❓ 使用 transformers 和 Argilla 训练 QnA 模型#
您可能至少有一次发现自己处于需要从 Google 获得非常具体问题的答案的情况。 Google 很可能以粗体字母给出了您答案(“埃菲尔铁塔有多重?- 10,100 吨”)或者 Google 仅突出显示了结果中的某些文本(“自由女神像的原始颜色是什么?”)。无论哪种方式,Google 都使用了一种特定的算法来为您完成查找答案的工作,从而使您免于阅读大量页面或使用 Ctrl+F。尽管没有确认页面或找到的信息的可靠性,但它还是设法提出了针对该问题的确切答案(在发布本文时,它错误地将自由女神像突出显示为“蓝绿色”)。这项任务 - 在一段文本中为给定的问题找到确切的答案 - 称为抽取式问答,它是当今许多 QnA 或 LLM 系统的主要流程之一。在这篇博文中,我们将了解如何使用 Argilla 创建用于抽取式 QnA 的端到端流程。
以下是我们将遵循的步骤
创建用于抽取式 QnA 的数据集
向数据集添加建议
推送到 Argilla 并进行注释
定义模型
实现
ArgillaTrainer训练模型
进行预测
简介#
问答 (QnA) 任务主要分为两种:抽取式 QnA 和生成式 QnA。生成式 QnA(或抽象式 QnA)是指 QnA 系统生成类人、自然语言答案来回答问题的任务。为此,生成式 QnA 系统使用检索器-生成器架构,而不是抽取式 QnA 使用的检索器-阅读器架构。由于它需要更深入地理解文本和自然语言生成,因此就当今的性能而言,生成式模型尚未赶上抽取式模型。但是,由于它提供了更复杂的流程和输出,因此将来将有更多潜力。
另一方面,我们刚刚看到的任务是抽取式 QnA 的一个示例,其中模型在文本中找到将用作给定问题答案的确切跨度。从这个意义上讲,此任务正式包含一个 (q,c,a) 元组,训练目标是最小化 -log(Pstart) 和 -log(Pend) 之间的损失,其中 Pstart 和 Pend 是答案跨度的开始和结束索引的概率。
Argilla 提供了从管道开始到结束的所有必要工具。我们将使用 Argilla 注释我们的数据集,并使用 ArgillaTrainer 训练 QnA 模型。ArgillaTrainer 提供与 transformers 的平滑集成,这将使您能够在训练器本身内实现整个训练过程。让我们首先开始安装所需的库并导入必要的模块。
运行 Argilla#
对于本教程,您将需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla: 如果您想使用外部 Notebook(例如 Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,则只需单击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在 本地计算机上运行 Argilla,建议使用此选项。请注意,此选项仅允许您在本地运行教程,而不能与外部 Notebook 服务一起运行。
有关部署选项的更多信息,请查看文档的“部署”部分。
提示
本教程是一个 Jupyter Notebook。有两种运行它的选项
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 Notebook。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 Notebook 并在本地计算机或您选择的 Jupyter Notebook 工具上运行它。
安装依赖项#
让我们首先安装依赖项。
[ ]:
%pip install argilla transformers datasets evaluate
然后导入必要的模块。
[1]:
import argilla as rg
from datasets import load_dataset
from argilla.feedback import ArgillaTrainer, TrainingTask
from transformers import pipeline, AutoTokenizer, AutoModelForQuestionAnswering
import torch
使用 init 函数初始化 Argilla 客户端。如果您在公共 HF Space 上运行 Argilla,则可以将 api_url 更改为您的 Spaces URL。
