✨ 使用 SetFit 添加零样本文本分类建议#
建议是使您的标注团队的工作更轻松快捷的绝佳方式。这些预选选项将使标注过程更有效率,因为他们只需要更正建议。
在本示例中,我们将演示如何使用 SetFit 实现零样本方法,为数据集获取一些初始建议,该数据集结合了两个文本分类任务,包括 LabelQuestion 和 MultiLabelQuestion。
让我们开始吧!
注意
本教程是一个 Jupyter Notebook。有两种运行方式
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 notebook。不要忘记将运行时类型更改为 GPU,以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 notebook 并在本地计算机或您选择的 Jupyter notebook 工具上运行它。
设置#
对于本教程,您需要运行 Argilla 服务器。如果您还没有服务器,请查看我们的快速入门 或 安装 页面。完成后,完成以下步骤
使用
pip安装 Argilla 客户端和所需的第三方库
[ ]:
!pip install argilla setfit
让我们进行必要的导入
[ ]:
import argilla as rg
from datasets import load_dataset
from setfit import get_templated_dataset
from setfit import SetFitModel, SetFitTrainer
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用
URL和API_KEY初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您运行的是私有 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
启用遥测#
我们从您与我们教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。尽管这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
配置数据集#
在本示例中,我们将加载一个流行的开源数据集,其中包含银行领域的客户请求。
[ ]:
data = load_dataset("PolyAI/banking77", split="test")
我们将使用两个不同的问题配置我们的数据集,以便我们可以同时处理两个文本分类任务。在本例中,我们将加载此数据集的原始标签,以对请求中提及的主题进行多标签分类,并且我们还将设置一个问题,将请求的情感分类为“正面”、“中性”或“负面”。
[ ]:
dataset = rg.FeedbackDataset(
fields = [rg.TextField(name="text")],
questions = [
rg.MultiLabelQuestion(
name="topics",
title="Select the topic(s) of the request",
labels=data.info.features['label'].names, #these are the original labels present in the dataset
visible_labels=10
),
rg.LabelQuestion(
name="sentiment",
title="What is the sentiment of the message?",
labels=["positive", "neutral", "negative"]
)
]
)
训练模型#
现在,我们将使用我们加载的数据以及我们为数据集配置的标签和问题,为数据集中每个问题训练一个零样本文本分类模型。
[ ]:
def train_model(question_name, template, multi_label=False):
# build a training dataset that uses the labels of a specific question in our Argilla dataset
train_dataset = get_templated_dataset(
candidate_labels=dataset.question_by_name(question_name).labels,
sample_size=8,
template=template,
multi_label=multi_label
)
# train a model using the training dataset we just built
if multi_label:
model = SetFitModel.from_pretrained(
"all-MiniLM-L6-v2",
multi_target_strategy="one-vs-rest"
)
else:
model = SetFitModel.from_pretrained(
"all-MiniLM-L6-v2"
)
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset
)
trainer.train()
return model
[ ]:
topic_model = train_model(
question_name="topics",
template="The customer request is about {}",
multi_label=True
)
config.json not found in HuggingFace Hub.
WARNING:huggingface_hub.hub_mixin:config.json not found in HuggingFace Hub.
model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
***** Running training *****
Num examples = 24640
Num epochs = 1
Total optimization steps = 1540
Total train batch size = 16
[ ]:
sentiment_model = train_model(
question_name="sentiment",
template="This message is {}",
multi_label=False
)
config.json not found in HuggingFace Hub.
WARNING:huggingface_hub.hub_mixin:config.json not found in HuggingFace Hub.
