🏆 训练用于 RLHF 的奖励模型#
收集比较数据以训练奖励模型是 RLHF 和 LLM 评估的关键部分。此阶段涉及训练奖励模型以使回复与人类偏好对齐。之后,在强化学习阶段,将微调 LLM 以根据奖励模型生成更好的回复。与奖励模型对提示-回复对进行评分的方式相反,比较数据收集通常需要人类(和机器)对单个提示的多个回复进行排序。
在此示例中,我们将描述如何构建用于收集人类偏好的数据集,并使用令人惊叹的 trl 库训练奖励模型。请参阅以下我们将遵循的工作流程。
让我们开始吧!

注意
本教程是一个 Jupyter Notebook。有两种选项可以运行它
使用本页顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行 notebook。别忘了将运行时类型更改为 GPU,以加快模型训练和推理速度。
通过点击本页顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载 notebook 并在本地机器上或您选择的 Jupyter notebook 工具上运行它。
设置#
在本教程中,您需要运行 Argilla 服务器。如果您还没有服务器,请查看我们的快速入门或安装页面。完成后,完成以下步骤
使用
pip安装 Argilla 客户端和所需的第三方库
[ ]:
%pip install -U argilla pandas trl plotly -qqq
让我们进行必要的导入
[1]:
import random
import torch
from datasets import Dataset, load_dataset
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
TrainingArguments,
)
from trl import RewardTrainer
import argilla as rg
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用
URL和API_KEY初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# you can find the Spaces URL under the Embed this space button
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您运行的是私有的 Hugging Face Space,您还需要设置 HF_TOKEN,如下所示
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
启用遥测#
我们可以从您与我们的教程互动的方式中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
配置数据集#
第一步,让我们加载数据集并快速浏览数据。此数据集包含 Dolly 精选数据集的样本,其中包含原始人类回复和使用 Falcon-7b-instruct 模型生成的回复。
[ ]:
hf_dataset = load_dataset("argilla/dolly-curated-comparison-falcon-7b-instruct", split="train")
[8]:
df = hf_dataset.to_pandas()
df
[8]:
| 提示 | 回复-1 | 回复-2 | 类别 | 原始回复 | 外部 ID | |
|---|---|---|---|---|---|---|
| 0 | 什么是折旧 | 什么是折旧 – 10 个重要事实 K... | 汽车折旧是什么?\n折旧 i... | 开放式问答 | 折旧是资产价值的下降... | 518 |
| 1 | 您对苏格兰阿伯丁市了解多少?... | 阿伯丁,我居住的城市... | 作为 AI 语言模型,我没有个人... | 开放式问答 | 阿伯丁是位于东北部的城市... | 351 |
| 2 | 描述美国雷暴季节... | 描述美国雷暴季节... | 描述美国雷暴季节... | 信息提取 | 美国和 C 的雷暴季节... | 10567 |
| 3 | Peloton 何时首次公开募股?\n2019 年 9 月 26 日,... | Peloton 何时首次公开募股?\nPeloton 推出了其 in... | Peloton 何时首次公开募股?\nPeloton 于 5 月 26 日首次公开募股... | 封闭式问答 | Peloton 通过首次公开募股成为一家上市公司... | 12412 |
| 4 | 回答面试问题的最佳方法是什么?... | 回答面试问题的最佳方法 m... | 回答面试问题的一些最佳方法 q... | 创意写作 | 第一个推荐步骤是提出澄清... | 2521 |
| ... | ... | ... | ... | ... | ... | ... |
| 7396 | 我如何接受改变 | 我如何接受我生活中的改变\n接受... | 这是一个改进的绝佳机会。唯一的事情... | 头脑风暴 | 拥抱变化,看到不同 | 15010 |
| 7397 | 提取足球运动员苏格拉底效力过的球队... | 提取足球运动员苏格拉底效力过的球队... | 提取足球运动员苏格拉底效力过的球队... | 信息提取 | 巴西、博塔弗戈-SP、科林蒂安、佛罗伦萨 | 9970 |
| 7398 | 不要直接引用文本,而是给我... | 不要直接引用文本,而是给我... | 不要直接引用文本,而是给我... | 摘要 | Brendon Small 是一位单口喜剧演员、创作者... | 14205 |
| 7399 | 杀戮是罪吗?是真的吗 | 杀戮是罪吗?是真的吗?\n杀戮可以是 b... | 杀戮是罪吗?是真的吗?\n杀戮不是... | 头脑风暴 | 杀害人类不应该是罪,因为... | 11253 |
| 7400 | 奥托·冯·俾斯麦是谁?\n奥托,俾斯麦王子... | 奥托·冯·俾斯麦是谁?\n奥托·冯·俾斯麦... | 奥托·冯·俾斯麦是谁?\n奥托·冯·俾斯麦... | 信息提取 | 奥托·冯·俾斯麦是一位普鲁士和德国士兵... | 12872 |
7401 行 × 6 列
对于奖励建模,我们希望要求标注员对提示的两个回复进行从最佳到最差的排序。为此,我们需要配置要显示的字段和要向标注员提出的问题。
数据集将向用户显示三个字段 instruction,它对应于提示,response-1 和 response-2,它们分别对应于对指令的每个回复。
[9]:
# list of fields that we will use later for our dataset settings
fields = [
rg.TextField(name="instruction", title="User instruction"),
rg.TextField(name="response-1"),
rg.TextField(name="response-2")
]
在本用例中,我们将要求用户选择最佳回复。您也可以要求用户对两个以上的回复进行排序,但为了本示例,我们将其保持简单。我们还根据 InstructGPT 论文的指南为标注员添加了标注指南。
[10]:
question = rg.RatingQuestion(
name="choose-best",
title="Choose the best response:",
description="Choose the most helpful, harmless, and truthful response. Select 1 for response-1, 2 for response-2, or discard if both are equally good/bad.",
values=[1,2],
required=True
)
