🪄 使用人类反馈微调和评估 GPT-3.5 以用于 RAG#
本指南解释了如何使用你自己的数据和 Argilla 微调 OpenAI 的 GPT3.5-turbo,以改进 RAG(检索增强生成)系统。
它包括以下步骤
使用 LlamaIndex 和 Unstructured 设置 RAG 管道,以使用关于 Argilla Cloud 的文档回答问题。
使用 LlamaIndex 生成潜在问题,以构建训练集和测试集。
构建数据集,用于使用 Argilla 收集人工编写的响应。
使用高质量数据微调 GPT3.5-turbo。
使用来自 Argilla 的人类偏好数据,评估微调模型与基础模型。
本教程的目标是演示如何将人类反馈融入你的 LLM 开发的两个关键阶段
收集用于微调的高质量数据,
收集用于评估 LLM 应用程序的人类反馈。
鉴于检索增强生成 (RAG) 和微调之间持续的争论,我们选择了一个真实的 RAG 用例来演示微调如何增强 RAG 应用程序中响应的风格、实用性和相关性。由此产生的系统将是混合 RAG 系统(使用微调模型的 RAG),如本文所述。
下面的屏幕截图显示了评估数据集,称为“人类偏好数据集”。其中,response-a 由微调模型生成,而 response-b 来自基础 GPT-3.5 模型。通过少量微调,并且不改变系统消息,我们已引导 LLM 的行为朝着生成更实用、更忠实、更友好且更符合我们品牌形象的响应方向发展。
微调有效地缓解了常见的 RAG 挑战,例如 LLM 使用诸如“上下文没有提供有关此信息的信息”之类的短语引用上下文。即使我们在系统消息中加入了诸如“2. 避免使用诸如 ‘基于上下文,…’ 或 ‘上下文信息 …’ 之类的短语。”(请参阅稍后的 Llama Index 默认提示)之类的指令来阻止此类引用,这种增强功能仍然很明显。
你还可以浏览 Argilla Hugging Face Spaces 托管的数据集。用户名和密码:argilla / 12345678。此阶段的数据集是 customer-assistant,评估步骤的数据集是 finetuned-vs-base-preference。
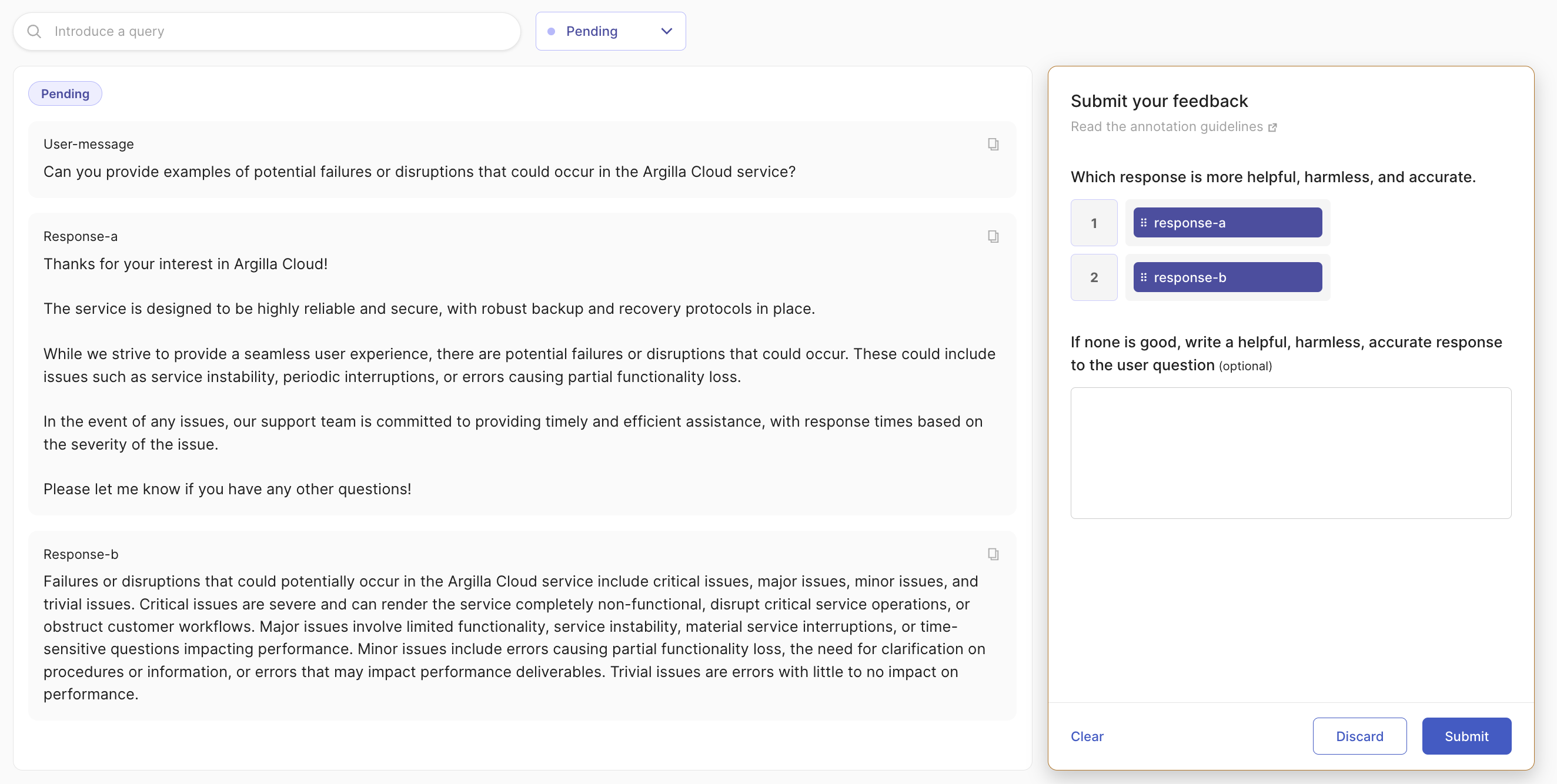
在本教程结束时,你将使用微调模型进行 RAG,并拥有人类评估工作流程,以持续评估你的 LLM 应用程序(请参阅下文,了解此应用程序的基础 gpt3.5 与微调 gpt3.5 的比较)。

让我们开始吧!
设置#
要运行本教程,你需要安装并启动 Argilla,以及其他一些软件包。
[ ]:
%pip install argilla openai datasets llama-index unstructured -qqq
[ ]:
# Import the needed libraries
import os
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
import openai
import argilla as rg
from argilla.feedback import TrainingTask
from argilla.feedback import ArgillaTrainer
from typing import Union, Tuple, List
from llama_index.core import ServiceContext, VectorStoreIndex, download_loader
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import DatasetGenerator
from datasets import load_dataset
如果你正在使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,则需要使用 URL 和 API_KEY 初始化 Argilla 客户端
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="https://:6900",
api_key="owner.apikey",
workspace="admin"
)
如果你正在运行私有的 Hugging Face Space,你还需要设置 HF_TOKEN,如下所示
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
[ ]:
# Your openAI key is needed for generation and fine-tuning
os.environ['OPENAI_API_KEY'] = 'sk-...'