model_head.pkl not found on HuggingFace Hub, initialising classification head with random weights. You should TRAIN this model on a downstream task to use it for predictions and inference.
***** Running training *****
Num examples = 960
Num epochs = 1
Total optimization steps = 60
Total train batch size = 16
进行预测#
训练步骤结束后,我们可以对我们的数据进行预测。
[ ]:
def get_predictions(texts, model, question_name):
probas = model.predict_proba(texts, as_numpy=True)
labels = dataset.question_by_name(question_name).labels
for pred in probas:
yield [{"label": label, "score": score} for label, score in zip(labels, pred)]
[ ]:
data = data.map(
lambda batch: {
"topics": list(get_predictions(batch["text"], topic_model, "topics")),
"sentiment": list(get_predictions(batch["text"], sentiment_model, "sentiment")),
},
batched=True,
)
[ ]:
data.to_pandas().head()
| 文本 | 标签 | 主题 | 情感 | |
|---|---|---|---|---|
| 0 | 如何找到我的卡? | 11 | [{'label': 'activate_my_card', 'score': 0.0127... | [{'label': 'positive', 'score': 0.348371499634... |
| 1 | 我仍然没有收到我的新卡,我订购了... | 11 | [{'label': 'activate_my_card', 'score': 0.0133... | [{'label': 'positive', 'score': 0.361745933281... |
| 2 | 我订购了一张卡,但它没有到。 帮忙... | 11 | [{'label': 'activate_my_card', 'score': 0.0094... | [{'label': 'positive', 'score': 0.346292075496... |
| 3 | 有什么方法知道我的卡什么时候到吗? | 11 | [{'label': 'activate_my_card', 'score': 0.0150... | [{'label': 'positive', 'score': 0.426133716131... |
| 4 | 我的卡还没有到。 | 11 | [{'label': 'activate_my_card', 'score': 0.0175... | [{'label': 'positive', 'score': 0.389241385165... |
构建记录并推送#
有了我们生成的数据和预测,现在我们可以构建包含模型建议的记录。在 LabelQuestion 的情况下,我们将使用获得最高概率分数的标签,对于 MultiLabelQuestion,我们将包含所有得分高于某个阈值的标签。在本例中,我们决定使用 2/len(labels),但您可以根据您的数据进行实验,并决定使用更严格或更宽松的阈值。
提示
请注意,更宽松的阈值(接近或等于 1/len(labels))将建议更多标签,而更严格的阈值(介于 2 和 3 之间)将选择更少(或没有)标签。
[ ]:
def add_suggestions(record):
suggestions = []
# get label with max score for sentiment question
sentiment = max(record['sentiment'], key=lambda x: x['score'])['label']
suggestions.append({"question_name": "sentiment", "value": sentiment})
# get all labels above a threshold for topics questions
threshold = 2 / len(dataset.question_by_name("topics").labels)
topics = [label['label'] for label in record['topics'] if label['score'] >= threshold]
# apply the suggestion only if at least one label was over the threshold
if topics:
suggestions.append({"question_name": "topics", "value": topics})
return suggestions
[ ]:
records = [
rg.FeedbackRecord(fields={"text": record['text']}, suggestions=add_suggestions(record))
for record in data
]
一旦我们对结果感到满意,我们可以将记录添加到我们上面配置的数据集中,将其推送到 Argilla 并开始标注。
[ ]:
dataset.add_records(records)
[ ]:
dataset.push_to_argilla("setfit_tutorial", workspace="admin")
Pushing records to Argilla...: 100%|██████████| 97/97 [00:21<00:00, 4.58it/s]
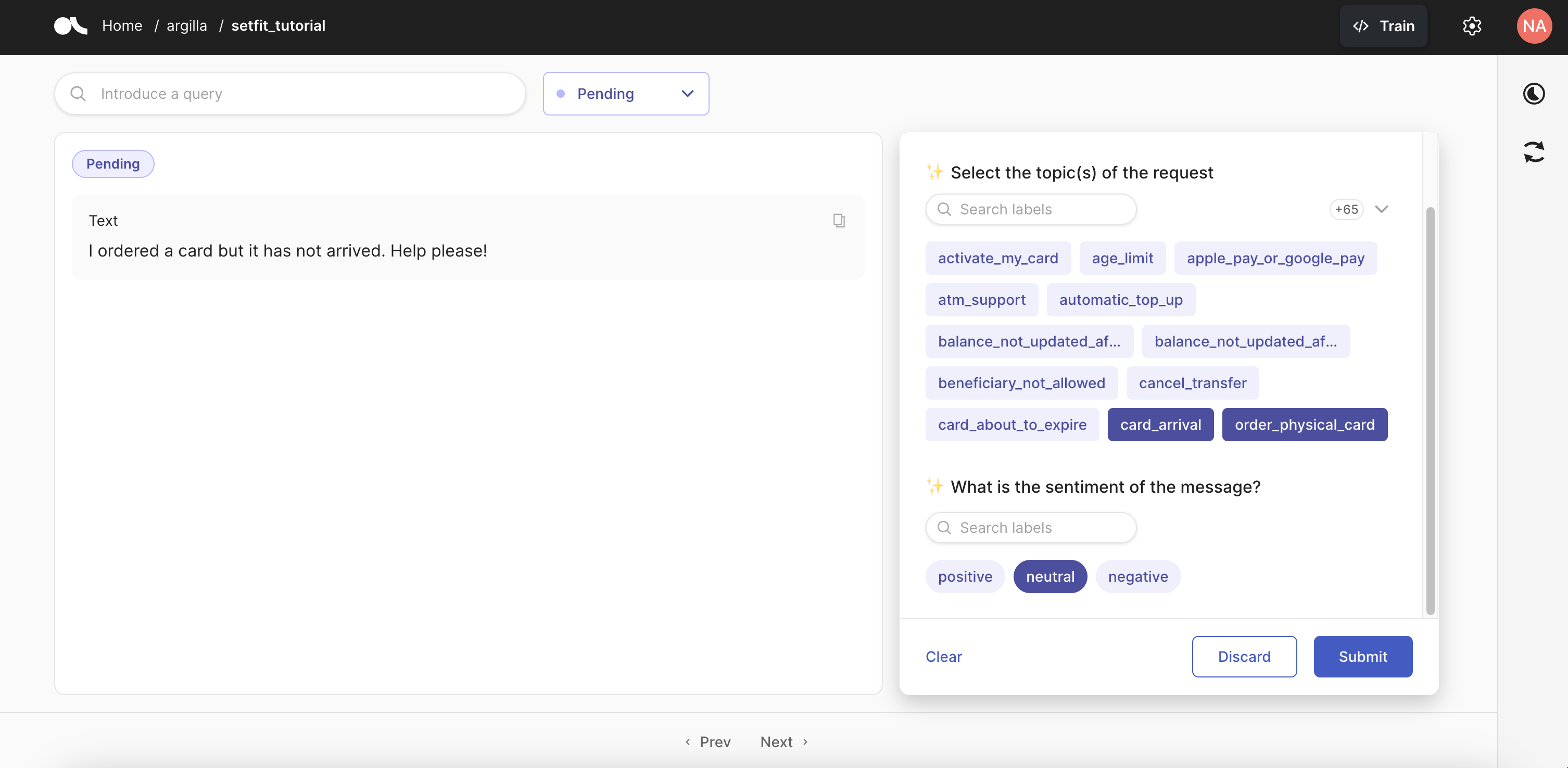
这就是带有我们模型建议的 UI 的样子:
结论#
在本教程中,我们介绍了如何使用 SetFit 库的零样本方法向反馈任务数据集添加建议。这将通过减少标注团队必须做出的决策和编辑次数来帮助提高标注过程的效率。
要了解有关 SetFit 的更多信息,请查看以下链接