🖼️ 为监督式微调整理指令数据集#
互联网上充斥着用于微调 LLM 的开源数据集,其中一些由人类创建,另一些由生成模型生成。然而,这些数据集通常有许多有问题的和低质量的示例。通过整理它们,我们可以使微调步骤更有效率。
在本示例中,我们将演示如何复制 Argilla 社区发起的 Databricks 的 Dolly 数据集 清理工作。这将展示如何通过使用 Argilla 的反馈任务清理公共数据集来为您的微调项目构建指令数据集。
让我们开始吧!
注意
本教程是一个 Jupyter Notebook。有两种运行方式
使用此页面顶部的“在 Colab 中打开”按钮。此选项允许您直接在 Google Colab 上运行笔记本。不要忘记将运行时类型更改为 GPU 以加快模型训练和推理速度。
通过单击页面顶部的“查看源代码”链接下载 .ipynb 文件。此选项允许您下载笔记本并在本地计算机或您选择的 Jupyter 笔记本工具上运行它。
您还可以观看本教程的简化视频版本
设置#
对于本教程,您需要运行 Argilla 服务器。如果您还没有服务器,请查看我们的快速入门 或 安装 页面。完成后,完成以下步骤
使用
pip安装 Argilla 客户端和所需的第三方库
[ ]:
%pip install --upgrade argilla datasets pandas plotly -qqq
让我们进行必要的导入
[ ]:
import argilla as rg
from datasets import Dataset, load_dataset
import pandas as pd
import random
from collections import defaultdict
import plotly.express as px
如果您使用 Docker 快速入门镜像或 Hugging Face Spaces 运行 Argilla,您需要使用
URL和API_KEY初始化 Argilla 客户端。在本教程的后面,我们将需要访问 Argilla 中的用户列表,为此我们必须以所有者身份登录,而不是通常的管理员身份。请记住在 HF Spaces 或本地打开 Argilla 时以所有者身份登录。
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="https://:6900",
api_key="owner.apikey"
)
如果您正在运行私有的 Hugging Face Space,您还需要按如下方式设置 HF_TOKEN
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
启用遥测#
我们从您与教程的互动中获得宝贵的见解。为了改进我们自己,为您提供最合适的内容,使用以下代码行将帮助我们了解本教程是否有效地为您服务。虽然这是完全匿名的,但如果您愿意,可以选择跳过此步骤。有关更多信息,请查看 遥测 页面。
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
定义项目#
作为第一步,让我们加载数据集并快速浏览数据
[ ]:
data = load_dataset("argilla/databricks-dolly-15k-curated-multilingual", split="en")
[4]:
df = data.to_pandas()
df
[4]:
| instruction | context | response | category | instruction_original_en | context_original_en | response_original_en | id | |
|---|---|---|---|---|---|---|---|---|
| 0 | 维珍澳大利亚航空何时开始运营? | 维珍澳大利亚航空,维珍澳大利亚的商品名称... | 维珍澳大利亚航空于 8 月 31 日开始提供服务... | closed_qa | 维珍澳大利亚航空何时开始运营? | 维珍澳大利亚航空,维珍澳大利亚的商品名称... | 维珍澳大利亚航空于 8 月 31 日开始提供服务... | 0 |
| 1 | 哪种是鱼类? 灰鲛还是绳索 | 灰鲛 | classification | 哪种是鱼类? 灰鲛还是绳索 | 灰鲛 | 1 | ||
| 2 | 为什么骆驼可以在没有水的情况下生存很久? | 骆驼利用驼峰中的脂肪来保持它们... | open_qa | 为什么骆驼可以在没有水的情况下生存很久? | 骆驼利用驼峰中的脂肪来保持它们... | 2 | ||