[4]:
# Replace api_url with the url to your HF Spaces URL
# Replace api_key with the default or custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="argilla.apikey",
workspace="argilla",
)
如果您正在运行私有 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
启用遥测#
我们从您与教程的互动中获得了宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。尽管这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
创建数据集#
作为 QnA 流程的第一步,我们将需要一个由注释者注释的数据集。为此,我们将需要创建一个数据集,其中包含问题和上下文以在其中搜索答案。我们的注释者将通过从上下文中给出问题的答案来构建答案。对于本教程,我们将使用 squad 数据集,这是一个用于抽取式 QnA 的流行数据集。我们将首先忽略答案,并将 squad 中的问题-上下文对加载到 Argilla,以展示注释过程。我们将使用 datasets 库下载数据集。让我们创建数据集并查看其结构。
[63]:
dataset_hf = load_dataset("squad", split="train")
dataset_hf
[63]:
Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 87599
})
我们的数据集由上下文-问题-答案三元组以及每个数据项的 id 和标题组成。在您自己的数据集中,您也可以考虑使用每个数据项的 id,因为这将有助于数据组织,尤其是在训练前和训练后。此数据集总共包含 87599 个项目,这对于训练 QnA 模型来说是一个非常好的数字。
让我们看一下我们在开始注释过程之前拥有的数据项之一。
[64]:
dataset_hf[0]
[64]:
{'id': '5733be284776f41900661182',
'title': 'University_of_Notre_Dame',
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'answers': {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}}
squad 是一个从维基百科文章中提取的问题-上下文-答案三元组数据集。如上面的 title 字段所示,每个数据项都来自特定的维基百科文章。context 字段包含文章的文本,question 包含要回答的问题,answers 包含上下文中的答案跨度,这些跨度已由人工注释。answer_start 是给定上下文中答案的起始索引。我们现在将忽略 answers 字段,而仅使用 context 和 question 字段。
创建 FeedbackDataset#
让我们创建我们的 FeedbackDataset 并添加来自 squad 的数据项。要创建 FeedbackDataset,我们将使用 Argilla 的任务模板,这使得任何 NLP 任务的过程都变得更加容易。您可以从 此处 获得有关任务模板的更多信息。
[16]:
dataset = rg.FeedbackDataset.for_question_answering()
此方法刚刚为我们创建了基本的 QnA 任务模板,其中包含 context 和 question 字段以及 answer 问题,注释者将使用该问题来构建答案。
现在我们已经准备好数据集,我们可以通过为每个项目添加建议,将来自 squad 的数据项作为 records 添加到我们的数据集中。
添加建议#
为了帮助我们的注释者并加快注释过程,我们可以向数据集添加建议。建议是针对我们的数据项的模型预测,将在注释过程中显示在 Argilla UI 上。由于它是可选的,因此根据您的项目,它将为您节省大量时间。您可以使用您喜欢的任何模型为您的数据集生成模型预测。为了演示目的,我们将在此处使用 deepset/electra-base-squad2。我们可以利用 transformers 中的 pipeline 函数来简化操作。
