创建 FeedbackDataset#
本教程是系列教程的一部分,我们将在此系列教程中了解 FeedbackDataset。在开始本教程之前,您需要完成关于配置用户和工作区的教程。在这一步中,我们将展示如何配置 FeedbackDataset 并向其添加 FeedbackRecords。如果您需要更多背景信息,请查阅关于创建数据集的实践指南。

我们将从创建一个基本数据集开始,使用 ag_news 数据集作为示例,并将其推送到 Argilla 和 Hugging Face hub。
目录#
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 主要有两种选择
在 Hugging Face Spaces 上部署 Argilla: 如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,您只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看官方 Hugging Face Hub 指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在本地机器上运行 Argilla,这是推荐选项。请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种选择可以运行它
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 Notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 Notebook 并在本地机器或您选择的 Jupyter Notebook 工具上运行它。
首先,让我们安装我们的依赖项并导入必要的库
[ ]:
!pip install argilla
!pip install datasets
[1]:
import argilla as rg
from argilla._constants import DEFAULT_API_KEY
from datasets import load_dataset
为了运行此 Notebook,我们将需要一些凭据来从 Argilla 和 🤗hub 推送和加载数据集,让我们在以下单元格中设置它们
[2]:
# Argilla credentials
api_url = "https://:6900" # "https://<YOUR-HF-SPACE>.hf.space"
api_key = DEFAULT_API_KEY # admin.apikey
# Huggingface credentials
hf_token = "hf_..."
登录到 Argilla
[ ]:
#papermill_description=logging-to-argilla
rg.init(
api_url=api_url,
api_key=api_key
)
启用遥测#
我们从您与我们的教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
配置 FeedbackDataset#
在本教程中,我们将使用 ag_news 数据集,该数据集可以从 🤗hub 下载。我们将仅从训练样本中加载前 1000 个项目。
[6]:
ds = load_dataset("ag_news", split="train[:1000]")
ds
[6]:
Dataset({
features: ['text', 'label'],
num_rows: 1000
})
我们将在本教程中仅加载前 1000 条记录,但您可以随意测试完整数据集。
此数据集包含新闻文章的集合(我们可以在 text 列中查看内容),这些文章已被分配以下分类 labels 之一:世界 (0)、体育 (1)、商业 (2)、科技 (3)。
让我们使用任务模板来创建一个准备用于 text-classification 的反馈数据集。
[20]:
feedback_dataset = rg.FeedbackDataset.for_text_classification(
labels=["World", "Sports", "Business", "Sci/Tech"],
guidelines="Classify the articles into one of the four categories.",
)
feedback_dataset
[20]:
FeedbackDataset(
fields=[TextField(name='text', title='Text', required=True, type='text', use_markdown=False)]
questions=[LabelQuestion(name='label', title='Label', description='Classify the text by selecting the correct label from the given list of labels.', required=True, type='label_selection', labels=['World', 'Sports', 'Business', 'Sci/Tech'], visible_labels=None)]
guidelines=Classify the articles into one of the four categories.)
metadata_properties=[])
)
我们可以将此数据集与我们之前使用的自定义配置进行比较(我们可以查看自定义配置,以获取有关当我们想要更精细的控制时创建 FeedbackDataset 的更多信息)
[8]:
feedback_dataset_long = rg.FeedbackDataset(
guidelines="Classify the articles into one of the four categories.",
fields=[
rg.TextField(name="text", title="Text from the article"),
],
questions=[
rg.LabelQuestion(
name="label",
title="In which category does this article fit?",
labels={"World": "0", "Sports": "1", "Business": "2", "Sci/Tech": "3"},
required=True,
visible_labels=None
)
]
)
feedback_dataset_long
[8]:
FeedbackDataset(
fields=[TextField(name='text', title='Text from the article', required=True, type='text', use_markdown=False)]
questions=[LabelQuestion(name='label', title='In which category does this article fit?', description=None, required=True, type='label_selection', labels={'World': '0', 'Sports': '1', 'Business': '2', 'Sci/Tech': '3'}, visible_labels=None)]
guidelines=Classify the articles into one of the four categories.)