| 3 | 爱丽丝的父母有三个女儿:艾米、杰斯... | 第三个女儿的名字是爱丽丝 | open_qa | 爱丽丝的父母有三个女儿:艾米、杰斯... | 第三个女儿的名字是爱丽丝 | 3 | ||
| 4 | 小森田智章何时出生? | 小森田于 7 月出生于熊本县... | 小森田智章于 1981 年 7 月 10 日出生。 | closed_qa | 小森田智章何时出生? | 小森田于 7 月出生于熊本县... | 小森田智章于 1981 年 7 月 10 日出生。 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 15010 | 我如何接受改变 | 拥抱改变并看到不同 | brainstorming | 我如何接受改变 | 拥抱改变并看到不同 | 15010 | ||
| 15011 | 什么是激光?谁创造了它? | 激光是一种通过发射光线来发光的设备... | 激光是一种从设备发射光的设备... | summarization | 什么是激光?谁创造了它? | 激光是一种通过发射光线来发光的设备... | 激光是一种从设备发射光的设备... | 15011 |
| 15012 | 公路自行车和...有什么区别? | 公路自行车旨在在沥青路面上骑行... | open_qa | 公路自行车和...有什么区别? | 公路自行车旨在在沥青路面上骑行... | 15012 | ||
| 15013 | GIS 如何帮助房地产投资... | 房地产投资者依赖于精确、准确... | general_qa | GIS 如何帮助房地产投资... | 房地产投资者依赖于精确、准确... | 15013 | ||
| 15014 | 什么是大师赛? | 大师赛是一项在...举办的高尔夫锦标赛 | general_qa | 什么是大师赛? | 大师赛是一项在...举办的高尔夫锦标赛 | 15014 |
15015 行 × 8 列
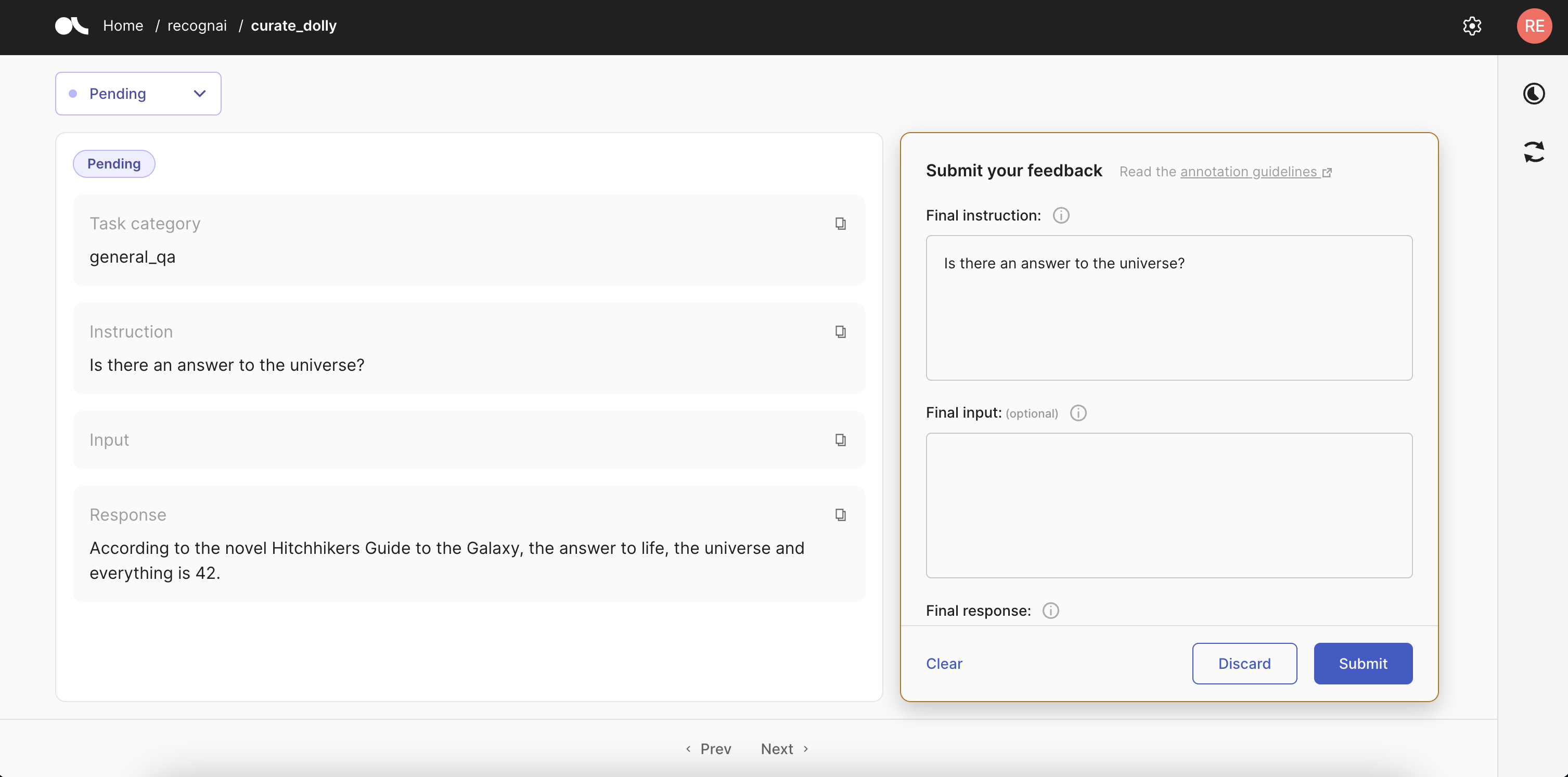
对于我们的项目,我们希望确保 instruction、context 和 response 的表述清晰简洁,并且它们提供正确的信息。我们将这些字段添加到我们的记录中。category 将帮助我们的注释员了解这些字段应该是什么样的,因此我们也会添加它。我们还可以保留 id,以便我们可以在后处理中轻松识别记录。
[57]:
# format the data as Argilla records
records = [rg.FeedbackRecord(fields={"category": record["category"], "instruction": record["instruction"], "response": record["response"], "context": record["context"]}, external_id=record['id']) for record in data]
# list of fields that we will use later for our dataset settings
fields = [
rg.TextField(name="category", title="Task category"),
rg.TextField(name="instruction"),
rg.TextField(name="context", title="Input", required=False),
rg.TextField(name="response")
]
现在我们可以考虑我们想询问有关这些记录的问题,我们将为注释员提供一些指南。
[7]:
# list of questions to display in the feedback form
questions =[
rg.TextQuestion(
name="new-instruction",
title="Final instruction:",
description="Write the final version of the instruction, making sure that it matches the task category. If the original instruction is ok, copy and paste it here.",
required=True
),
rg.TextQuestion(
name="new-input",
title="Final input:",