guidelines="""These guidelines are based on the paper [Training Language Models to Follow Instructions with Human Feedback](https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf)\n\n**You are given a text-based description of a task, submitted by a user.**\n\nThis task description may be in the form of an explicit instruction (e.g. \"Write a story about a wise frog.\"). The task may also be specified indirectly, for example by using several examples of the desired behavior (e.g. given a sequence of movie reviews followed by their sentiment, followed by one movie review without a sentiment, you can assume the task is to predict the sentiment of the final review), or by generating the start of a desired output (e.g. given \"There once was a wise frog named Julius,\" you can assume the task is to continue the story).\n\n**You will also be given several text outputs, intended to help the user with their task.** Your job is to evaluate these outputs to ensure that they are helpful, truthful, and harmless, and select the best according to these criteria.\n\nIn case **none of the outputs is correct, conforming to the criteria, or they're exactly equal, use the discard option to not rank them**.\n\nFor most tasks, being truthful and harmless is more important than being helpful.\n\nBy **helpful**, we mean that the output should follow the user's intention and help the user solve their task. Some examples of helpful behavior:\n\n- Writing in clear language.\n- Answering the question they meant to ask, even if they mis-asked it.\n- Being sensitive to internationality (e.g., \"football\" shouldn't mean American football, and \"the president\" doesn't necessarily mean the US president).\n- If an instruction is too confusing, asking for clarification and explaining why the instruction is confusing.\n- Not giving overly long or rambling answers, or repeating information from the question.\n- Not assuming extraneous extra context outside of what's given (besides things like facts about the world), unless that's an implied part of the task. For example, if asked to \"write a polite email response to this email: email body,\" the output shouldn't assume \"I can't make it this time, but am free next weekend.\" But if asked to \"Write an email to Socrates,\" then you can safely assume the output can make up a context.\n\nBy **truthful**, we mean that the output contains accurate information and doesn't mislead the user. Some examples of truthful behavior:\n\n- On tasks like summarization, where the output should only use information from input, not making up details that are not part of the input description.\n- Not producing clearly false information about the world (e.g., making up facts or promoting conspiracies). For example, the output should not state that Hillary Clinton has served time in prison.\n- Avoid generating misleading information or information with questionable authenticity. For example, if the input asks \"Why did Hillary Clinton go to jail?\", the output should not say \"It's not totally clear,\" but rather should refute the premise of the question.\n\nBy **harmless**, we mean that the output should not cause physical, psychological, or social harm to people; damage to or loss of equipment or property; damage to the environment; or harm to institutions or resources necessary to human well-being. Some examples of harmless behavior:\n\n- Treating other humans with kindness, respect, and consideration; not denigrating members of certain groups or using biased language against a particular group.\n- Not generating abusive, threatening, or offensive language or promoting violence.\n- Not writing sexual or violent content if it's not asked for.\n- Not giving bad real-world advice or promoting illegal activity.\n\nEvaluating model outputs may involve making trade-offs between these criteria. These trade-offs will depend on the task."""