openai.api_key = os.environ["OPENAI_API_KEY"]
启用遥测#
我们从你与我们的教程互动的方式中获得宝贵的见解。为了改进我们自己,以便为你提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为你服务。尽管这是完全匿名的,但如果你愿意,可以选择跳过此步骤。有关更多信息,请查看遥测页面。
from argilla.utils.telemetry import tutorial_running
tutorial_running()
使用 LlamaIndex 和 GPT3.5 生成响应#
我们使用关于 Argilla Cloud 的此数据集生成针对生成问题的响应。我们使用源文档和 LlamaIndex 的问题生成器生成了此数据集(有关如何生成这些问题,请参阅附录)。
如果你想跳过此过程(这将花费几分钟),我们已在 Hugging Face 上共享了结果数据集。
[ ]:
# Read our source questions
dataset = load_dataset("argilla/cloud_assistant_questions")
[ ]:
# Read and parse the document using Unstructured
UnstructuredReader = download_loader("UnstructuredReader", refresh_cache=True)
loader = UnstructuredReader()
# You can download this doc from: https://hugging-face.cn/datasets/argilla/cloud_assistant_questions/raw/main/argilla_cloud.txt
documents = loader.load_data("argilla_cloud.txt")
# Set up the Llama index context
gpt_35_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3)
)
# Index the document and set up the engine
index = VectorStoreIndex.from_documents(documents, service_context=gpt_35_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
answers = []
questions = dataset["train"]["question"]
# Inference over the questions
for question in tqdm(questions):
response = query_engine.query(question)
contexts.append([x.node.get_content() for x in response.source_nodes])
answers.append(str(response))
[ ]:
# Show an example of q, a, and context
print(f"Question: {questions[0]}")
print(f"Answer: {answers[0]}")
print(f"Context: {contexts[0]}")
Question: What is the ticketing system used by Argilla for customer support?
Answer: The ticketing system used by Argilla for customer support is not specified in the given context information.
Context: ["This process ensures the client administrator has full control over their team's access and can manage their workspace efficiently.Plans The plans for the Argilla Cloud service depend on the volume of records processed, with several tiers available to suit varying needs.Each tier has a corresponding monthly and annual price, with a 10% discount applied to the annual pricing option.The tier selection and associated price will be determined by the client's selection in the Service Order Form section of the Terms of Service document.Plans are: Starter 1 Million records Base 3 Million records Medium 4 Million records Large 6 million records\n\nSupport Argilla Cloud offers comprehensive support services to address various issues that may arise during the use of our service.Support levels are categorized into four distinct tiers, based on the severity of the issue, and a separate category for feature requests.The support process, response times, and procedures differ for each category.(1) Critical Issues Critical issues are characterized by: Severe impact on the Service, potentially rendering it completely non-functional.Disruption of critical service operations or functions.Obstruction of entire customer workflows.In the case of a critical issue, Argilla will: Assign specialist(s) to correct the issue on an expedited basis.Provide ongoing communication on the status via email and/or phone, according to the customer's preference.Begin work towards identifying a temporary workaround or fix.(2) Major Issues Major issues involve: Limited functionality of the Service.Service instability with periodic interruptions.Material service interruptions in mission-critical functions.Time-sensitive questions impacting performance or deliverables to end-clients.Upon encountering a major issue, Argilla will: Assign a specialist to begin a resolution.Implement additional, escalated procedures as reasonably determined necessary by Argilla Support Services staff.(3) Minor Issues Minor issues include: Errors causing partial, non-critical functionality loss.The need for clarification on procedures or information in documentation.Errors in service that may impact performance deliverables.(4) Trivial Issues Trivial issues are characterized by: Errors in system development with little to no impact on performance.Feature Requests Feature requests involve: Requesting a product enhancement.For feature requests, Argilla will: Respond regarding the relevance and interest in incorporating the requested feature.In summary, Argilla Cloud's support services are designed to provide timely and efficient assistance for issues of varying severity, ensuring a smooth and reliable user experience.All plans include Monday to Friday during office hours (8am to 17pm CEST) with additional support upon request.The Support Channels and features of each tier are shown below:\n\nStarter: Slack Community.Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 48 hours.Severity 4 not specified.Base: Ticketing System, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 not specified.Medium: Ticketing System and dedicated Slack channel, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 one week\n\nLarge: Ticketing System and dedicated Slack channel, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 one week.Data backup and recovery plan Argilla Cloud is committed to ensuring the safety and availability of your data.Our system is designed to run six data backups per day as a standard procedure.These backups capture a snapshot of the system state at the time of the backup, enabling restoration to that point if necessary.Our Recovery Point Objective (RPO) is four hours.This means that in the event of a system failure, the maximum data loss would be up to the last four hours of data input.We achieve this by running regular backups throughout the day, reducing the time window of potential data loss.Our Recovery Time Objective (RTO) is one hour.This is the maximum acceptable length of time that your system could be down following a failure or disruption.It represents our commitment to ensuring that your services are restored as quickly as possible.In the event of a disruption, our team will first evaluate the issue to determine the best course