🧸 使用 LLM 进行文本分类和摘要建议,使用 spacy-llm#
在本教程中,我们将实现一个 spacy-llm 管道,以获取 GPT3.5 的模型建议,并将它们作为 suggestions 添加到我们的 FeedbackDataset 中。本教程的流程将是
运行 Argilla 并加载
spacy-llm以及其他库为您的管道定义配置并初始化它
创建您的
FeedbackDataset实例在数据上生成预测,并将它们添加到
records推送到 Argilla
简介#
spacy-llm 是一个将 LLM 的强大功能集成到常规 spaCy 管道中的软件包,从而可以快速实用地提示各种任务。此外,由于它不需要训练数据,因此这些模型已准备好在您的管道中使用。如果您想训练自己的模型或创建自定义任务,spacy-llm 也有助于实现任何自定义管道。
将这个强大的软件包与 Argilla Feedback 数据集一起使用非常容易。我们可以使用我们将创建的管道进行推理,并将它们添加到我们的 FeedbackDataset。
运行 Argilla#
对于本教程,您需要运行 Argilla 服务器。部署和运行 Argilla 有两个主要选项
在 Hugging Face Spaces 上部署 Argilla:如果您想使用外部笔记本(例如,Google Colab)运行教程,并且您在 Hugging Face 上有一个帐户,您只需点击几下即可在 Spaces 上部署 Argilla

有关配置部署的详细信息,请查看 Hugging Face Hub 官方指南。
使用 Argilla 的快速入门 Docker 镜像启动 Argilla:如果您想在本地计算机上运行 Argilla,建议使用此选项。请注意,此选项仅允许您在本地运行本教程,而不能与外部笔记本服务一起运行。
有关部署选项的更多信息,请查看文档的部署部分。
提示
本教程是一个 Jupyter Notebook。有两种运行方式
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行笔记本。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载笔记本并在本地计算机或您选择的 Jupyter 笔记本工具上运行它。
设置#
首先让我们安装任务所需的库,
[ ]:
pip install "spacy-llm[transformers]" "transformers[sentencepiece]" argilla datasets -qqq
并导入它们。
[ ]:
import os
import spacy
from spacy_llm.util import assemble
import argilla as rg
from datasets import load_dataset
import configparser
from collections import Counter
from heapq import nlargest
您需要使用 API_URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="admin.apikey"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
启用遥测#
我们从您与教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
spacy-llm 管道#
为了能够将 GPT3.5 和来自 OpenAI 的其他模型与 spacy-llm 一起使用,我们将需要来自 openai.com 的 API 密钥,并将其设置为环境变量。
[ ]:
os.environ["OPENAI_API_KEY"] = "<YOUR_OPEN_AI_API_KEY>"
有两种方法可以为您的 LLM 任务实现 spacy-llm 管道:在源代码中运行管道或使用 config.cfg 文件来定义管道的所有设置和超参数。在本教程中,我们将使用配置文件,您可以在 此处 获得有关直接在 Python 中运行的更多信息。
首先让我们在配置文件中将管道的设置定义为参数。我们将实现两个任务:文本分类和摘要,我们在 pipeline 命令中定义它们。然后,我们将组件添加到我们的管道中,以使用各自的模型和超参数指定每个任务。
[ ]:
config_string = """
[nlp]
lang = "en"
pipeline = ["llm_textcat","llm_summarization","sentencizer"]
[components]
[components.llm_textcat]
factory = "llm"
[components.llm_textcat.task]
@llm_tasks = "spacy.TextCat.v2"
labels = ["HISTORY","MUSIC","TECHNOLOGY","SCIENCE","SPORTS","POLITICS"]
[components.llm_textcat.model]
@llm_models = "spacy.GPT-3-5.v1"
[components.llm_summarization]
factory = "llm"
[components.llm_summarization.task]
@llm_tasks = "spacy.Summarization.v1"
[components.llm_summarization.model]
@llm_models = "spacy.GPT-3-5.v1"
[components.sentencizer]
factory = "sentencizer"
punct_chars = null
"""
通过这些设置,我们使用 GPT3.5 创建了一个用于英语文本分类和摘要的 LLM 管道。
spacy-llm 提供了各种模型以在您的管道中实现。您可以查看可用的 OpenAI 模型,以及查看如果您想使用开源模型,提供的 HuggingFace 模型。
现在,使用 ConfigParser,我们可以创建配置文件。
[ ]:
config = configparser.ConfigParser()
config.read_string(config_string)
with open("config.cfg", 'w') as configfile:
config.write(configfile)
让我们组装配置文件。
[ ]:
nlp = assemble("config.cfg")
我们已准备好使用我们创建的管道进行推理。
[ ]:
doc = nlp("No matter how hard they tried, Barcelona lost the match.")