description="Write the final version of the input, making sure that it makes sense with the task category. If the original input is ok, copy and paste it here. If an input is not needed, leave this empty.",
required=False
),
rg.TextQuestion(
name="new-response",
title="Final response:",
description="Write the final version of the response, making sure that it matches the task category and makes sense for the instruction (and input) provided. If the original response is ok, copy and paste it here.",
required=True
)
]
guidelines = "In this dataset, you will find a collection of records that show a category, an instruction, an input and a response to that instruction. The aim of the project is to correct the instructions, input and responses to make sure they are of the highest quality and that they match the task category that they belong to. All three texts should be clear and include real information. In addition, the response should be as complete but concise as possible.\n\nTo curate the dataset, you will need to provide an answer to the following text fields:\n\n1 - Final instruction:\nThe final version of the instruction field. You may copy it using the copy icon in the instruction field. Leave it as it is if it's ok or apply any necessary corrections. Remember to change the instruction if it doesn't represent well the task category of the record.\n\n2 - Final input:\nThe final version of the instruction field. You may copy it using the copy icon in the input field. Leave it as it is if it's ok or apply any necessary corrections. If the task category and instruction don't need of an input to be completed, leave this question blank.\n\n3 - Final response:\nThe final version of the response field. You may copy it using the copy icon in the response field. Leave it as it is if it's ok or apply any necessary corrections. Check that the response makes sense given all the fields above.\n\nYou will need to provide at least an instruction and a response for all records. If you are not sure about a record and you prefer not to provide a response, click Discard."