of action.If data recovery is necessary, we will restore from the most recent backup.We will then work to identify and resolve the root cause of the disruption to prevent a recurrence.Finally, we conduct regular test restores to ensure that our backup system is working as intended.These tests verify the integrity of the backup data and the functionality of the restore process.", "This documents an overview of the Argilla Cloud service - a comprehensive Software as a Service (SaaS) solution for data labeling and curation.The service is specifically designed to meet the needs of businesses seeking a reliable, secure, and user-friendly platform for data management.The key components of our service include advanced security measures, robust data backup and recovery protocols, flexible pricing options, and dedicated customer support.The onboarding process is efficient, enabling clients to start using the service within one business day.The scope of this proposal includes details on the aforementioned aspects, providing a clear understanding of the service offerings and associated processes.Argilla Cloud offers four plans:\n\nStarter: Ideal for teams initiating their journey in scaling data curation and labelling projects.Perfect for environments where production monitoring is not a requirement.Base: Tailored for teams seeking to amplify their data curation, labelling efforts, and model monitoring, with enhanced support from Argilla.Medium: Designed for teams expanding their language model pipelines, requiring robust ML lifecycle management fortified by Argilla's comprehensive support.Large: Geared towards teams heavily dependent on language model pipelines, human feedback, and applications, requiring complete ML lifecycle management with robust support.Scope of services Argilla Cloud, a fully managed SaaS, encompasses the following functionalities: Unrestricted Users, Datasets, and Workspaces: The service imposes no limits on the number of users, datasets, or workspaces, supporting scalability of operations.Role-Based Access Control: Administrators and annotators have differentiated access rights to ensure structured and secure data management.Custom Subdomain: Clients are provided with a distinct argilla.io subdomain for accessing the platform.Regular Updates and Upgrades: The service includes regular platform patches and upgrades as part of routine maintenance to uphold system integrity and security.Managed Service: Infrastructure maintenance, backend operations, and other technical aspects are managed by Argilla, eliminating the need for client-side management.Security The security framework of the Argilla Cloud service involves a multi-faceted approach: Data Encryption at Rest: Data stored within the system is encrypted, forming a crucial layer of security.This process automatically encrypts data prior to storage, guarding against unauthorized access.Network Security Measures: The infrastructure has been designed to prevent unauthorized intrusion and to ensure consistent service availability.Measures include firewall protections, intrusion detection systems, and scheduled vulnerability scans to detect and address potential threats.Role-Based Access Control: The system implements role-based access control, defining access levels based on user roles.This mechanism controls the extent of access to sensitive information, aligning it with the responsibilities of each role.Security Audits: Regular audits of security systems and protocols are conducted to detect potential vulnerabilities and verify adherence to security standards.Employee Training: All personnel receive regular security training, fostering an understanding of the latest threats and the importance of security best practices.Incident Response Protocol: In the case of a security incident, a pre-defined incident response plan is activated.This plan outlines the procedures for managing different types of security events, and aims to ensure swift mitigation of potential damage.In summary, the security measures in place include data encryption, network security protocols, role-based access control, regular audits, employee training, and a comprehensive incident response plan.These measures contribute to a secure environment for data management.Setup and onboarding The process for setup and onboarding for Argilla Cloud is designed to be efficient and straightforward.The procedure involves a sequence of steps to ensure a smooth transition and optimal use of the service.Step 1: Account Creation The setup process begins with the creation of the client owner account.We require the client to provide the following details: Full name of the administrator Preferred username Administrator's email address Once these details are received, we send an onboarding email to sign up.Step 2: Platform Orientation Once logged in, the administrator has full access to the Argilla Cloud platform.They can familiarize themselves with the platform interface and various features.If required, a guided tour or tutorial can be provided to walk the administrator through the platform.Step 3: User Management The administrator is then responsible for setting up additional user accounts.They can invite users via email, manage roles (admin, annotator, etc.), and assign access permissions to different workspaces and datasets.Step 4: Workspace and Dataset Configuration The administrator can create and manage multiple workspaces and datasets.They have the option to configure settings as per their team's requirements, including assigning datasets to specific workspaces and managing access permissions.Step 5: Training and Support Argilla provides open resources and support to aid in the onboarding process.This includes user manuals, tutorials, and access to our support team for any queries or issues that may arise during the setup and onboarding process.By following these steps, new users can be quickly onboarded and begin using the Argilla Cloud service with minimal downtime."]