metadata_properties=[])
)
添加 FeedbackRecords#
从 Hugging Face dataset#
一旦我们创建了 FeedbackDataset,下一步就是向其添加 FeedbackRecords。
为了创建我们的记录,我们可以简单地循环遍历 datasets.Dataset 中的项目。
[9]:
records = []
for i, item in enumerate(ds):
records.append(
rg.FeedbackRecord(
fields={
"text": item["text"],
},
external_id=f"record-{i}"
)
)
# We can add an external_id to each record to identify it later.
从 pandas.DataFrame#
如果我们的数据采用不同的格式,比如 csv 文件,那么使用 pandas 读取数据可能更直接。
我们将把我们的数据集转换为 pandas 格式以进行此示例,其余的 FeedbackRecord 创建保持不变
[10]:
df_dataset = ds.to_pandas()
df_dataset.head()
[10]:
| text | label | |
|---|---|---|
| 0 | Wall St. Bears Claw Back Into the Black (Reute... | 2 |
| 1 | Carlyle Looks Toward Commercial Aerospace (Reu... | 2 |
| 2 | Oil and Economy Cloud Stocks' Outlook (Reuters... | 2 |
| 3 | Iraq Halts Oil Exports from Main Southern Pipe... | 2 |
| 4 | Oil prices soar to all-time record, posing new... | 2 |
[ ]:
records_pandas = []
for i, item in df_dataset.iterrows():
records_pandas.append(
rg.FeedbackRecord(
fields={
"text": item["text"],
},
external_id=f"record-{i}"
)
)
让我们将记录添加到数据集中
[21]:
feedback_dataset.add_records(records)
到目前为止,我们的数据集已准备好进行标注的文本,让我们将其推送到 Argilla。
保存和加载 FeedbackDataset#
从 Argilla#
[ ]:
#papermill_description=push-dataset-to-argilla
try:
# delete old dataset
remote_dataset = feedback_dataset.from_argilla(name="end2end_textclassification", workspace="argilla")
remote_dataset.delete()
except:
pass
remote_dataset = feedback_dataset.push_to_argilla(name="end2end_textclassification", workspace="argilla")
如果我们转到我们的 Argilla 实例,我们应该看到类似以下内容的屏幕。
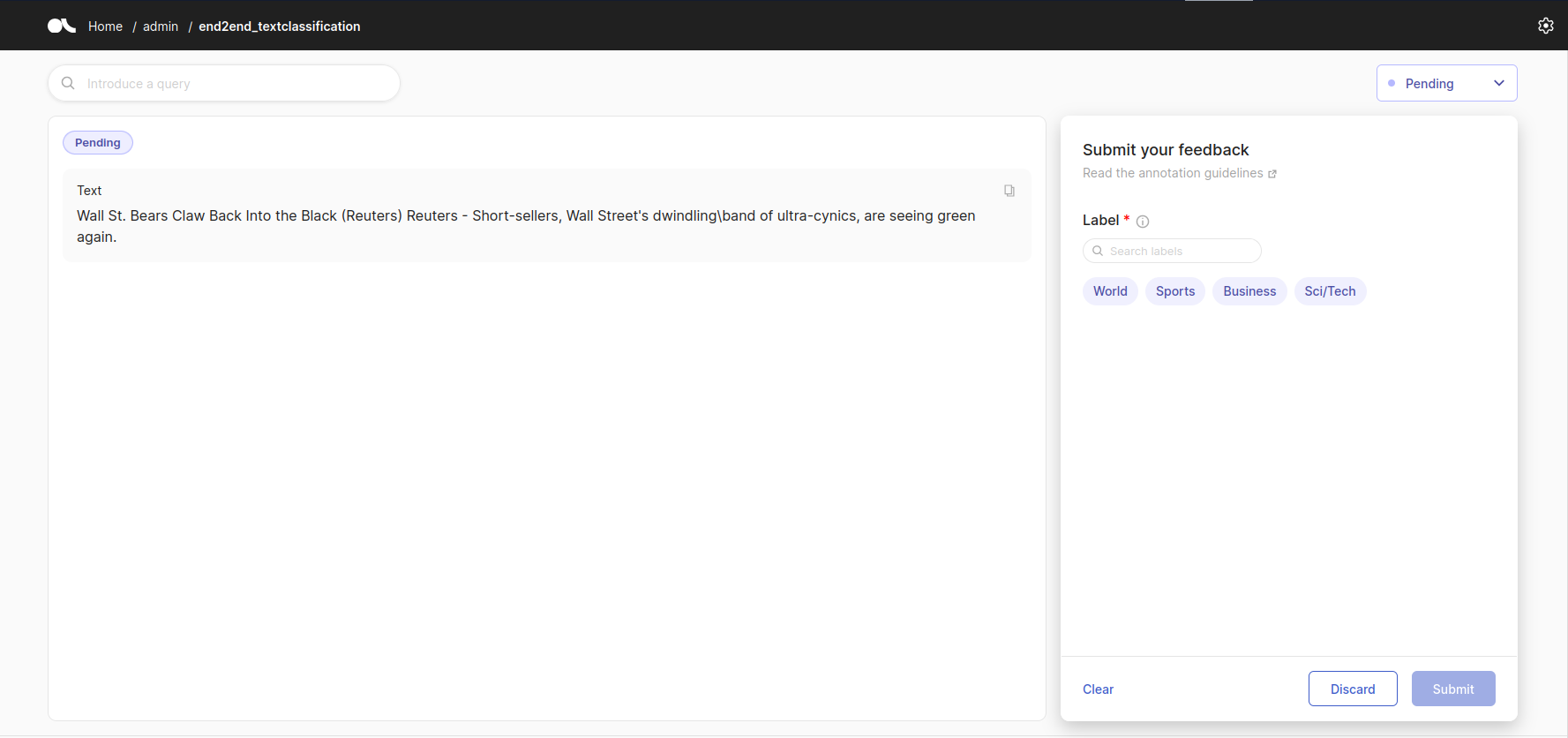
我们可以在其中看到我们想要的文章文本,以及要选择的不同标签。
我们现在可以从 Argilla 下载数据集以进行检查
[15]:
remote_dataset = rg.FeedbackDataset.from_argilla("end2end_textclassification", workspace="argilla")
remote_dataset
[15]:
RemoteFeedbackDataset(
id=52b0dfc2-ed85-4805-923c-5d51b51ec4c9
name=end2end_textclassification
workspace=Workspace(id=ce760ed7-0fdf-4d79-b9b7-1c0e4ea896cd, name=argilla, inserted_at=2023-11-23 09:46:05.591993, updated_at=2023-11-23 09:46:05.591993)
url=https://:6900/dataset/52b0dfc2-ed85-4805-923c-5d51b51ec4c9/annotation-mode
fields=[RemoteTextField(id=UUID('2835bf0e-1259-45b9-a97c-f9b671395563'), client=None, name='text', title='Text', required=True, type='text', use_markdown=False)]
questions=[RemoteLabelQuestion(id=UUID('bb6fc4f0-e4b7-480c-84a1-df717de4ac97'), client=None, name='label', title='Label', description=None, required=True, type='label_selection', labels=['World', 'Sports', 'Business', 'Sci/Tech'], visible_labels=None)]
guidelines=Classify the articles into one of the four categories.
metadata_properties=[]
)
从 Hugging Face Hub#
如果我们想与世界分享我们的数据集,我们可以使用 Hugging Face Hub。
首先我们需要登录到 Hugging Face。以下单元格将使用我们之前的令牌登录我们。
如果我们还没有令牌,我们可以从这里获取(记住设置写入访问权限)。
[ ]:
from huggingface_hub import login
login(token=hf_token)
现在我们可以直接在 FeedbackDataset 上调用该方法。
[ ]:
#papermill_description=push-dataset-to-huggingface
remote_dataset.push_to_huggingface("argilla/end2end_textclassification")
我们现在可以从 Hugging Face 下载数据集以进行检查
[ ]:
local_dataset = rg.FeedbackDataset.from_huggingface("argilla/end2end_textclassification")
结论#
在本教程中,我们从 ag_news 开始,为文本分类创建了一个 Argilla FeedbackDataset。
我们使用 LabelQuestion 为文本分类创建了一个 FeedbackDataset,数据存储为 datasets.Dataset 和 pandas.DataFrame。此数据集被推送到了 Argilla,我们可以在其中管理和标注记录,并最终将其推送到 🤗hub。
要了解有关如何使用 FeedbackDataset 的更多信息,请查看速查表。要继续将记录分配给标注员,您可以参考下一个教程。