将元数据属性添加到 FeedbackDataset#
在本系列教程的 FeedbackDatasets 部分中,我们将展示如何使用元数据属性来增强数据集。我们将拉取数据集,添加各种元数据属性并将其上传回去。您可以查看之前的教程,了解创建数据集和配置用户和工作区。请随时查看实践指南页面以获取更深入的信息。
利用元数据属性是丰富数据集的有效方法,从而实现有效的筛选和排序。它们是每个记录的信息片段,可以在 UI 和 SDK 中访问。Argilla 提供了各种类型的元数据属性,允许您根据特定项目的需求定制其用途。

目录#
运行 Argilla#
在本教程中,您将需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla: 如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,您只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看官方 Hugging Face Hub 指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在本地机器上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种选项可以运行它
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 Notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 Notebook 并在本地机器或您选择的 Jupyter Notebook 工具上运行它。
首先,让我们安装我们的依赖项并导入必要的库
[ ]:
!pip install argilla
!pip install datasets
[1]:
import argilla as rg
from argilla._constants import DEFAULT_API_KEY
import statistics
import random
为了运行此 Notebook,我们将需要一些凭据来从 Argilla 和 🤗 Hub 推送和加载数据集,让我们在以下单元格中设置它们
[3]:
# Argilla credentials
api_url = "https://:6900" # "https://<YOUR-HF-SPACE>.hf.space"
api_key = DEFAULT_API_KEY # admin.apikey
# Huggingface credentials
hf_token = "hf_..."
登录到 argilla
[ ]:
rg.init(api_url=api_url, api_key=api_key)
启用遥测#
我们从您与我们教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
拉取数据集#
由于我们在之前的教程中创建的数据集已上传到 Argilla 和 HuggingFace Hub,我们可以从其中任何一个拉取数据集。让我们看看如何从两者中拉取数据集。
从 Argilla#
我们可以使用 from_argilla 方法从 Argilla 拉取数据集。
[5]:
dataset_remote = rg.FeedbackDataset.from_argilla("end2end_textclassification")
从 HuggingFace Hub#
我们也可以从 HuggingFace Hub 拉取数据集。类似地,我们可以使用 from_huggingface 方法来拉取数据集。
[ ]:
dataset = rg.FeedbackDataset.from_huggingface("argilla/end2end_textclassification")
注意
从 HuggingFace Hub 拉取的数据集是 FeedbackDataset 的实例,而从 Argilla 拉取的数据集是 RemoteFeedbackDataset 的实例。两者之间的区别在于前者是本地的,对其所做的更改保留在本地。另一方面,后者是远程的,对其所做的更改直接反映在 Argilla 服务器上的数据集上,这可以使您的过程更快。
让我们简要检查一下我们的数据集的外观。它是一个数据集,包含带有字段 text 的数据项,该字段尚未被注释。
[7]:
dataset[0].fields
[7]:
{'text': "Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again."}
添加元数据属性#
元数据属性是增强数据集以便在 UI 和 SDK 中进行筛选和排序的好方法。Argilla 提供了不同类型的元数据属性,您可以根据特定项目的需要使用它们。有关元数据属性的更多信息,请查看文档。
TermsMetadataProperty#
TermsMetadataProperty 是一种元数据属性,可用于根据可能的术语或值列表筛选记录的元数据。
[8]:
terms_metadata_property = rg.TermsMetadataProperty(
name="group", title="Annotation Group", values=["group-1", "group-2", "group-3"]
)
请注意,name 将是在内部显示的元数据属性的名称。title 再次是在 UI 中显示的元数据属性的名称。values 将是元数据属性的可能值列表。要将其添加到数据集,我们可以简单地使用 add_metadata_property 方法。
[9]:
dataset.add_metadata_property(terms_metadata_property)
dataset_remote.add_metadata_property(terms_metadata_property)