创建 Argilla 数据集并收集反馈#
我们设置一个 Argilla 数据集,用于收集人类反馈。
为了进行微调,我们需要设置一个文本问题,以收集人工编写或编辑的响应。此数据称为完成或演示数据。
此外,利用 Argilla 的多方面反馈功能,我们设置了两个额外的反馈维度,以评估问题的相关性(因为它们是合成的,所以可能不相关或质量较差)以及从我们的检索器组件检索到的上下文的质量(可用于改进 RAG 配置)。
[ ]:
dataset = rg.FeedbackDataset(
fields=[rg.TextField(name="user-message"), rg.TextField(name="context")],
questions=[
rg.RatingQuestion(name="question-rating", title="Rate the relevance of the user question", values=[1,2,3,4,5], required=False),
rg.RatingQuestion(name="context-rating", title="Rate the quality and relevancy of context for the assistant", values=[1,2,3,4,5], required=False),
rg.TextQuestion(name="response", title="Write a helpful, harmless, accurate response to the user question"),
]
)
我们使用问题、上下文和生成的响应来构建我们的反馈记录。我们使用 suggestions 在 UI 中预填充 OpenAI 的响应,并要求我们的标注员在必要时编辑它们。
[ ]:
records = []
for question, answer, context in tqdm(zip(questions, answers, contexts), total=len(questions)):
# Instantiate the FeedbackRecord
feedback_record = rg.FeedbackRecord(
fields={"user-message": question, "context": "\n".join(context)},
suggestions=[
{
"question_name": "response",
"value": answer,
}
]
)
records.append(feedback_record)
# Publish dataset in Argilla UI
dataset = dataset.push_to_argilla(name="customer_assistant", workspace="admin")
dataset.add_records(records)
# Optional: store and version dataset in the Hub
#dataset = dataset.push_to_huggingface("argilla/rg_customer_assistant")
现在,该数据集可用于使用 Argilla UI 收集反馈。这是一个视频,展示了标注员的工作流程
准备用于微调的 Argilla 数据集#
我们现在从 Argilla 读取响应,并按照 OpenAI 指南中的微调格式 准备用于微调的数据集。
我们使用 LlamaIndex 的 TEXT_QA_PROMPT 系统提示的快速改编和来自我们的 Argilla 数据集的微调响应。
[ ]:
# Read the dataset from Argilla
dataset = rg.FeedbackDataset.from_argilla("customer_assistant", workspace="admin")
如果你跳过了之前的步骤,请运行此代码以获取预构建的数据集。
dataset = rg.FeedbackDataset.from_huggingface("argilla/customer_assistant")
[ ]:
# Adaptation from LlamaIndex's TEXT_QA_PROMPT_TMPL_MSGS[1].content
user_message_prompt ="""Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge but keeping your Argilla Cloud assistant style, answer the query.