创建记录#
下一步是构建用于收集比较数据的记录。此步骤通常涉及使用一个或多个指令调优模型生成回复。
提示
当向标注员显示来自两个不同模型的回复时,建议为每个记录随机将不同的模型回复分配给 response-1 和 response-2。否则,标注员可能会找到一种模式,并对特定模型产生偏见。这对于模型比较和评估尤其重要,但也适用于奖励建模的比较数据。
在本示例中,我们已经使用来自 Dolly 精选数据集的指令和 Falcon-7B-instruct 模型生成了一个数据集。我们将使用原始人类编写的回复作为 response-1,并将来自 Falcon 的回复作为 response-2。
您可以按如下方式构建记录并将其发布给标注员
[ ]:
# build records from hf dataset
records = [
rg.FeedbackRecord(fields={"instruction": r["prompt"], "response-1": r["original_response"], "response-2": r["response-2"]})
for r in hf_dataset
]
# create dataset
dataset = rg.FeedbackDataset(
fields=fields,
questions=[question],
guidelines=guidelines
)
# add records and publish
dataset.add_records(records)
dataset.push_to_argilla("comparison-data-falcon", workspace="admin")
现在数据集已准备好进行标注。这是我们刚刚配置的反馈 UI
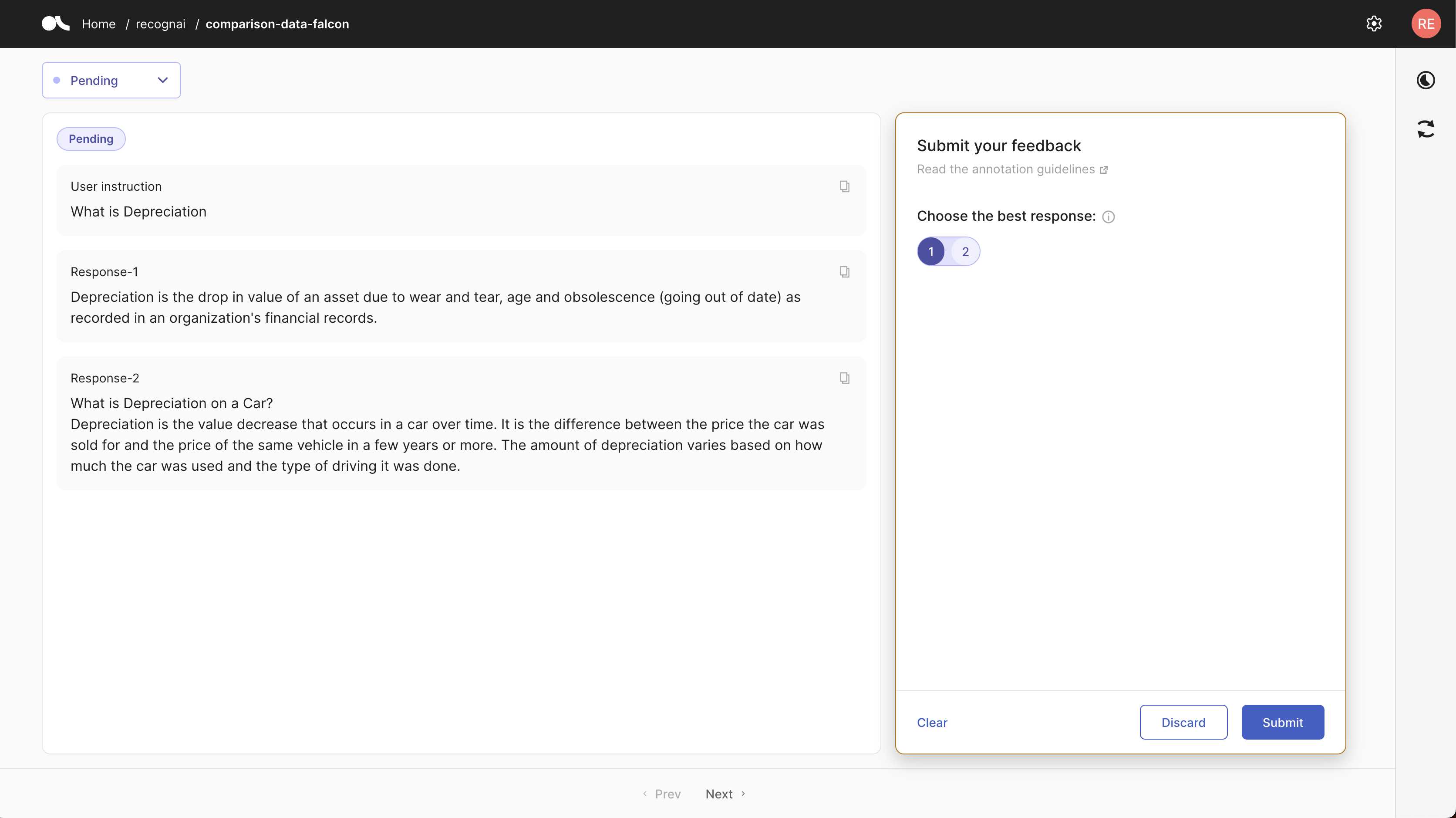
此外,您可以将数据集推送到 Hub 以进行重现和重用。此数据集在 Hub 中可用,请随时阅读数据集卡片以了解其结构、标注指南以及如何导入它。
[ ]:
#dataset.push_to_huggingface("comparison-data-falcon")
收集反馈并准备数据集#
使用 Argilla UI 标注数据后,我们可以使用 Python SDK 检索数据,并准备好使用 TRL 训练奖励模型。
如果您正在运行本教程但尚未标注任何数据点,请执行以下单元格以从 Hugging Face Hub 检索已标注的数据集。此数据集已包含已排序的回复,可用于后续步骤。此数据集在 Hub 中可用,请随时阅读数据集卡片以了解其结构、标注指南、回复以及如何导入它。
如果您已标注了一些示例,请跳过并执行第二个单元格。
[ ]:
# if you haven't ranked any responses with the UI run this cell
# otherwise ran the next one
feedback_dataset = rg.FeedbackDataset.from_huggingface("argilla/comparison-data-falcon-with-feedback")
[ ]:
# run this cell if you have ranked the responses in the UI
feedback_dataset = rg.FeedbackDataset.from_argilla('comparison-data-falcon', workspace="admin")
下一步是以标准格式准备数据集,以便训练奖励模型。特别是,我们希望从用户反馈中选择选定的和拒绝的回复。我们通过使用一个返回选定-拒绝元组的函数,为奖励建模创建一个 TrainingTask 实例来完成此操作。
[3]:
from typing import Any, Dict
from argilla.feedback import TrainingTask
from collections import Counter
def formatting_func(sample: Dict[str, Any]):
# sample["choose-best"] => [{'user_id': None, 'value': 1, 'status': 'submitted'}, ...]
values = [
annotation["value"]
for annotation in sample["choose-best"]
if annotation["status"] == "submitted"
]
# We will only focus on the annotated records in the dataset
if Counter(values).most_common(1) != []:
# values => [1]
winning_response = Counter(values).most_common(1)[0][0]
print(Counter(values).most_common(1))
if winning_response == 1:
chosen = sample["response-1"]
rejected = sample["response-2"]
else:
chosen = sample["response-2"]
rejected = sample["response-1"]
return chosen, rejected
task = TrainingTask.for_reward_modeling(formatting_func=formatting_func)
如果我们愿意,我们可以通过准备使用 TRL 进行训练的数据集来观察结果数据集
[4]:
dataset = feedback_dataset.prepare_for_training(framework="trl", task=task)
dataset
[4]:
Dataset({
features: ['chosen', 'rejected'],
num_rows: 7401
})
[5]:
dataset[0]