[17]:
question_answerer = pipeline("question-answering", model="deepset/electra-base-squad2")
让我们通过向每个项目添加建议来从我们的数据集创建记录。
[18]:
records = [
rg.FeedbackRecord(
fields={
"question": item["question"],
"context": item["context"],
},
suggestions=[
{"question_name": "answer",
"value": question_answerer(question=item["question"], context=item["context"])["answer"]},
]
) for item in dataset_hf
]
并将记录添加到我们的数据集中。
[19]:
dataset.add_records(records)
在 Argilla 上注释#
我们现在可以将数据集上传到 Argilla,供我们的注释者注释。他们将通过在 answer 字段中写入答案跨度来注释每个项目,如果选择了建议,则可以使用模型提示。如果您想更好地控制注释过程并操作其他一些功能,可以参考我们的 Argilla UI 页面以获取更多信息。
[20]:
remote_dataset = dataset.push_to_argilla(name="demonstration_data_squad", workspace="argilla")
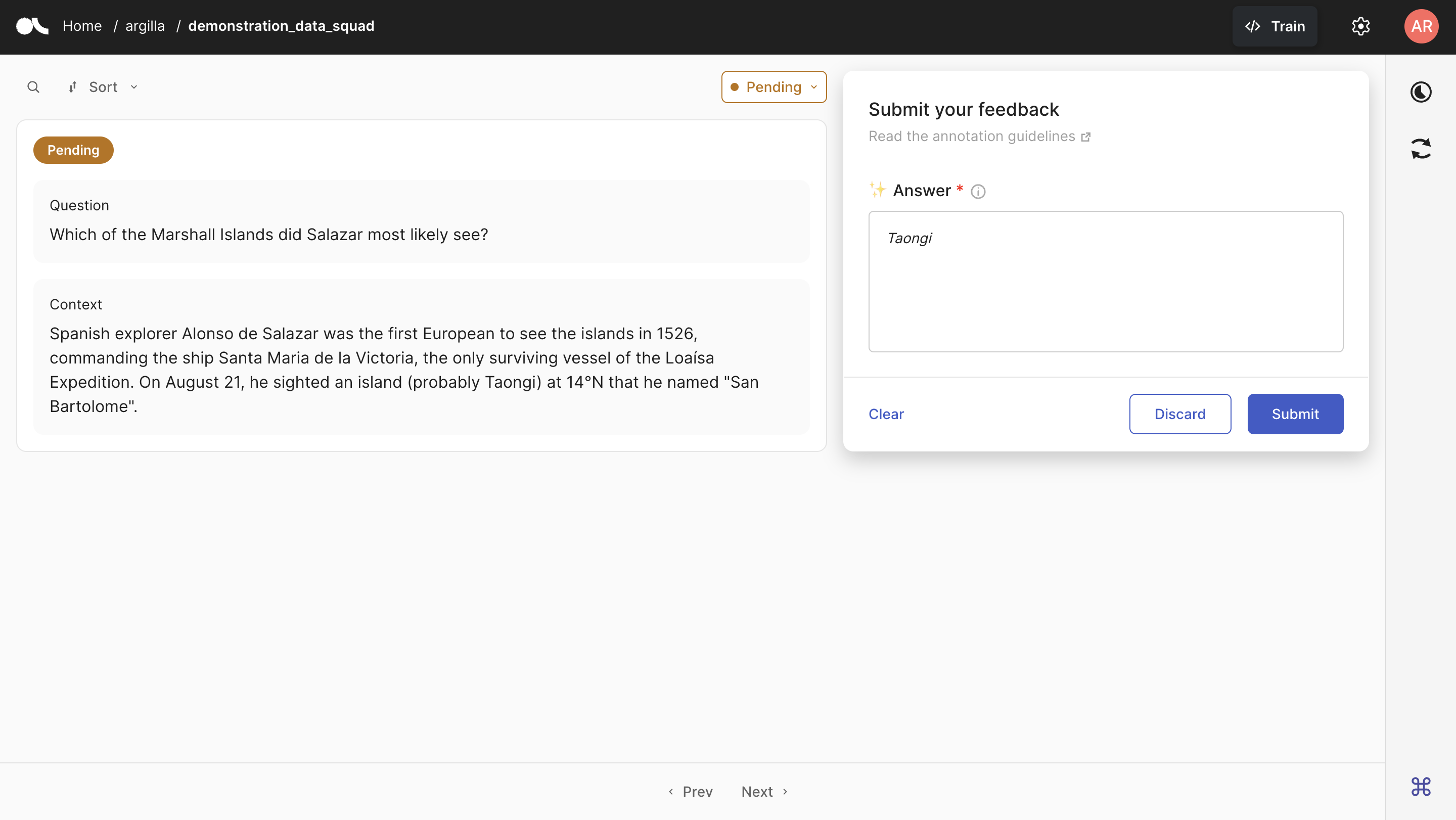
以下是 Argilla 界面,注释者将在其中注释数据项。我们上传的问题-上下文对显示在左侧。在右侧,是注释面板,注释者将在其中写下他们的答案。在 Answer 框中,我们还看到我们上传的建议以斜体字母书写,这将有助于注释者的注释过程。
训练模型#
注释工作完成后,我们可以下载我们注释的数据集。请注意,通过 from_argilla 函数下载的数据集是一个远程数据集对象,这意味着您所做的任何更改都会直接反映在远程数据集上。
[33]:
annotated_dataset = rg.FeedbackDataset.from_argilla("demonstration_data_squad", workspace="argilla")
在继续训练之前,让我们检查一下我们获得的注释。手动检查一些注释将使我们对注释的质量和数据集本身有所了解。
[62]:
item = annotated_dataset[3]
print(f"Question: {item.fields['question']}\nContext: {item.fields['context']}\nAnnotated Answer: {item.responses[0].values['answer'].value}")
Question: To somewhat avoid the water vapor in the atmosphere, where can an observatory be sited?
Context: The sensitivity of Earth-based infrared telescopes is significantly limited by water vapor in the atmosphere, which absorbs a portion of the infrared radiation arriving from space outside of selected atmospheric windows. This limitation can be partially alleviated by placing the telescope observatory at a high altitude, or by carrying the telescope aloft with a balloon or an aircraft. Space telescopes do not suffer from this handicap, and so outer space is considered the ideal location for infrared astronomy.
