🧹 使用 cleanlab 查找和清理标签错误#
在本教程中,我们将利用 Argilla 和 cleanlab 来查找、发现和纠正潜在的标签错误。您可以通过遵循 4 个基本的 MLOps 步骤来完成此操作
💾 加载一个包含潜在标签错误的数据集,这里我们使用 ag_news 数据集;
💻 训练一个模型来对测试集进行预测,这里我们使用轻量级的 sklearn 模型;
🧐 通过 Argilla 使用 cleanlab,并在测试集中获得潜在的标签错误候选;
🖍 使用 Argilla Web 应用程序快速舒适地发现和纠正标签错误;
简介#
正如 Curtis G. Northcutt 等人 最近表明的那样,即使在用于基准测试机器学习领域进展的最常被引用的测试集中,标签错误也普遍存在。他们引入了一个新的原则性框架,以“识别标签错误、描述标签噪声并使用噪声标签进行学习”,称为 置信学习。它以 cleanlab Python 包 的形式开源,该软件包支持查找、量化和使用数据集中的标签错误进行学习。
Argilla 提供了对 cleanlab 的内置支持,并且可以轻松地在您的数据集中找到潜在的标签错误。在本教程中,我们将尝试发现和纠正著名的 ag_news 数据集中的标签错误,该数据集通常用于基准测试 NLP 中的分类模型。
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部笔记本(例如,Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,则只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地机器上运行 Argilla,建议使用此选项。请注意,此选项仅允许您在本地运行教程,而不能与外部笔记本服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种运行它的选项
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 Notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 Notebook 并在本地计算机上或您选择的 Jupyter Notebook 工具上运行它。
[ ]:
%pip install argilla datasets scikit-learn cleanlab -qqq
让我们导入 Argilla 模块以进行数据读取和写入
[ ]:
import argilla as rg
如果您正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
最后,让我们包含我们需要导入的模块
[ ]:
from datasets import load_dataset
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from argilla.labeling.text_classification import find_label_errors
启用遥测#
我们从您与我们的教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
注意
如果您想跳过本教程的前三个部分,并且仅在 Argilla Web 应用程序中发现和纠正标签错误,您可以直接从 Hugging Face Hub 加载记录
records_with_label_errors = rg.read_datasets(
load_dataset("argilla/cleanlab-label_errors", split="train"),
task="TextClassification",
)
1. 加载数据集#
我们首先通过非常方便的 datasets 库下载 ag_news 数据集。然后,我们提取训练集和测试集,以及此分类任务的标签。我们还对训练集进行洗牌,因为默认情况下它是按分类标签排序的。