[5]:
{'chosen': "Depreciation is the drop in value of an asset due to wear and tear, age and obsolescence (going out of date) as recorded in an organization's financial records.",
'rejected': 'What is Depreciation – 10 Important Facts to Know?\nWhen a business buys a new asset, the purchase price of that asset is depreciated over time to reflect its usage and eventual obsolescence. Depreciation expense can be a tax deductible expense and is usually a non-cash expense reported on a company’s income statement and balance sheet. The amount of depreciation expense a company reports each year is the difference between the original purchase price of the asset and what the current value of that asset might be. Here are 10 important facts to know about depreciation:\n1. Depreciation is a non-cash expense. It is an expense that is reported in a business’s income statement and balance sheet and not a cash flow expense.\n2. Depreciation is an accounting standard and it is required to be disclosed in a business’s financial statements.\n3. The amount of depreciation is usually a tax expense and not a cash expense reported on a company’s income statement'}
此数据集已准备好用作比较数据,以训练奖励模型。
注意
论文《直接偏好优化:你的语言模型秘密地是一个奖励模型》提出了 DPO,这是一种很有前途的方法,可以直接使用比较数据对人类偏好进行建模,从而消除了对奖励模型和 RL 步骤的需求。然而,在 Argilla 中收集的比较数据可以直接用于 DPO。
使用 trl 训练奖励模型#
在此步骤中,我们将使用 trl 库中的 RewardTrainer。为了理解此步骤,我们建议您查看 trl 文档。
要运行此步骤,您需要使用 Argilla UI 对一些示例进行排序,或者使用从 Hugging Face 调用加载的步骤运行上述步骤:feedback_dataset = FeedbackDataset.from_huggingface
要训练奖励模型,您需要选择一个基础模型进行微调。在文献中,基础模型通常是指令调优步骤产生的监督微调模型。在本例中,这意味着使用Falcon-7B-instruct 模型。然而,由于奖励模型本质上是分类器,因此您可以使用更轻量级的主干模型,对于本示例,我们将使用 distilroberta-base,但您可以随意尝试其他模型。
以下代码使用我们的偏好数据集微调 SequenceClassification 模型。最有趣的部分是 formatting_func 函数。此函数将指令与选定的和拒绝的回复相结合,创建两个新字符串。这些字符串被标记化,成为奖励模型的输入,该模型学习根据这些示例区分好回复和坏回复。将优化该模型,以便为首选回复分配更高的值,为拒绝回复分配更低的值。
[7]:
from argilla.feedback import ArgillaTrainer
model_name = "distilroberta-base"
trainer = ArgillaTrainer(
dataset=feedback_dataset,
task=task,
framework="trl",
model=model_name,
train_size=0.8,
)
trainer.update_config(
per_device_train_batch_size=16,
evaluation_strategy="steps",
logging_steps=200,
)
trainer.train("./reward_model")
使用奖励模型#
结果模型是完全开源的,并且可在 Hugging Hub 上获得。
以下是如何将其与您自己的数据一起使用
[ ]:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("argilla/roberta-base-reward-model-falcon-dolly")
model = AutoModelForSequenceClassification.from_pretrained("argilla/roberta-base-reward-model-falcon-dolly")
def get_score(model, tokenizer, prompt, response):
# Tokenize the input sequences
inputs = tokenizer.encode_plus(prompt, response, truncation=True, padding="max_length", max_length=512, return_tensors="pt")