[9]:
TermsMetadataProperty(name='group', title='Annotation Group', visible_for_annotators=True, type='terms', values=['group-1', 'group-2', 'group-3'])
让我们也将元数据添加到各个记录中。为了在此处进行演示,我们可以创建一个组列表并随机选择一个组分配给每个记录。与往常一样,我们应该注意将记录平均分配到各个组中。
我们首先了解数据集中有多少条记录,以及我们在 TermsMetadataProperty 中定义了多少个组。然后,我们编译一个组名称列表,其长度与记录数相等。
[ ]:
length_dataset = len(dataset)
num_groups = len(terms_metadata_property.values)
groups = [
f"group-{i}"
for i in range(1, num_groups + 1)
for _ in range(
length_dataset // num_groups + (1 if i <= length_dataset % num_groups else 0)
)
]
groups_local = groups.copy()
最后,我们随机选择一个组名称,将其分配给记录并从列表中删除。
在 FeedbackDataset 和 RemoteFeedbackDataset 之间,添加过程略有不同。对于前者,我们可以简单地通过分配值来添加元数据。对于后者,我们应该使用 update_records 方法。让我们看看如何在两者中都这样做。
[10]:
# For the local dataset
for record in dataset.records:
random_record = random.choice(groups_local)
record.metadata["group"] = random_record
groups_local.remove(random_record)
[ ]:
# For the remote dataset (if you run the previous cell, you should create the groups again)
modified_records = [record for record in dataset_remote.records]
for record in modified_records:
random_record = random.choice(groups)
record.metadata["group"] = random_record
groups.remove(random_record)
dataset_remote.update_records(modified_records)
聚合元数据值#
此外,我们有机会为单个记录的 TermsMetadataProperty 添加多个元数据值。当记录属于多个类别时,这非常有用。对于手头的示例案例,让我们想象一下,其中一个记录(或任意数量的记录)要由两个组进行注释。我们可以简单地通过提供元数据值列表来编码此信息。让我们看看如何在本地 FeedbackDataset 中完成它,并且对于 RemoteFeedbackDataset 来说,过程与上面相同。
[ ]:
dataset[1].metadata["group"] = ["group-1", "group-2"]
我们在这里看到了如何为 TermsMetadataProperty 添加聚合元数据值的示例。请注意,这也适用于 IntegerMetadataProperty 和 FloatMetadataProperty,您可以以相同的方式添加它们。
IntegerMetadataProperty#
Argilla 提供的第二种元数据属性类型是 IntegerMetadataProperty,它可用于根据整数值范围筛选记录的元数据。虽然 name 和 title 与 TermsMetadataProperty 相同,但我们没有 values 参数。相反,我们有 min 和 max 参数,它们定义了整数值的范围。让我们创建一个 IntegerMetadataProperty 并将其添加到我们的数据集中。
由列表中最长和最短数据项组成的元数据属性对我们很有用。为了添加它,让我们首先找出最长和最短的数据项是什么。
[16]:
item_list = [items.fields["text"] for items in dataset]
max_length_string = len(max(item_list, key=len))
min_length_string = len(min(item_list, key=len))
我们现在可以使用最短和最长数据项长度创建项目长度的元数据属性,并将其添加到我们的数据集中。
[17]:
integer_metadata_property = rg.IntegerMetadataProperty(
name="length",
title="Length of the text",
min=min_length_string,
max=max_length_string,
)
dataset.add_metadata_property(integer_metadata_property)
dataset_remote.add_metadata_property(integer_metadata_property)
[17]:
IntegerMetadataProperty(name='length', title='Length of the text', visible_for_annotators=True, type='integer', min=100, max=862)
