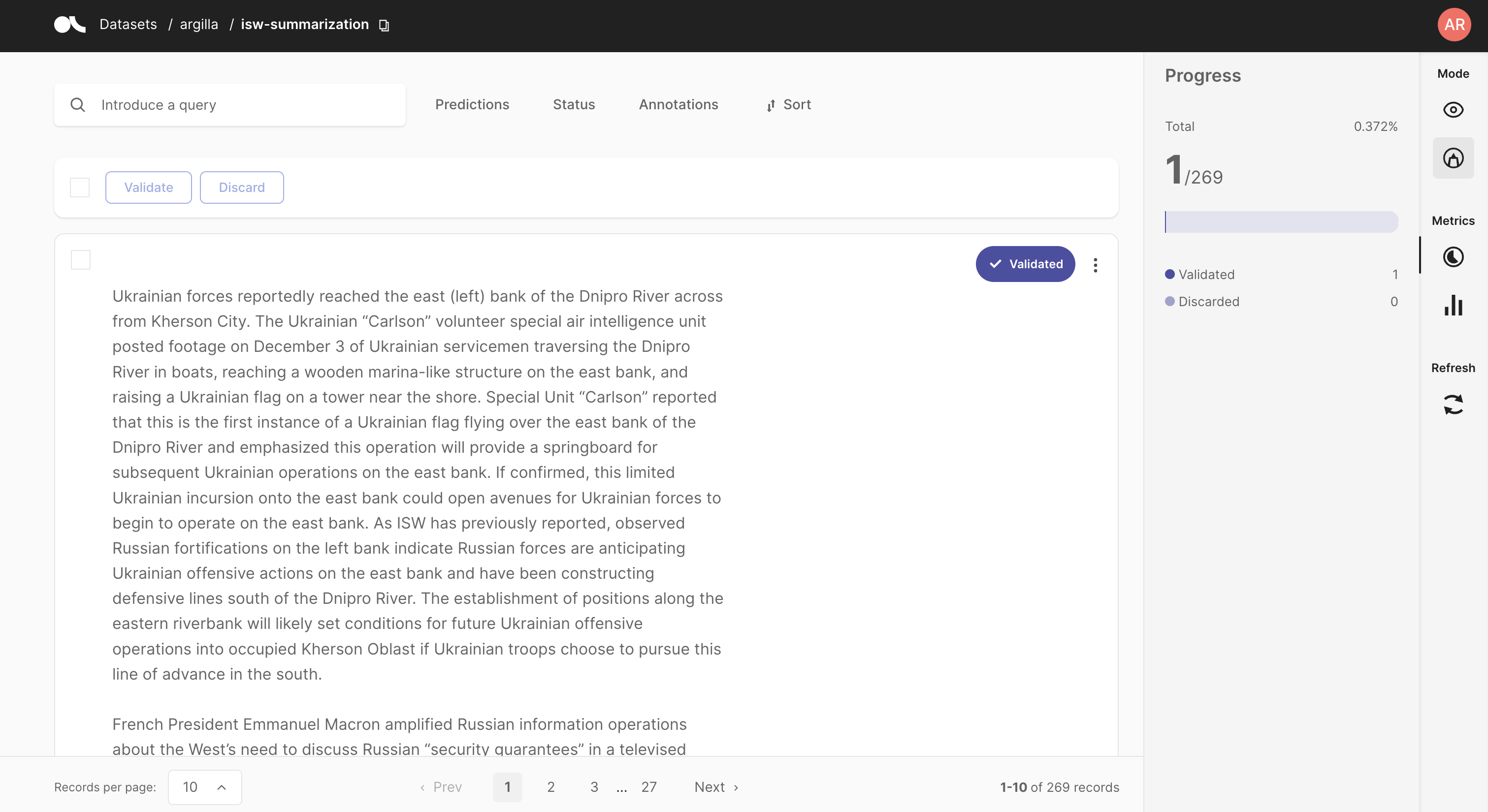
上传数据集后,前往 Argilla UI 并验证和/或调整我们从 ISW 站点拉取的摘要。您还可以查看 Argilla 文档,了解有关 Argilla 提供的所有令人兴奋的工具的更多信息,这些工具可帮助您标注、评估和改进您的训练数据!
第 3 节:使用 transformers 进行模型训练#
在 Argilla 中改进我们的训练数据后,我们准备好使用 transformers 库微调我们的模型。幸运的是,argilla 具有将数据集转换为 dataset.Dataset 的实用程序,这是 transformers Trainer 对象所需的格式。在本例中,我们将训练一个 t5-small 模型,以保持 notebook 的运行时合理。您可以尝试使用更大的模型以获得更高质量的结果。
[18]:
training_data = rg.load("isw-summarization").to_datasets()
[19]:
model_checkpoint = "t5-small"
[ ]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
[21]:
max_input_length = 1024
max_target_length = 128
def preprocess_function(examples):
inputs = [doc for doc in examples["text"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples["annotation"], max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
[ ]:
tokenized_datasets = training_data.map(preprocess_function, batched=True)
[23]:
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
[24]:
batch_size = 16
model_name = model_checkpoint.split("/")[-1]
args = Seq2SeqTrainingArguments(
"t5-small-isw-summaries",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=False,
push_to_hub=False,
)
[25]:
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
[26]:
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets,
eval_dataset=tokenized_datasets,
data_collator=data_collator,
tokenizer=tokenizer,
)
[ ]:
trainer.train()
[ ]:
trainer.save_model("t5-small-isw-summaries")
[ ]:
summarization_model = pipeline(
task="summarization",
model="./t5-small-isw-summaries",
)
现在我们的模型已经训练完成,我们可以将其保存在本地,并使用我们的 unstructured 辅助函数来抓取未来的报告以进行推理!
[30]:
elements = url_to_elements(urls[200])
narrative_text = get_narrative(elements)
results = summarization_model(str(narrative_text), max_length=100)
print(results[0]["summary_text"])
Russian forces continue to attack Bakhmut and various villages near Donetsk City . the Russians are apparently directing some of the very limited reserves available in Ukraine to these efforts rather than to the vulnerable Russian defensive lines hastily thrown up . Russian sources claimed that Russian forces are repelled a Ukrainian ground attack on Pravdyne .