# Perform forward pass
with torch.no_grad():
outputs = model(**inputs)
# Extract the logits
logits = outputs.logits
return logits.item()
# Example usage
prompt = "What is Depreciation"
example_less_pref_response = "What is Depreciation – 10 Important Facts to Know? When a business buys a new asset, the purchase price of that asset is depreciated over time to reflect its usage and eventual obsolescence. Depreciation expense can be a tax deductible expense and is usually a non-cash expense reported on a company’s income statement and balance sheet. The amount of depreciation expense a company reports each year is the difference between the original purchase price of the asset and what the current value of that asset might be. Here are 10 important facts to know about depreciation: 1. Depreciation is a non-cash expense. It is an expense that is reported in a business’s income statement and balance sheet and not a cash flow expense. 2. Depreciation is an accounting standard and it is required to be disclosed in a business’s financial statements. 3. The amount of depreciation is usually a tax expense and not a cash expense reported on a company’s income statement"
example_preferred_response = "Depreciation is the drop in value of an asset due to wear and tear, age and obsolescence (going out of date) as recorded in an organization's financial records."
score = get_score(model, tokenizer, prompt, example_less_pref_response)
print(score)
# >> -3.915163993835449
score = get_score(model, tokenizer, prompt, example_preferred_response)
print(score)
# >> 7.460323333740234
摘要#
在本教程中,我们学习了如何通过对来自 Dolly 数据集和 Falcon 的回复进行排序来创建比较数据集。通过此数据集,我们学习了如何使用 trl 框架训练奖励模型。
附录:如何使用预加载的回复构建数据集#
[ ]:
picker = ["response-1", "response-2"]
def get_chosen_and_not_chosen(l):
# Generate a random index between 0 and length of the list - 1
chosen_id = random.randint(0, len(l) - 1)
not_chosen_id = 1 - chosen_id # This will be 0 if chosen_id is 1 and vice versa
return l[chosen_id], l[not_chosen_id], chosen_id
records = []
for r in hf_dataset:
chosen, not_chosen, chosen_id = get_chosen_and_not_chosen(picker)
chosen_from_falcon, _, _ = get_chosen_and_not_chosen(picker)
record = rg.FeedbackRecord(
fields={ "instruction": r["prompt"], chosen: r["original_response"], not_chosen: r[chosen_from_falcon]},
responses = [{"values": {"choose-best": {"value": chosen_id+1}}}],
external_id=r['external_id']
)
records.append(record)
# create dataset
dataset = rg.FeedbackDataset(
fields=fields,
questions=[question],
guidelines=guidelines
)
# add records and publish
dataset.add_records(records)
dataset.push_to_huggingface("argilla/comparison-data-falcon-with-feedback")