让我们将元数据添加到各个记录。我们将把数据项的长度添加到每个记录的元数据中。同样,对于 FeedbackDataset 和 RemoteFeedbackDataset,我们的做法有所不同。
[18]:
# For local dataset
for record in dataset.records:
record.metadata["length"] = len(record.fields["text"])
[19]:
# For remote dataset
modified_records = [record for record in dataset_remote.records]
for record in modified_records:
record.metadata["length"] = len(record.fields["text"])
dataset_remote.update_records(modified_records)
FloatMetadataProperty#
我们可以用于数据集的第三种也是最后一种元数据属性类型是 FloatMetadataProperty。此元数据属性可用于根据浮点值范围筛选记录的元数据。name 和 title 参数与其他元数据属性相同。与 IntegerMetadataProperty 类似,我们有 min 和 max 参数,它们定义了浮点值的范围。
在处理文本数据时,我们可能希望评估文本长度并按项目长度筛选数据集。为此,我们可以利用项目长度的标准偏差以及平均项目长度。有了它们,我们可以保留或处理长度在距平均值一定标准偏差范围内的项目。我们可以创建一个 FloatMetadataProperty,其最小值为平均值减去标准偏差,最大值为平均值加上标准偏差。让我们首先计算项目长度的平均值和标准偏差。
[20]:
item_len_list = [len(items.fields["text"]) for items in dataset]
std = round(statistics.stdev(item_len_list), 3)
mean = statistics.mean(item_len_list)
现在我们知道项目长度的平均值和标准偏差是多少,让我们创建一个 FloatMetadataProperty 并将其添加到我们的数据集中。
[21]:
float_metadata_property = rg.FloatMetadataProperty(
name="length_std",
title="Standard deviation of the length of the text",
min=mean - std,
max=mean + std,
)
dataset.add_metadata_property(float_metadata_property)
dataset_remote.add_metadata_property(float_metadata_property)
[21]:
FloatMetadataProperty(name='length_std', title='Standard deviation of the length of the text', visible_for_annotators=True, type='float', min=139.096, max=361.398)
现在我们已将浮点元数据属性添加到我们的数据集,让我们将元数据添加到各个记录。我们将再次添加数据项的长度。但是,这一次,我们将以浮点数形式添加它,并且仅添加到长度在平均值减去标准偏差和平均值加上标准偏差之间的记录。让我们看看如何在 FeedbackDataset 和 RemoteFeedbackDataset 中都这样做。
[22]:
# For local dataset
for record in dataset.records:
record_len = float(len(record.fields["text"]))
if record_len <= mean + std and record_len >= mean - std:
record.metadata["length_std"] = record_len
[23]:
# For remote dataset
modified_records = [record for record in dataset_remote.records]
for record in modified_records:
record_len = float(len(record.fields["text"]))
if record_len <= mean + std and record_len >= mean - std:
record.metadata["length_std"] = record_len
dataset.update_records(modified_records)
结果数据集现在是一个具有元数据属性的数据集,可用于筛选和排序。
[24]:
dataset
[24]:
FeedbackDataset(
fields=[TextField(name='text', title='Text', required=True, type=<FieldTypes.text: 'text'>, use_markdown=False)]
questions=[LabelQuestion(name='label', title='Label', description=None, required=True, type=<QuestionTypes.label_selection: 'label_selection'>, labels=['World', 'Sports', 'Business', 'Sci/Tech'], visible_labels=None)]
guidelines=Classify the articles into one of the four categories.)