Query: {query_str}
Answer:
"""
# Adaptation from LlamaIndex's TEXT_QA_SYSTEM_PROMPT
system_prompt = """You are an expert customer service assistant for the Argilla Cloud product that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
"""
[ ]:
def formatting_func(sample: dict) -> Union[Tuple[str, str, str, str], List[Tuple[str, str, str, str]]]:
from uuid import uuid4
if sample["response"]:
chat = str(uuid4())
user_message = user_message_prompt.format(context_str=sample["context"], query_str=sample["user-message"])
return [
(chat, "0", "system", system_prompt),
(chat, "1", "user", user_message),
(chat, "2", "assistant", sample["response"][0]["value"])
]
task = TrainingTask.for_chat_completion(formatting_func=formatting_func)
使用高质量反馈微调 GPT3.5#
我们使用 Argilla Trainer 使用导出的数据集微调 gpt-3.5-turbo。
[ ]:
trainer = ArgillaTrainer(
dataset=dataset,
task=task,
framework="openai",
)
trainer.train(output_dir="my-ft-openai-model")
使用人类偏好数据评估基础模型与微调模型#
我们设置一个新的反馈数据集,用于收集人类反馈,以使用测试数据集评估微调模型与基础模型。
有很多方法可以在此阶段收集反馈。在这种情况下,最合适的方法是人类对来自两个模型的响应的偏好数据:询问我们的标注员哪个响应最准确且最有帮助。我们可以使用 Argilla 的 RankingQuestion 轻松做到这一点。
此外,由于两个响应可能同样糟糕,我们可以要求标注员写下正确的响应。在这种情况下,我们将收集演示数据以添加到我们的微调工作流程中。
创建数据集并收集反馈#
我们设置并发布了一个新的数据集,其中包含 RankingQuestion 和 TextQuestion,向我们的标注员展示 user-message 和两个响应(来自基础模型和微调模型)。
[ ]:
dataset = rg.FeedbackDataset(
fields=[rg.TextField(name="user-message"), rg.TextField(name="response-a"), rg.TextField(name="response-b")],
questions=[
rg.RankingQuestion(name="preference", title="Which response is more helpful, harmless, and accurate.", values=["response-a", "response-b"]),
rg.TextQuestion(name="response", title="If none is good, write a helpful, harmless, accurate response to the user question", required=False),
]
)
[ ]:
# Read our test questions
questions = load_dataset("argilla/cloud_assistant_questions", split="test")["question"]
[ ]:
# Generate responses with base model
index = VectorStoreIndex.from_documents(documents, service_context=gpt_35_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
base_model_responses = []
for question in tqdm(questions):
response = query_engine.query(question)
base_model_responses.append(str(response))
[ ]:
# Generate responses with ft model: replace with the id of your ft model
ft_context = ServiceContext.from_defaults(
llm=OpenAI(model="ft:gpt-3.5-turbo-...", temperature=0.3)
)
index = VectorStoreIndex.from_documents(documents, service_context=ft_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
ft_model_responses = []
for question in tqdm(questions):
response = query_engine.query(question)
ft_model_responses.append(str(response))
这里的一个重要步骤是随机化响应的显示顺序。
如果我们始终将微调模型响应显示为第一个选项,则可能会引入位置偏差(标注员始终选择某个位置)或使用户明显看出存在两个明显不同的模型。
为了避免这种情况,我们随机化位置,并保留两个元数据字段,指示哪个模型生成了 response-a 和 response-b。在收集响应时,我们将使用此元数据将排名与每个模型进行映射。
[ ]:
records = []
for base, ft, question in zip(base_model_responses, ft_model_responses, questions):
# Randomizing the position is a highly important step to mitigate labeler biases
# Shuffle the order of base and ft
response_a, response_b = random.sample([base, ft], 2)
# Map the responses back to their model names
models = {
base: "base_model",
ft: "ft_model"
}
feedback_record = rg.FeedbackRecord(
fields={"user-message": question, "response-a": response_a, "response-b": response_b},
metadata={"response-a-model": models[response_a], "response-b-model": models[response_b]}
)