拆分工作负载并导入到 Argilla#
对于这个特定项目,我们不希望我们的注释团队之间有任何重叠,因为我们只想要每个记录的唯一版本。我们将假设我们的团队的注释具有所需的质量,可以作为我们指令跟随模型的演示数据。
提示
为了额外的质量保证,您可以创建一个新的数据集,让注释员评估人工注释数据集的质量。
为避免一个记录有多个响应,我们将所有注释员的工作负载分开,并将分配给他们的记录导入到他们个人工作区的数据集中。
首先,让我们获取将注释此数据的用户列表。
[9]:
users = [user for user in rg.User.list() if user.role =='annotator']
当我们对用户列表感到满意时,我们可以继续进行分配
[13]:
# shuffle the records to get a random assignment
random.shuffle(records)
# build a dictionary where the key is the username and the value is the list of records assigned to them
assignments = defaultdict(list)
# divide your records in chunks of the same length as the users list and make the assignments
# you will need to follow the instructions to create and push a dataset for each of the key-value pairs in this dictionary
n = len(users)
chunked_records = [records[i:i + n] for i in range(0, len(records), n)]
for chunk in chunked_records:
for idx, record in enumerate(chunk):
assignments[users[idx].username].append(record)
for username,records in assignments.items():
# check that the user has a personal workspace and create it if not
try:
workspace = rg.Workspace.from_name(username)
except:
workspace = rg.Workspace.create(username)
user = rg.User.from_name(username)
workspace.add_user(user.id)
# create a dataset for each annotator and push it to their personal workspace
dataset = rg.FeedbackDataset(
guidelines=guidelines,
fields=fields,
questions=questions
)
dataset.add_records(records)
dataset.push_to_argilla(name='curate_dolly', workspace=workspace.name)
收集反馈并发布结果#
此时,数据集已准备好开始注释。注释完成后,我们将收集我们团队的所有反馈并将其合并到单个数据集中。
[ ]:
feedback = []
for username in assignments.keys():
feedback.extend(rg.FeedbackDataset.from_argilla('curate_dolly', workspace=username))
让我们稍微浏览一下数据集,以便我们可以得出一些关于它的结论
[53]:
responses = []
for record in feedback:
if record.responses is None or len(record.responses) == 0:
continue
# we should only have 1 response per record, so we can safely use the first one only
response = record.responses[0]
if response.status != 'submitted':
changes = []
else:
changes = []
if response.values['new-instruction'].value != record.fields['instruction']:
changes.append('instruction')
if response.values['new-input'].value != record.fields['context']:
changes.append('input')
if response.values['new-response'].value != record.fields['response']:
changes.append('response')
responses.append({'status': response.status, 'category': record.fields['category'], 'changes': ','.join(changes)})
responses_df = pd.DataFrame(responses)
responses_df = responses_df.replace('', 'None')
[ ]:
fig = px.histogram(responses_df, x='status')
fig.show()