metadata_properties=[TermsMetadataProperty(name='group', title='Annotation Group', visible_for_annotators=True, type='terms', values=['group-1', 'group-2', 'group-3']), IntegerMetadataProperty(name='length', title='Length of the text', visible_for_annotators=True, type='integer', min=100, max=862), FloatMetadataProperty(name='length_std', title='Standard deviation of the length of the text', visible_for_annotators=True, type='float', min=139.096, max=361.398)])
)
[ ]:
dataset_remote
按元数据筛选和排序#
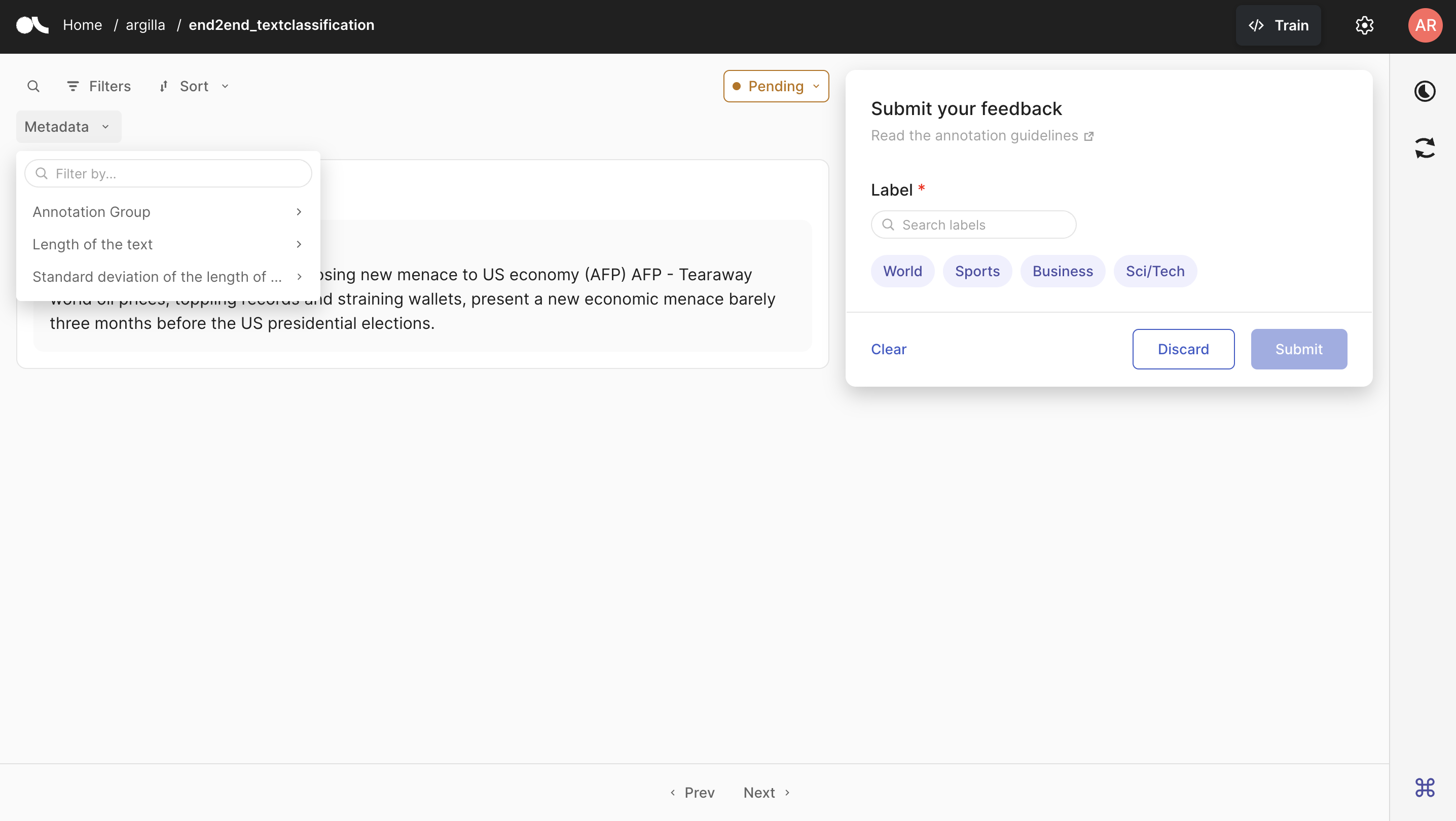
UI 允许我们使用元数据属性进行筛选,并将所需的筛选器组合起来。在下面,您可以看到一个示例,我们按元数据 Annotation Group、Length of the text 和 Standard Deviation 属性进行筛选,这样从 1000 条记录中,我们只得到了 242 条。请注意,如果它们设置为 visible_for_annotators=False,则只会对具有 admin 或 owner 角色的用户显示。
这对于在公共工作区中将记录分配给您的团队成员也非常有用。有关更多信息,请参阅如何分配记录。

现在,我们将使用 Python SDK 中提供的 filter_by 方法进行相同的筛选。因此,我们将需要组合这三个筛选器。此外,每个元数据都是不同的类型,因此我们将需要对注释组使用 TermsMetadataFilter,对文本长度使用 IntegerMetadataFilter,对标准偏差使用 FloatMetadataFilter。我们将使用以下参数
描述 |
TermsMetadataFilter |
IntegerMetadataFilter |
FloatMetadataFilter |
|
|---|---|---|---|---|
名称 |
元数据属性的名称 |
group |
length |
length_std |
ge |
大于或等于的值 |
no-required |
0 |
204 |
le |
小于或等于的值 |
no-required |
282 |
290 |
values |
搜索的值 |
group-1 和 group-2 |
no-required |
no-required |
在 Integer 和 Float 筛选器的情况下,应至少提供
ge或le之一。
[ ]:
filtered_records = dataset_remote.filter_by(
metadata_filters=[
rg.TermsMetadataFilter(
name="group",
values=["group-1", "group-2"]
),
rg.IntegerMetadataFilter(
name="length",
le=282
),
rg.FloatMetadataFilter(
name="length_std",
ge=204,
le=290
),
]
)
print(len(filtered_records))
242
现在,我们还可以按元数据属性和上次更新时间对它们进行排序。
[ ]:
from argilla import SortBy