records.append(feedback_record)
dataset = dataset.push_to_argilla(name="finetuned-vs-base-preference", workspace="admin")
dataset.add_records(records)
现在,该数据集可用于使用 Argilla UI 收集反馈。这是一个视频,展示了标注员的工作流程
检索和分析响应#
我们可以动态收集来自我们标注员的响应。在这种情况下,我们将计算胜率和平局率(因为用户可以指示两个响应同样好或坏)。
对于本教程,我们只有一个用户,但 Argilla Feedback 完全是多用户的,这意味着你可以从多个用户那里收集每个数据点的反馈,从而提高评估质量。
你可以在本指南中阅读有关多用户场景和内置统一方法的更多信息。
通过非常小的评估集,我们可以看到微调模型响应在约 60% 的时间内更受欢迎,是基础模型的 3 倍,并且它们在约 20% 的时间内同样好或坏。
即使使用非常小的微调和评估数据集,这也已经显示出微调模型用于增强 RAG 系统的有希望的好处。
[ ]:
# Retrieve the dataset from Argilla
dataset = rg.FeedbackDataset.from_argilla(name="finetuned-vs-base-preference", workspace="admin")
win_rates = {
'ft_model': 0,
'base_model': 0,
'tie': 0
}
# Compute the win and tie rates
for record in dataset.records:
if len(record.responses) > 0:
for response in record.responses:
model_a = record.metadata["response-a-model"]
model_b = record.metadata["response-b-model"]
preference = response.values['preference'].value
if preference[0].rank > preference[1].rank:
win_rates[model_a] = win_rates[model_a] + 1
elif preference[1].rank > preference[0].rank:
win_rates[model_b] = win_rates[model_b] + 1
else:
win_rates['tie'] = win_rates['tie'] + 1
win_rates
# {'ft_model': 17, 'base_model': 6, 'tie': 5}
[ ]:
# Let's make the labels more explicit
data = {'gpt3.5-fine-tuned': 17, 'gpt3.5-base': 6, 'tie': 5}
total = sum(data.values())
# Calculate percentages
percentages = [value / total * 100 for value in data.values()]
# Settings
colors = ['blue', 'grey', 'black']
labels = [f"{key} ({value:.2f}%)" for key, value in zip(data.keys(), percentages)]
# Plotting
plt.figure(figsize=(12, 2))
# The cumulative percentage is used to shift the starting point of each subsequent segment
cumulative_percentages = 0
for percent, color, label in zip(percentages, colors, labels):
plt.barh('Models', percent, color=color, label=label, left=cumulative_percentages)
plt.text(cumulative_percentages + percent/2, 0, label, ha='center', va='center', color='white', fontsize=10)
cumulative_percentages += percent
plt.gca().axes.get_yaxis().set_visible(False)
plt.xlim(0, 100)
plt.title('Model Win Rates')
plt.legend(loc="upper center", bbox_to_anchor=(0.5, -0.25), ncol=3)
plt.tight_layout()
# Display
plt.show()
附录:使用 Llama Index 生成问题#
我们使用 Llama Index 的 DatasetGenerator,使用关于 Argilla Cloud 的文档生成一组问题。
[ ]:
UnstructuredReader = download_loader("UnstructuredReader", refresh_cache=True)
loader = UnstructuredReader()
# You can download this doc from: https://hugging-face.cn/datasets/argilla/cloud_assistant_questions/raw/main/argilla_cloud.txt
documents = loader.load_data("argilla_cloud.txt")
gpt_35_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.4),
chunk_size=60
)
[ ]:
question_gen_query = (
"You are customer support and sales expert of Argilla. Your task is to setup "
"a set of frequently asked questions about the Argilla Cloud service, offer and plans"
"formulate a single question that could be asked by a potential B2B client interested in Argilla Cloud "
". Restrict the question to the context information provided and don't ask general questions not related to the service and the context provided."
)
dataset_generator = DatasetGenerator.from_documents(
documents,
question_gen_query=question_gen_query,
service_context=gpt_35_context,
num_questions_per_chunk=100
)
questions = dataset_generator.generate_questions_from_nodes(num=300)