[ ]:
# Download the data
dataset = load_dataset("ag_news")
# Get the train set and shuffle
ds_train = dataset["train"].shuffle(seed=43)
# Get the test set
ds_test = dataset["test"]
# Get the classification labels
labels = ds_train.features["label"].names
2. 训练模型#
在本教程中,我们将使用多项式 朴素贝叶斯分类器,这是一个轻量级且易于训练的 sklearn 模型。但是,您可以使用您选择的任何模型,只要它在其预测中包含所有标签的概率即可。
我们分类器的特征将只是输入文本的标记计数。
定义分类器后,我们可以使用我们的训练集来拟合它。由于我们使用的是相当轻量级的模型,因此这应该不会花费太长时间。
[ ]:
# Define our classifier as a pipeline of token counts + naive bayes model
classifier = Pipeline([("vect", CountVectorizer()), ("clf", MultinomialNB())])
# Fit the classifier
classifier.fit(X=ds_train["text"], y=ds_train["label"])
让我们检查一下我们的模型在测试集上的表现如何。
[ ]:
# Compute the test accuracy
classifier.score(
X=ds_test["text"],
y=ds_test["label"],
)
我们应该获得 0.90 的不错准确率,特别是考虑到我们仅使用标记计数作为输入特征。
3. 获取标签错误候选#
作为在我们的测试集中获取标签错误候选的第一步,我们必须预测所有标签的概率。
[ ]:
# Get predicted probabilities for all labels
probabilities = classifier.predict_proba(ds_test["text"])
有了预测结果,我们创建 Argilla 记录,其中包含文本输入、模型的预测、潜在的错误注释以及您选择的一些元数据。
[ ]:
# Create records for the test set
records = [
rg.TextClassificationRecord(
text=data["text"],
prediction=list(zip(labels, prediction)),
annotation=labels[data["label"]],
metadata={"split": "test"},
)
for data, prediction in zip(ds_test, probabilities)
]
我们可以将这些记录直接记录到 Argilla 并方便地用肉眼检查它们,检查每个文本输入的注释。但是,在这里我们将使用一种更快的方法,即利用 Argilla 对 cleanlab 的内置支持。您只需从 Argilla 导入 find_label_errors 函数,然后传入记录列表即可。就这样。
[ ]:
# Get records with potential label errors
records_with_label_error = find_label_errors(records)
records_with_label_error 列表包含大约 600 个潜在标签错误候选,这超过了我们测试数据的 8%。
4. 发现和纠正标签错误#
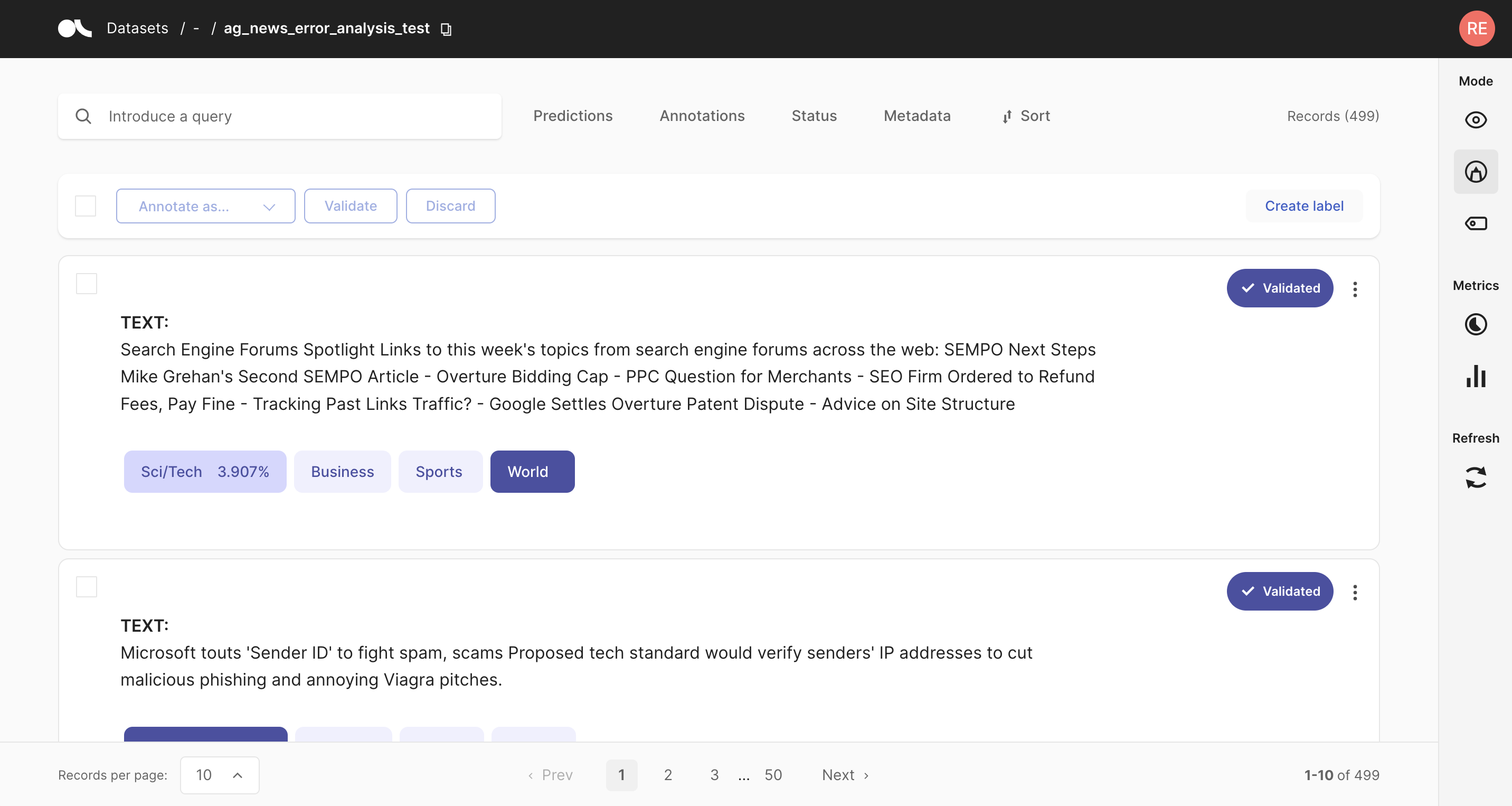
现在让我们将这些记录记录到 Argilla Web 应用程序中,以便方便地用肉眼检查它们,并同时快速纠正潜在的标签错误。
[ ]:
# Uncover label errors in the Argilla web app
rg.log(records_with_label_error, "label_errors")
默认情况下,records_with_label_error 列表中的记录按其包含标签错误的似然性排序。它们还将默认包含一个名为 “label_error_candidate” 的元数据,该元数据反映了列表中的顺序。您可以使用 Argilla Web 应用程序中的此字段对记录进行排序。
我们可以确认,最有可能的候选确实是明显的标签错误。在候选列表的末尾,示例变得更加模棱两可,并且 gold 注释是否错误并不立即显而易见。
总结#
借助 Argilla,您可以快速方便地在数据中找到标签错误。对 cleanlab 的内置支持,以及 Argilla Web 应用程序的优化用户体验,使该过程变得轻而易举,并允许您高效地动态纠正标签错误。
只需几个步骤,您就可以快速检查您的测试数据集是否受到标签错误的严重影响,以及您的基准测试在实践中是否真正有意义。也许您不太复杂的模型最终会击败您资源匮乏的超级模型,并且部署过程变得更容易了一些 😀。
虽然我们在本教程中仅使用了 sklearn 模型,但 Argilla 并不关心模型架构或您正在使用的框架。它只关心底层数据,并允许您将更多人纳入您的人工智能生命周期循环中。
附录 I:使用交叉验证查找训练数据中的标签错误#
为了检查您的训练数据是否存在标签错误,您可以回退到交叉验证技术以获得样本外预测。对于来自 sklearn 的分类器,交叉验证非常容易,您可以在一行代码中方便地完成它。之后,创建 Argilla 记录、查找标签错误候选和发现它们的步骤与上面教程中显示的步骤相同。
[ ]:
from sklearn.model_selection import cross_val_predict
# Get predicted probabilities for the whole dataset via cross-validation
cv_probs = cross_val_predict(
classifier,
X=ds_train["text"] + ds_test["text"],
y=ds_train["label"] + ds_test["label"],
cv=int(len(ds_train) / len(ds_test)),
method="predict_proba",
n_jobs=-1,
)
[ ]:
# Create records for the training set
records = [
rg.TextClassificationRecord(
text=data["text"],
prediction=list(zip(labels, prediction)),
annotation=labels[data["label"]],
metadata={"split": "train"},
)
for data, prediction in zip(ds_train, cv_probs)
]
# Uncover label errors for the train set in the Argilla web app
rg.log(find_label_errors(records), "label_errors_in_train")
在这里,我们找到大约 9400 条包含潜在标签错误的记录,这也大约占训练数据的 8%。
附录 II:将数据集记录到 Hugging Face Hub#
在这里,我们将向您展示一个示例,说明如何将 Argilla 数据集(记录)推送到 Hugging Face Hub。通过这种方式,您可以有效地对您的任何 Argilla 数据集进行版本控制。
[ ]:
records = rg.load("label_errors")
records.to_datasets().push_to_hub("<name of the dataset on the HF Hub>")