filtered_dataset = dataset_remote.filter_by(
metadata_filters=[
rg.TermsMetadataFilter(
name="group",
values=["group-1", "group-2"]
),
rg.IntegerMetadataFilter(
name="length",
le=282
),
rg.FloatMetadataFilter(
name="length_std",
ge=204,
le=290
),
],
response_status=["discarded"]
).sort_by(
[
SortBy(field="updated_at", order="desc"),
SortBy(field="metadata.group", order="asc")
]
)
推送数据集#
我们现在已经在元数据属性方面增强了我们的数据集,我们可以再次推送它。请注意,您不必再次将改进版本的数据集上传到 Argilla。正如您在 Argilla UI 上看到的那样,数据集已经具有我们添加的元数据属性。
到 Argilla#
如果您选择从 HuggingFace 拉取数据集并想要推送到 Argilla,您可以简单地使用 push_to_argilla 方法。
[ ]:
try:
remote_dataset = rg.FeedbackDataset.from_argilla("end2end_textclassification_with_metadata")
remote_dataset.delete()
except:
pass
remote_dataset = dataset.push_to_argilla("end2end_textclassification_with_metadata")
remote_dataset
现在我们可以看到 Argilla 上的数据集具有我们添加的元数据属性。
到 HuggingFace Hub#
如果您选择从 HuggingFace Hub 拉取数据集,则可以使用 push_to_huggingface 方法将数据集推送到 HuggingFace Hub。不要忘记也创建一个模型卡,这将使数据集对于用户来说更具可读性和可理解性。
为了能够将数据集上传到 Hub,您必须登录到 Hub。以下单元格将使用我们之前的令牌登录我们。
如果我们还没有令牌,我们可以从这里获取(记住设置写入权限)。
[ ]:
from huggingface_hub import login
login(token=hf_token)
我们只需要调用 push_to_huggingface 方法即可将数据集推送到 HuggingFace Hub。如果我们在 Hub 上有同名数据集,则此方法将更新现有数据集。
[ ]:
#papermill_description=push-dataset-to-huggingface
dataset.push_to_huggingface("argilla/end2end_textclassification_with_metadata", generate_card=True)
结论#
在本教程中,我们已经了解了如何使用元数据属性来增强我们的数据集。我们首先了解了如何从 Argilla 或 HuggingFace Hub 拉取数据集。然后,我们了解了如何将 TermsMetadataProperty、IntegerMetadataProperty 和 FloatMetadataProperty 添加到我们的数据集,并使用它们进行筛选和排序。我们还了解了 RemoteFeedbackDataset 的工作原理以及如何将数据集推送到 HuggingFace Hub。要添加记录的向量表示以进行语义搜索,您可以查看下一个教程。有关如何使用各种工具的更多详细信息,请参阅我们的实践指南。