doc.cats
推理#
我们需要两个函数,它们将简化推理过程,并为我们提供我们想要的文本类别和摘要。
[ ]:
#returns the category with the highest score
def get_textcat_suggestion(doc):
model_prediction = doc.cats
return max(model_prediction, key=model_prediction.get)
#selects the top N sentences with the highest scores and return combined string
def get_summarization_suggestion(doc):
sentence_scores = Counter()
for sentence in doc.sents:
for word in sentence:
sentence_scores[sentence] += 1
summary_sentences = nlargest(2, sentence_scores, key=sentence_scores.get)
summary = ' '.join(str(sentence) for sentence in summary_sentences)
return summary
加载数据#
在本教程中,我们将使用 HuggingFace 库中的 squad_v2。squad_v2 是一个数据集,由问题及其答案以及在其中搜索答案的上下文组成。我们将仅使用 context 列用于我们的目的。
[ ]:
dataset_hf = load_dataset("squad_v2", split="train").shard(num_shards=10000, index=235)
FeedbackDataset#
现在我们有了用于推理的管道和数据,我们可以创建我们的 Argilla FeedbackDataset 来制作和存储模型建议。对于本教程,我们将创建文本分类任务和摘要任务。Argilla Feedback 允许我们分别使用 LabelQuestion 和 TextQuestion 实现这两个任务。
[ ]:
dataset = rg.FeedbackDataset(
fields=[
rg.TextField(name="text")
],
questions=[
rg.LabelQuestion(
name="label-question",
title="Classify the text category.",