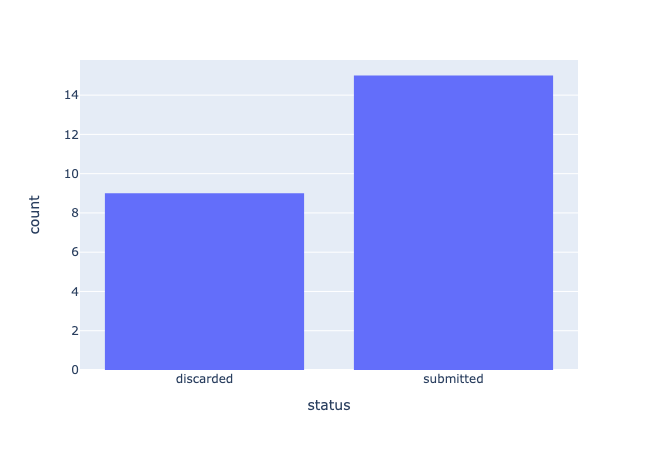
我们可以看到,大多数记录都已提交响应。这意味着我们在注释项目期间不会丢失太多数据。
提示
如果很大一部分记录有已丢弃的响应,您可以将所有已丢弃的记录提供给不同的注释员,只要您使用 Discard 按钮作为注释团队跳过记录的方式即可。
现在,让我们检查一下有多少我们提交的响应提出了对原始文本的修改
[ ]:
fig = px.histogram(responses_df.loc[responses_df['status']=='submitted'], x='changes')
fig.update_xaxes(categoryorder='total descending')
fig.update_layout(bargap=0.2)
fig.show()
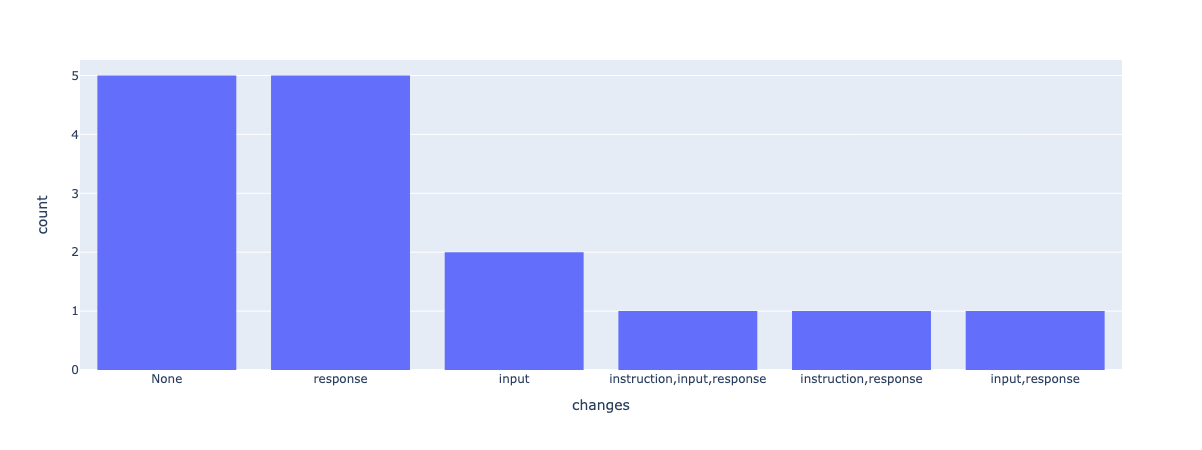
正如我们在这里看到的,很大一部分提交的响应认为记录至少需要一项修改,并且响应是最有可能被修改的字段。
我们可以按原样发布数据集,但对于本示例,我们将进行一些后处理以简化字段,并将旧的指令和响应替换为我们的注释员提供的新版本。这样,我们就拥有了一个完全准备好进行微调的数据集。
[55]:
new_records = []
for record in feedback:
if record.responses:
continue
# we should only have 1 response per record, so we can safely use the first one only
response = record.responses[0]
# we will skip records where our annotators didn't submit their feedback
if response.status != 'submitted':
continue
record.fields['instruction'] = response.values['new-instruction'].value
record.fields['context'] = response.values['new-input'].value
record.fields['response'] = response.values['new-response'].value
new_records.append(record.fields)
让我们看看它是什么样子
[56]:
new_df = pd.DataFrame(new_records)
new_df
[56]:
| category | instruction | context | response | |
|---|---|---|---|---|
| 0 | open_qa | 我如何摆脱家里的蚊子? | 您可以通过...摆脱家里的蚊子 | |
| 1 | classification | 将每个国家/地区分类为“非洲”或“欧洲”... | 尼日利亚:非洲\n卢旺达:非洲\n葡萄牙:欧... | |
| 2 | information_extraction | 从...中提取作曲家的唯一姓名 | 在某种程度上,欧洲和美国的传统... | 皮埃尔·布列兹、路易吉·诺诺、卡尔海因茨·斯托克豪森... |
| 3 | general_qa | 投资者应该择时入市吗? | 择时入市是基于对...的预测 | |
| 4 | classification | 我现在正在看我桌子上的物品,特... | Trident 薄荷糖、Macbook Pro、Pixel 3、Apple Airp... | |
| 5 | summarization | 篮球是如何发明的? | 篮球始于 1891 年在...的发明 | 篮球的发明是为了减少受伤... |
| 6 | general_qa | 宇宙有答案吗? | 根据小说《银河系漫游指南》... | |
| 7 | information_extraction | 从文章中记下国家/地区的名称... | 世界银行是一个国际金融机构... | 美国、日本、中国、德国、英国 |
| 8 | open_qa | 给我一份有史以来十大电影的清单,... | 这些是根据其 IMD...评选出的十大电影 | |
| 9 | creative_writing | 社交媒体对您有好处吗? | 关于 s 的影响存在争议... | |
| 10 | open_qa | 柚子和...有什么区别? | 柚子和葡萄柚都具有相似的柑橘... | |
| 11 | classification | 从列表中识别鸟类:仓鸮、皮特... | 仓鸮 | |
| 12 | creative_writing | 为日本之旅制定 5 天行程。 ... | 第 1 天:抵达日本中部的大阪... | |
| 13 | brainstorming | 有哪些方法可以提高您的价值? | 您可以做几件事来增加... | |
| 14 | summarization | 给我一份关于圣保罗大教堂的摘要 | 圣保罗大教堂是英国国教大教堂... | 圣保罗大教堂,伦敦的英国国教大教堂... |
现在我们对结果感到满意,我们可以将其发布到 Hugging Face Hub 中,以便整个开源社区都可以从中受益。
[ ]:
#push to hub
new_dataset = Dataset(new_records)
new_dataset.push_to_hub(".../curated_databricks-dolly-15k")
此数据集已准备好用作演示数据集,以微调指令跟随模型。
总结#
在本教程中,我们学习了如何通过整理具有宽松许可的公共数据集来创建指令数据集,在本例中,是 Databricks 员工制作的 Dolly 数据集。这可以帮助我们使用高质量的数据微调指令跟随模型,这将帮助我们通过更有效的训练获得更好的结果。