Annotated Answer: at a high altitude
注意
抽取式 QnA 背后的主要动机是在给定的文本中找到确切的答案片段。这就是为什么答案必须完全包含在给定的上下文中。因此,强烈建议检查答案是否包含错别字。我们的模型将跳过答案未包含在上下文中的项目。
现在,让我们定义我们将要使用的模型和分词器。我们将在此处使用 distilbert-base-uncased-distilled-squad 进行演示,并使用我们的注释者注释的数据集对其进行微调。
[ ]:
model_name = "distilbert-base-uncased-distilled-squad"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"Using {torch.cuda.get_device_name(0)}")
else:
device = torch.device("cpu")
print("No GPU available, using CPU instead.")
实现 ArgillaTrainer#
现在我们已经准备好数据集,我们可以开始训练我们的模型。为此,我们将使用 Argilla 中的 ArgillaTrainer 类。ArgillaTrainer 是对各种框架的包装,并提供它们与 Argilla 之间的平滑集成。它允许您使用几行代码在 Argilla 上训练您的模型。您可以从此处获得有关 ArgillaTrainer 的更多信息。
我们首先需要定义将由 ArgillaTrainer 使用的 task。TrainingTask 类为不同的 NLP 任务提供了各种任务,我们将使用 for_question_answering 方法创建我们的任务。我们还为我们的任务创建了一个 formatting_func,它将根据模型的要求处理我们的数据集。
请注意,我们没有从注释者给出的答案中计算答案跨度。这是因为 ArgillaTrainer 本身将从注释者给出的答案中计算答案的开始和结束索引。这是使用 ArgillaTrainer 的主要优势之一,因为它将使您免于自己计算答案跨度的麻烦。
[23]:
def formatting_func(sample):
question = sample["question"]
context = sample["context"]
for answer in sample["answer"]:
if not all([question, context, answer["value"]]):
continue
yield question, context, answer["value"]
task = TrainingTask.for_question_answering(formatting_func=formatting_func)
在准备好任务后,我们现在可以创建 ArgillaTrainer 实例。请注意,我们需要在训练器内部定义我们的框架,我们将在此处使用 transformers。在没有模型馈送到训练器的情况下,训练器将为任务使用默认模型。我们将上面定义的模型传递给训练器。此外,我们告诉模型训练大小将为 0.7。
[ ]:
trainer = ArgillaTrainer(
dataset=annotated_dataset,
task=task,
model=model,
framework="transformers",
train_size=0.7,
tokenizer=tokenizer,
)
您有机会在使用 update_config 方法初始化后更改训练器配置。让我们进一步配置我们的训练过程。
[ ]:
trainer.update_config(
learning_rate = 4e-2,
weight_decay = 0.01,
max_grad_norm = 1,
num_train_epochs = 3,
logging_strategy = "steps",
save_strategy = "steps",
save_steps = 100,
)
我们现在可以使用 train 方法训练模型。
[ ]:
trainer.train("./my_qna_model")
推理#
现在我们已经训练了模型,我们可以使用它来查找给定问题和上下文的答案跨度。我们可以使用 transformers 中的 pipeline 函数来简化操作。它将为我们提供答案以及答案跨度的开始和结束索引。
[29]:
qna_pipeline = pipeline(
"question-answering",
model="my_qna_model",
tokenizer=tokenizer,
device=device
)
我们只需要向函数馈送问题和上下文即可获得答案。
[28]:
qna_pipeline(question="For what is Venezuela famous?", context="Venezuela is known for its natural beauty.")
[28]:
{'score': 0.6827161908149719,
'start': 27,
'end': 41,
'answer': 'natural beauty'}
在本教程中,我们已经了解了如何使用 Argilla 创建用于抽取式 QnA 的端到端流程。我们首先创建了用于抽取式 QnA 的数据集,并向其中添加了建议。然后,我们将数据集推送到 Argilla 并对其进行了注释。之后,我们定义了模型并实现了 ArgillaTrainer 来训练模型。最后,我们使用训练后的模型进行了预测。有关 Argilla 和 ArgillaTrainer 其他用法的更多教程,请参阅我们的 教程 页面。