#make sure that the labels are in line with the labels we have defined in config.cfg
labels=["HISTORY","MUSIC","TECHNOLOGY","SCIENCE","SPORTS","POLITICS"]
),
rg.TextQuestion(
name="text-question",
title="Provide a summary for the text."
)
]
)
我们可以通过迭代我们加载的数据集来创建数据集的记录。在执行此操作时,我们将进行推理,并将它们保存在 suggestions 中,使用 get_textcat_suggestion() 和 get_summarization_suggestion() 函数。
[ ]:
records = [
rg.FeedbackRecord(
fields={
"text": doc.text
},
suggestions=[
{"question_name": "label-question",
"value": get_textcat_suggestion(doc)},
{"question_name":"text-question",
"value": get_summarization_suggestion(doc)}
]
) for doc in [nlp(item) for item in dataset_hf["context"]]
]
我们已经创建了记录,让我们将它们添加到 FeedbackDataset。
[ ]:
dataset.add_records(records)
推送到 Argilla#
我们现在准备好将数据集推送到 Argilla,并可以开始收集注释。
[ ]:
remote_dataset = dataset.push_to_argilla(name="squad_spacy-llm", workspace="admin")
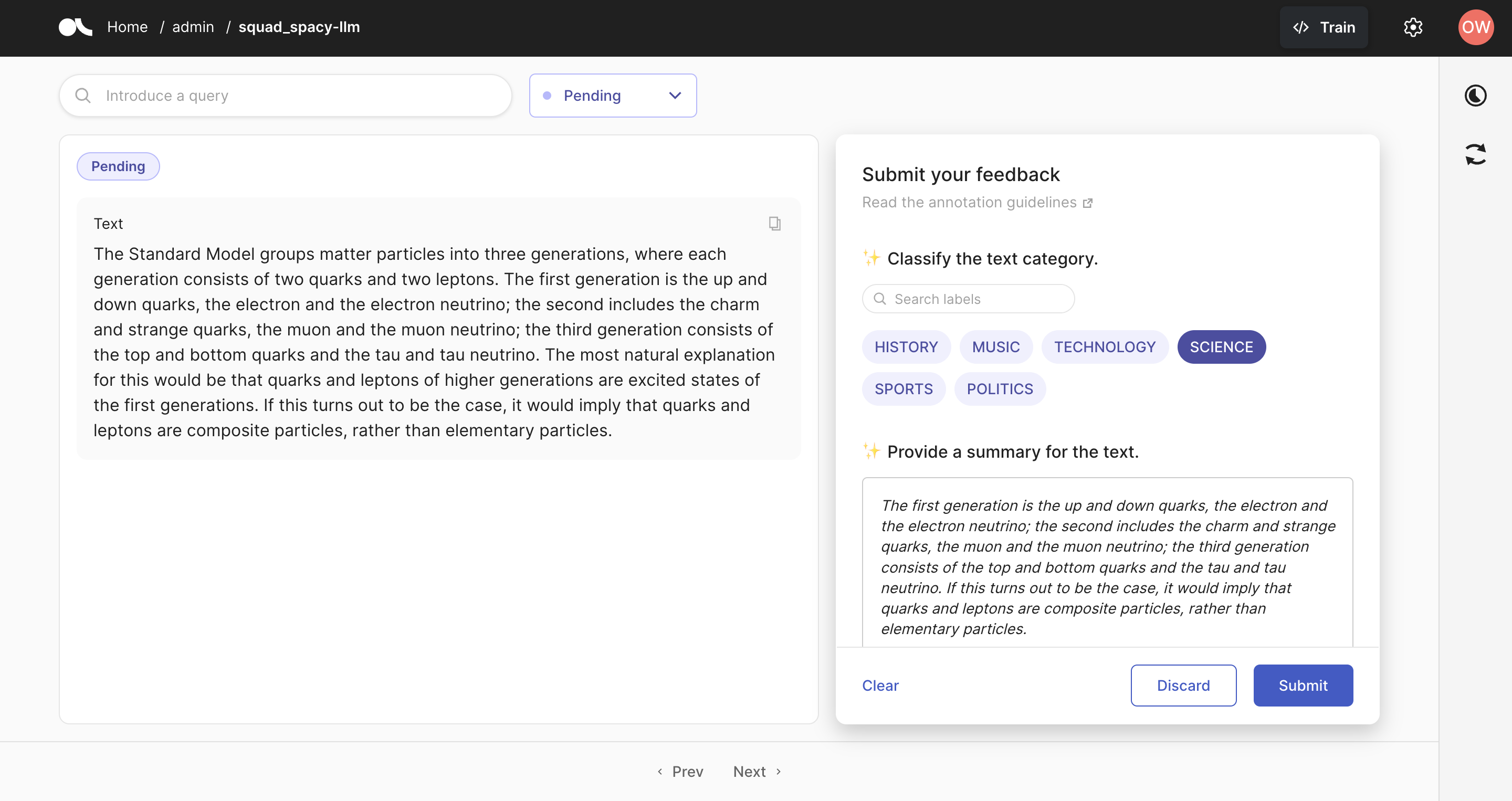
您应该看到 Argilla 页面已准备好进行注释,如下所示。
在本教程中,我们为文本分类和摘要任务实现了一个 spacy-llm 管道。通过 Argilla Feedback 数据集,我们能够将模型预测作为建议添加到我们的数据集中,以便我们的注释者可以利用它们。有关 spacy-llm 的更多信息,您可以访问他们的 LLM 页面,有关 Argilla Feedback 数据集的其他用途,您可以参考我们的指南。